-

- 建站教程AnyCrawl产品采用多线程/多进程架构,拥有超高抓取吞吐量;内置HTTP、SOCKS代理池,可匿名绕过IP封禁,完美适配大规模批量采集任务。
爱站权重:


AnyCrawl是面向高并发场景的全功能爬虫与数据抓取工具套件,助力开发者高效、稳定采集搜索引擎结果、网页内容及全站数据。产品采用多线程/多进程架构,拥有超高抓取吞吐量;内置HTTP、SOCKS代理池,可匿名绕过IP封禁,完美适配大规模批量采集任务。
1、AnyCrawl官网入口:https://anycrawl.dev/
2、AnyCrawl开源地址:https://github.com/any4ai/AnyCrawl
AnyCrawl核心功能:
1、SERP搜索引擎爬取:
支持主流搜索引擎批量查询,输出结构化搜索结果,适配SEO分析、关键词调研等业务场景。
2、单页精准抓取:
集成Cheerio、Playwright、Puppeteer三大渲染引擎,兼顾静态HTML极速解析与JS动态页面完整渲染,保障采集数据完整可用。
3、全站深度爬取:
搭载智能遍历算法,自动发现、递归抓取全站内链,适合搭建搜索索引、竞品站点数据监控等需求。
4、AI智能数据提取:
内置大模型适配接口,可将网页非结构化内容一键转为标准JSON格式,无缝对接机器学习与数据分析流程。
5、批量任务自动化:
提供标准化RESTful API接口,配套在线Playground调试环境,可快速生成多语言代码示例,支持业务一键接入部署。
6、开源可私有化部署:
项目开源托管于GitHub,提供Docker镜像,支持本地/私有服务器一键自托管部署,满足数据安全与合规私有化要求。
AnyCrawl数据评估:
【AnyCrawl】浏览人数已经达到 次,如你需要查询该站的相关权重信息,建议直接到 5118、爱站 或 Chinaz 搜索域名「anycrawl.dev」查看最新权重、收录与关键词排名;若需精确的 IP、PV、跳出率等核心指标,仍需与站长沟通获取后台数据。总体判断时,可把访问速度、索引量、用户停留体验等因素一起纳入考量,并结合自身需求再做决策。
AnyCrawl(官网)打不开万能教程:
1、微信/QQ内打不开:
把链接复制到系统浏览器再访问,微信/QQ内置页常自动拦截第三方站。
2、浏览器报“违规”:
部分国产浏览器的误拦截,换用系统原生浏览器即可:iPhone→Safari,安卓→Edge、Alook、X、Via 等轻量浏览器,均不会误屏蔽。
3、网络加载慢或空白:
先切换 4G/5G 与 Wi-Fi 对比;可以尝试使用网络加速器,将网络切换至更稳定的运营商。另外,部分网站可能需要科学上网才能访问,如 Google、Hugging Face 等一些国外服务器的网站(不推荐)。

数据统计
特别声明&浏览提醒
本站AI工具导航站提供的「AnyCrawl」的相关内容都来源于网络,不保证外部链接的准确性和完整性。在2026年05月03日 14时36分07秒收录时,该网站上的内容都属于合规合法,后期网站的内容如出现违规,可以直接联系网站管理员(ai@ipkd.cn)进行删除,AI工具导航站不承担任何责任。在浏览网页时,请注意您的账号和财产安全,切勿轻信网上广告!
 11款免费AI翻译工具,一键开启高效翻译模式!
11款免费AI翻译工具,一键开启高效翻译模式! 6款AI视频翻译与配音工具,一键生成多语言视频
6款AI视频翻译与配音工具,一键生成多语言视频 打工人必备的6款办公室Office高效神器
打工人必备的6款办公室Office高效神器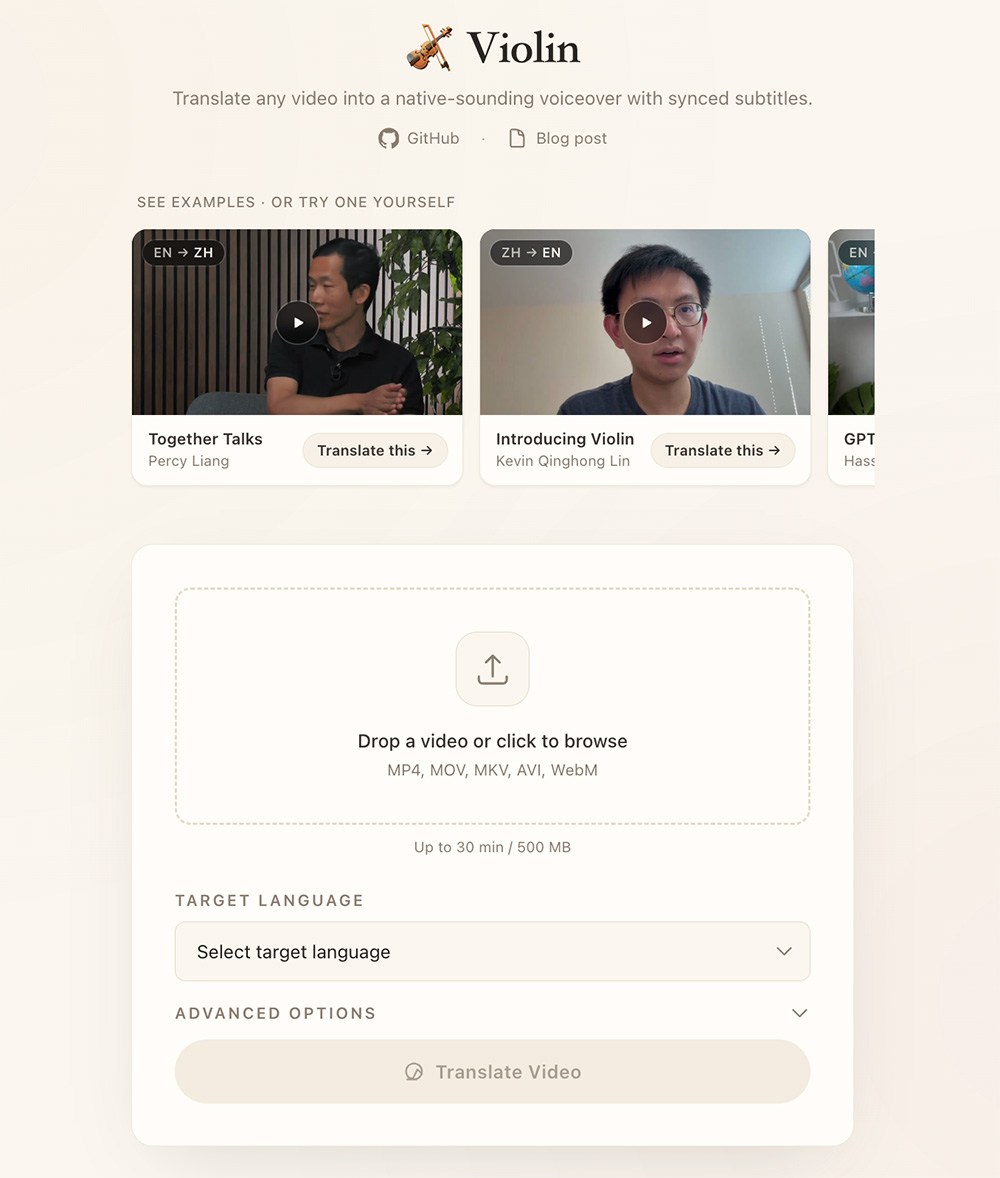 Violin – 牛津大学博士后Kevin Lin开源打造的端到端AI视频翻译配音工具
Violin – 牛津大学博士后Kevin Lin开源打造的端到端AI视频翻译配音工具 GLM-5V-Turbo基座模型官网 - 智谱AI推出的原生多模态Coding基座模型
GLM-5V-Turbo基座模型官网 - 智谱AI推出的原生多模态Coding基座模型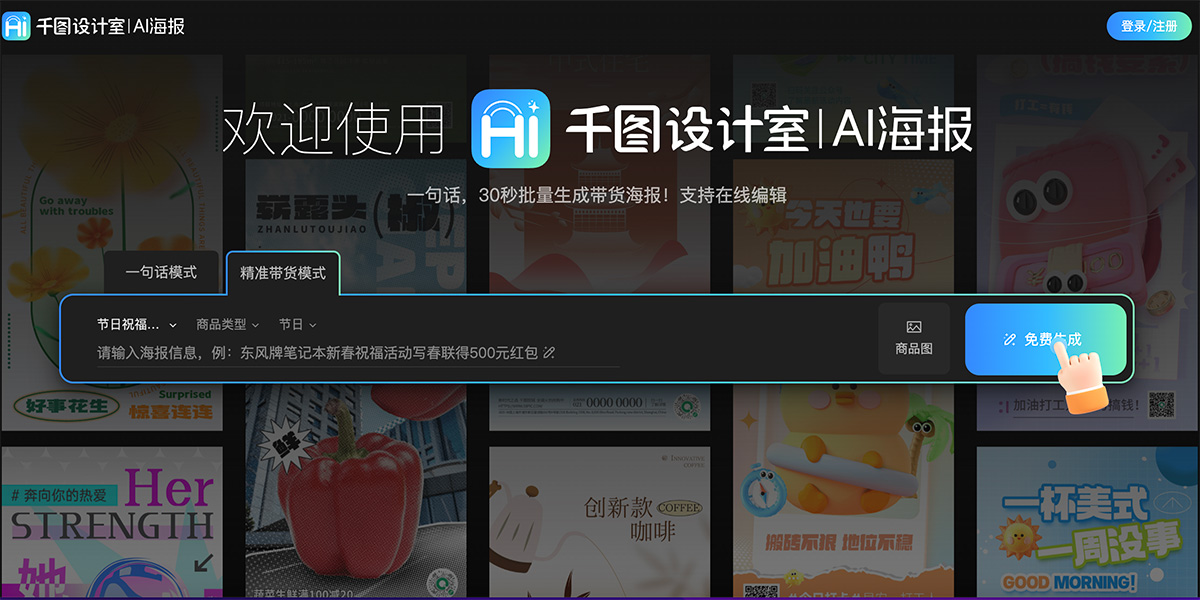 几款免费的AI海报设计工具和网站,一句话即可生成海报
几款免费的AI海报设计工具和网站,一句话即可生成海报 打工人必备!10款浏览器摸鱼插件,轻松应对工作间隙!
打工人必备!10款浏览器摸鱼插件,轻松应对工作间隙! 2025年盘点10+最佳AI编程工具与编码AI助手
2025年盘点10+最佳AI编程工具与编码AI助手 一颗翡翠玉雕盆栽树comfyui工作流
一颗翡翠玉雕盆栽树comfyui工作流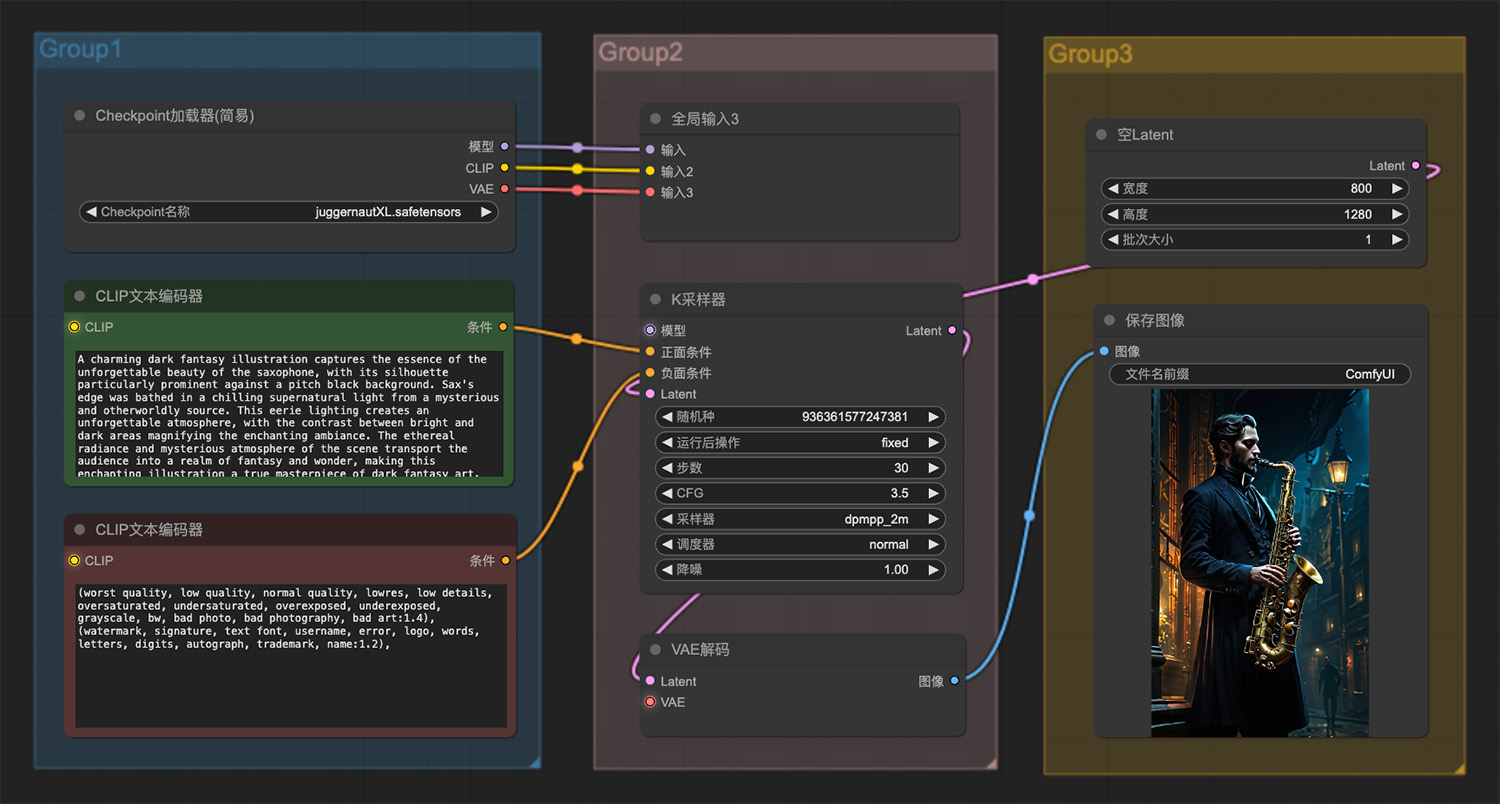 一个外国人在吹奏萨克斯ComfyUI工作流
一个外国人在吹奏萨克斯ComfyUI工作流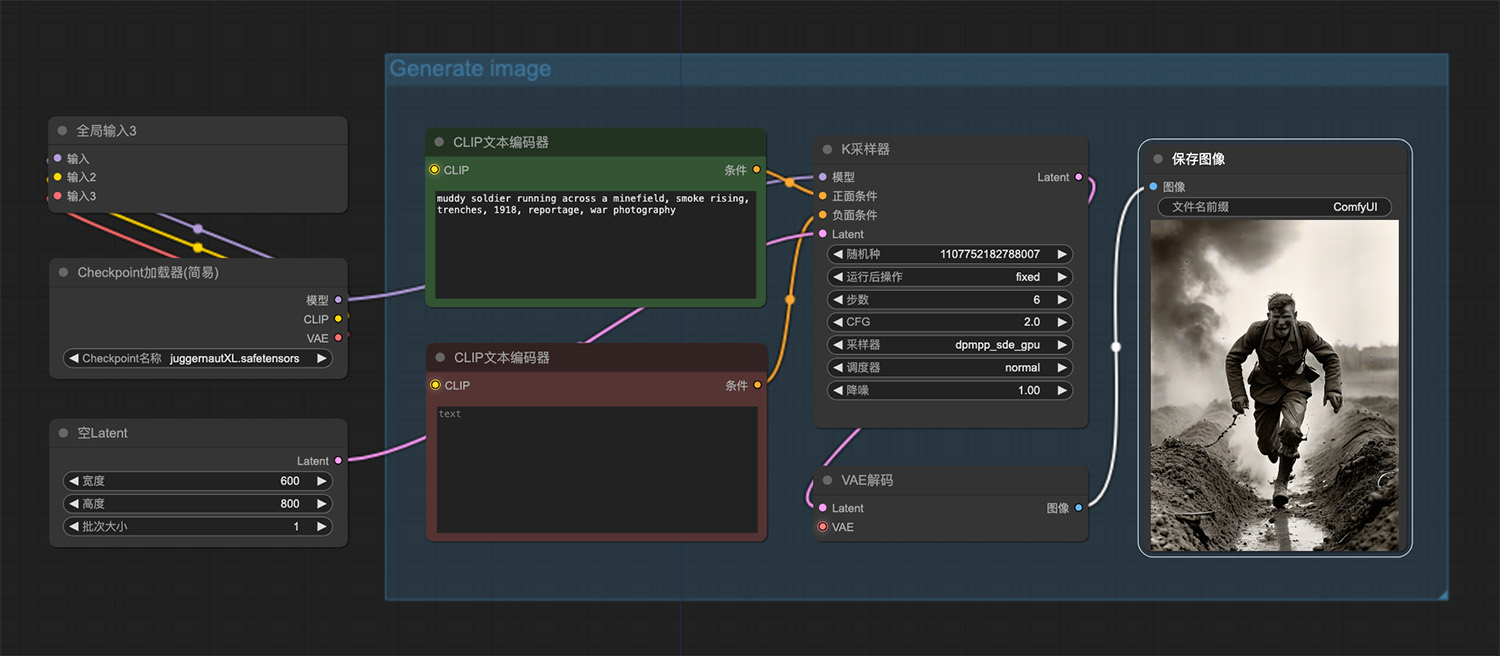 一个穿过泥泞雷区的士兵ComfyUI工作流
一个穿过泥泞雷区的士兵ComfyUI工作流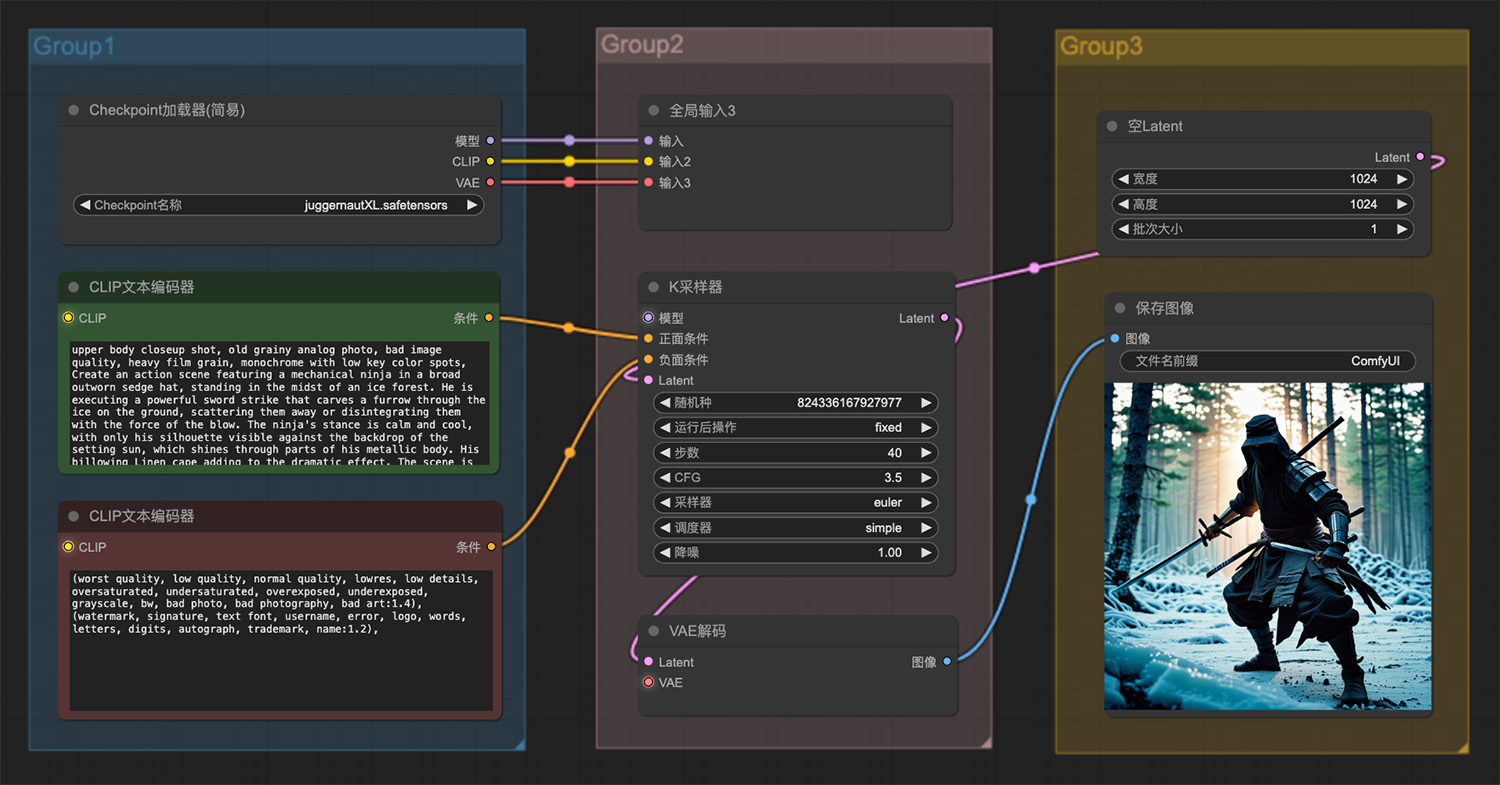 一个戴着破旧莎帽子的机械忍者站在冰林中
一个戴着破旧莎帽子的机械忍者站在冰林中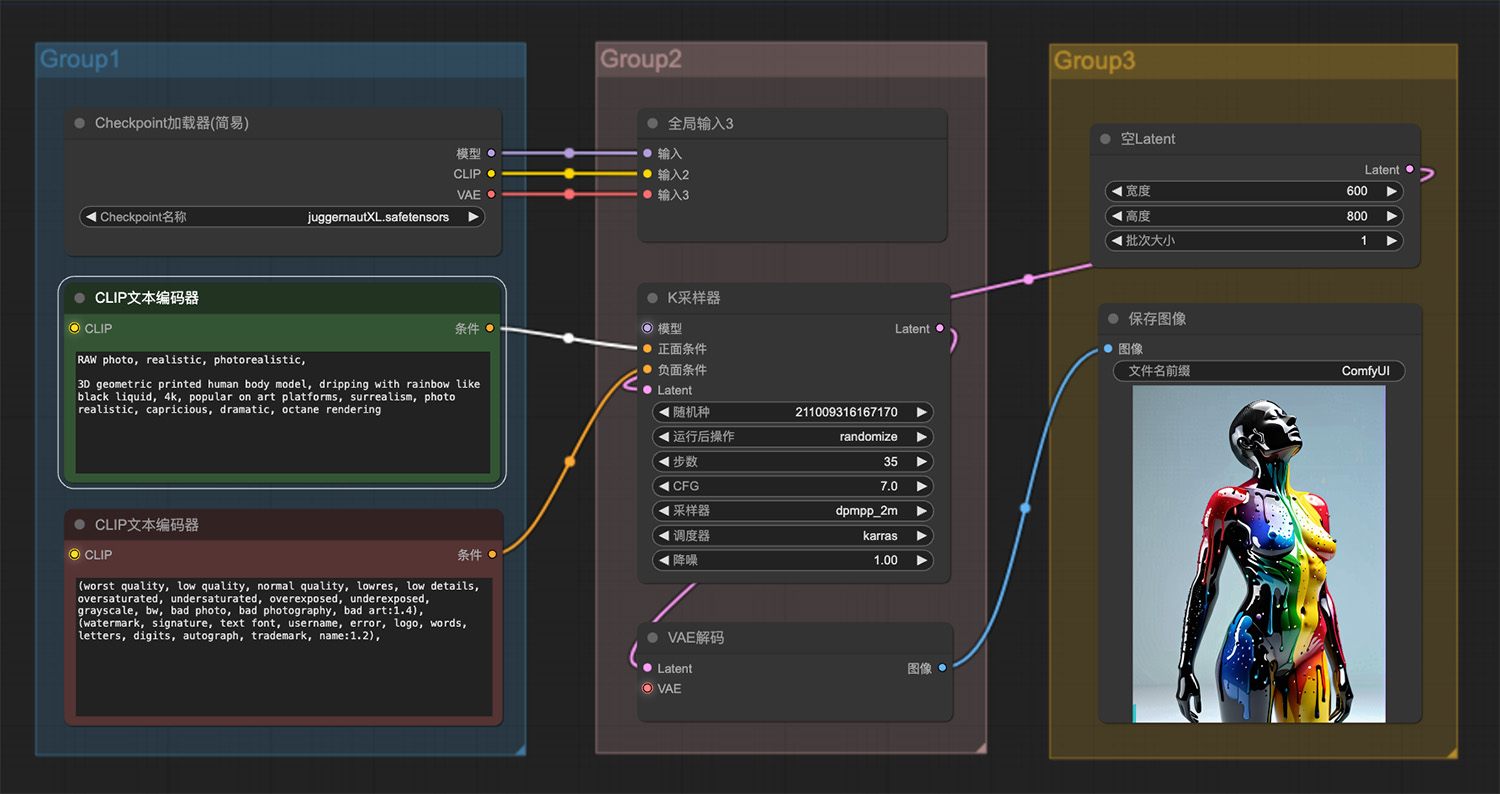 3D几何打印人体模型ComfyUI工作流
3D几何打印人体模型ComfyUI工作流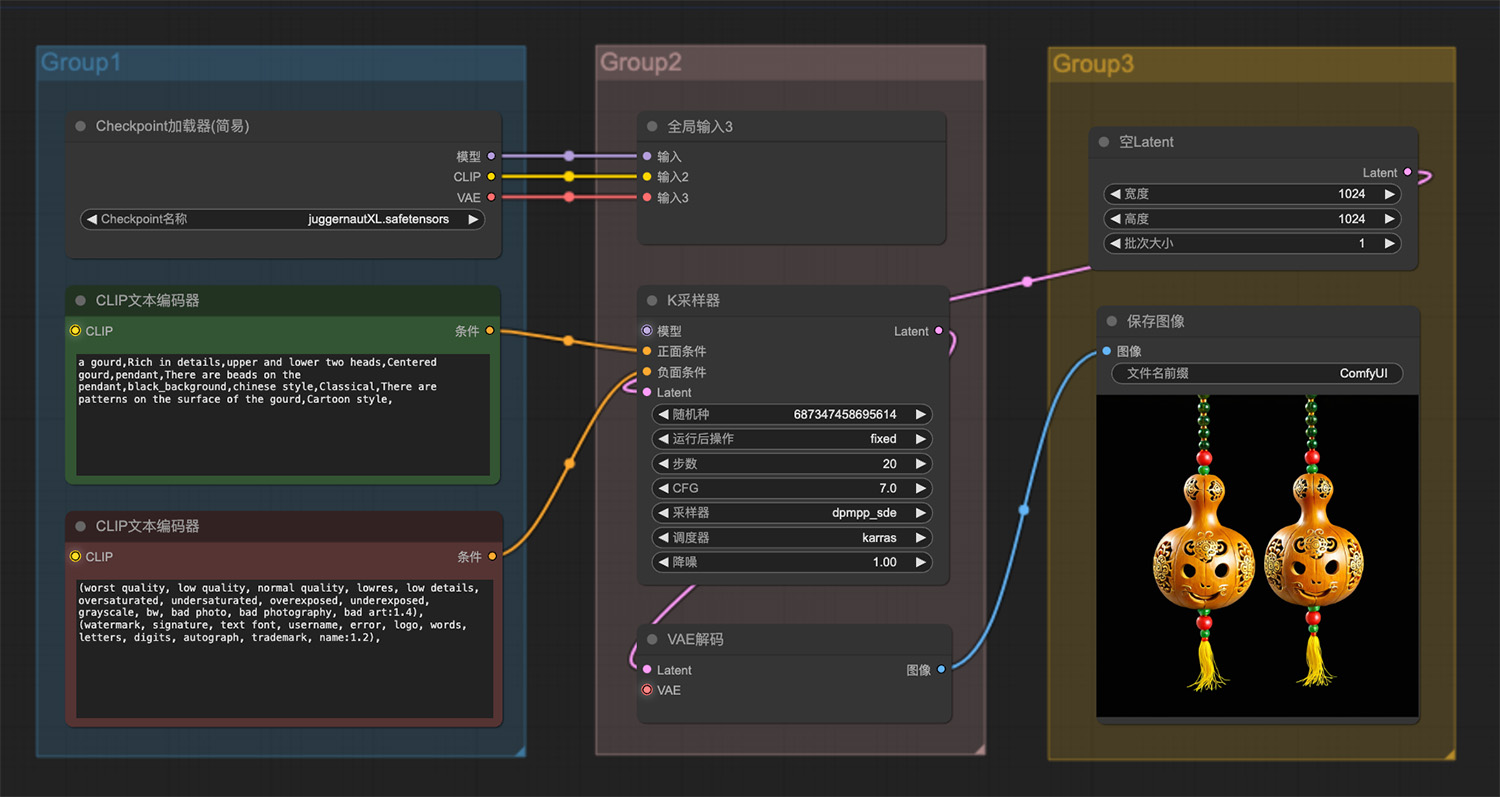 一对葫芦ComfyUI工作流
一对葫芦ComfyUI工作流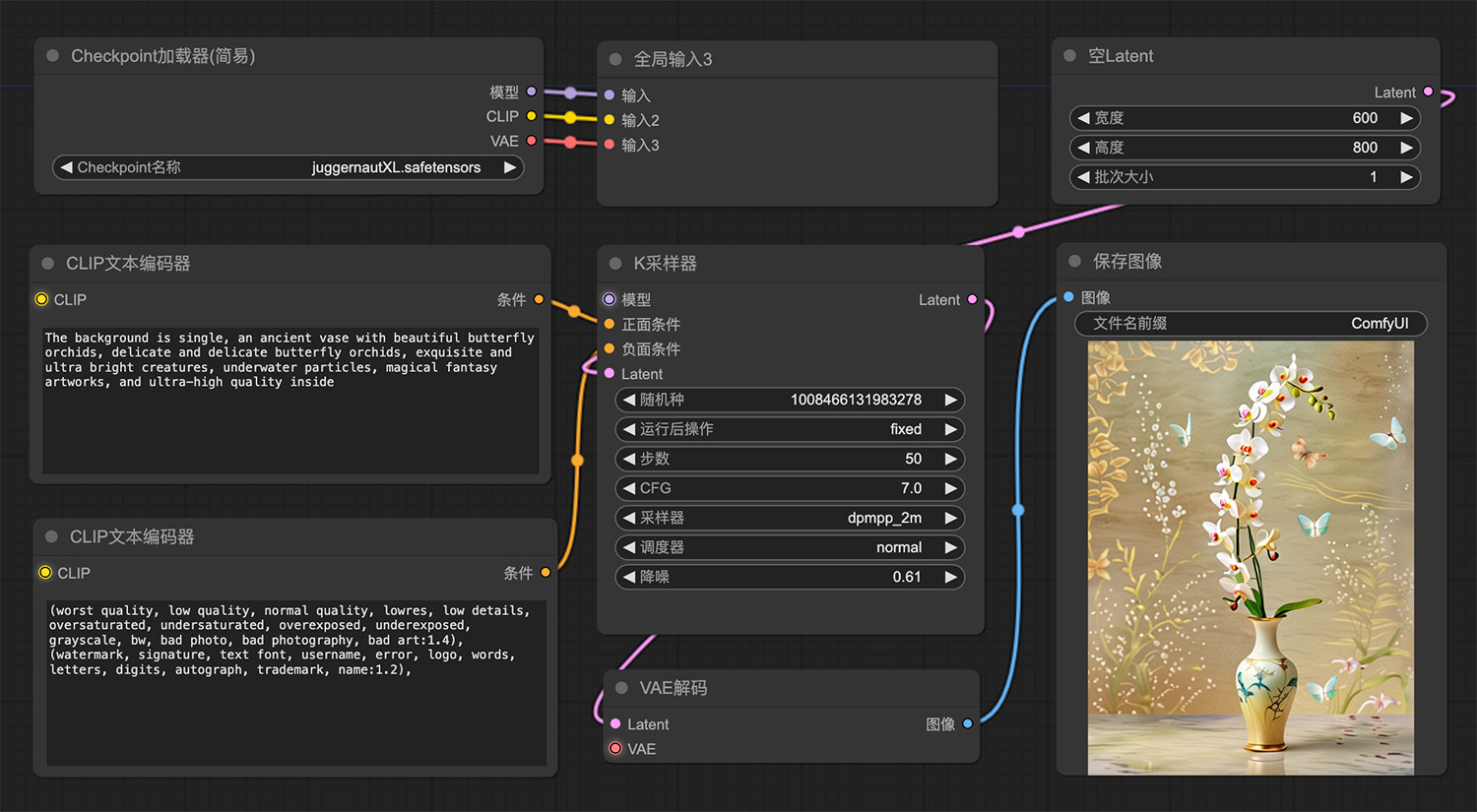 蝴蝶兰comfyui工作流
蝴蝶兰comfyui工作流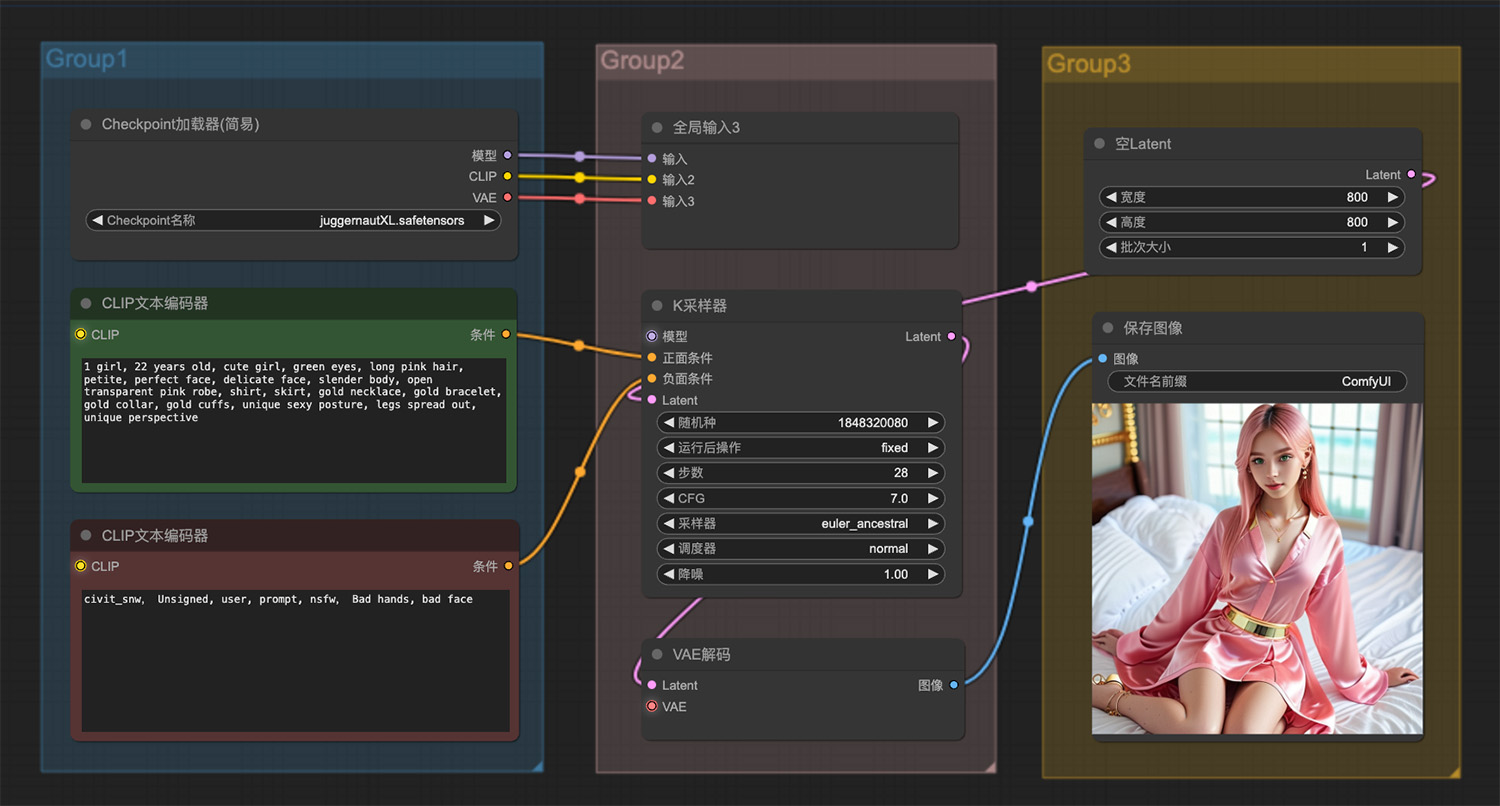 1个粉红色头发可爱的女孩ComfyUI工作流
1个粉红色头发可爱的女孩ComfyUI工作流 即梦AI绘画网页版
即梦AI绘画网页版 藏族日历小程序
藏族日历小程序
 Tesseract.js
Tesseract.js Alova.js
Alova.js Bruno
Bruno Wails
Wails Indie Tools
Indie Tools Solon
Solon
 彝族日历小程序
彝族日历小程序
 Ant Design X Vue
Ant Design X Vue 60s API
60s API ReactBits
ReactBits Element Plus X
Element Plus X How2J
How2J