-

- AI创新应用Xiaomi-MiMo-Audio小米开源的首个原生端到端语音大模型,参数规模达70亿,预训练数据超过1亿小时。
爱站权重:


Xiaomi-MiMo-Audio是小米开源的首个原生端到端语音大模型,参数规模达70亿,预训练数据超过1亿小时。该模型基于创新的预训练架构,首次在语音领域实现了基于上下文学习(ICL)的少样本泛化能力,并在预训练阶段观察到了明显的“涌现”行为。它在语音智能和音频理解基准测试中均达到了开源模型中的最佳性能(SOTA),在多项测试中超越了同参数量的开源模型、谷歌的 Gemini-2.5-Flash 以及 OpenAI 的 GPT-4o-Audio-Preview。
Xiaomi-MiMo-Audio功能特点:
1、多语言对话与自然交互:
- 支持多语言对话,能够与用户进行流畅自然的交流,无论是谈人生理想、物理知识,还是网络热梗,都能应对自如。
- 具备高度拟人化的语音对话能力,被打断后也能快速反应并继续对话。
2、语音续写与生成:
- 能够根据给定的音频提示生成连贯且适合上下文的延续,保留说话者身份、韵律和环境声音等关键声学特性。
- 可生成多种风格的语音内容,如脱口秀、朗诵、直播、辩论等。
3、少样本泛化能力:
- 首次在语音领域实现基于上下文学习的少样本泛化,即使训练数据中缺失某些任务,如语音转换、风格迁移和语音编辑,模型也能应对。
4、强大的音频理解能力:
- 具备音频字幕、音频推理和长时间音频理解功能,能够提供跨领域和场景的音频内容详细描述,并进行复杂音频内容的深入理解和分析。
- 在音频理解基准测试中,如MMAU、Big Bench Audio等,均达到了开源模型中的最佳性能。
5、技术创新与开源贡献:
- 首次证明语音无损压缩预训练扩展至1亿小时可以“涌现”出跨任务的泛化性。
- 开源了一套完整的语音预训练方案,包括无损压缩的Tokenizer、全新模型结构、训练方法和评测体系。
- 是首个将思考同时引入语音理解和语音生成过程中的开源模型,支持混合思考。
6、多场景应用:
- 可应用于多种场景,如英语口语陪练、心灵导师、游戏直播、上课、唱歌、讲脱口秀等。
Xiaomi-MiMo-Audio项目地址:
1、Xiaomi-MiMo-Audio项目官网:https://xiaomimimo.github.io/MiMo-Audio-Demo/
2、Xiaomi-MiMo-Audio Github仓库:https://github.com/XiaomiMiMo/MiMo-Audio
3、HuggingFace模型库:
MiMo-Audio-7B-Base:https://huggingface.co/XiaomiMiMo/MiMo-Audio-7B-Base
MiMo-Audio-7B-Instruct:https://huggingface.co/XiaomiMiMo/MiMo-Audio-7B-Instruct
Tokenizer:https://huggingface.co/XiaomiMiMo/MiMo-Audio-Tokenizer
4、Xiaomi-MiMo-Audio技术论文:https://github.com/XiaomiMiMo/MiMo-Audio/blob/main/MiMo-Audio-Technical-Report.pdf

数据统计
特别声明&浏览提醒
本站AI工具导航站提供的「Xiaomi-MiMo-Audio」的相关内容都来源于网络,不保证外部链接的准确性和完整性。在2025年09月19日 20时44分49秒收录时,该网站上的内容都属于合规合法,后期网站的内容如出现违规,可以直接联系网站管理员(ai@ipkd.cn)进行删除,AI工具导航站不承担任何责任。在浏览网页时,请注意您的账号和财产安全,切勿轻信网上广告!
 打工人必备!10款浏览器摸鱼插件,轻松应对工作间隙!
打工人必备!10款浏览器摸鱼插件,轻松应对工作间隙! DeepSeek:开启人工智能的深度探索之旅,解锁未来科技的无限可能!
DeepSeek:开启人工智能的深度探索之旅,解锁未来科技的无限可能! 5款AI短剧创作软件,自动剪辑,一键生成你的创意短剧!
5款AI短剧创作软件,自动剪辑,一键生成你的创意短剧! 5个免费AI漫画生成工具,一键开启漫画创作之旅!
5个免费AI漫画生成工具,一键开启漫画创作之旅! 2025年ai声音克隆哪个最好 盘点值得推荐的AI声音克隆工具2025
2025年ai声音克隆哪个最好 盘点值得推荐的AI声音克隆工具2025 6款免费AI写作神器,一键生成文章、报告、公文、论文,高效又省心!
6款免费AI写作神器,一键生成文章、报告、公文、论文,高效又省心! 8款热门AI绘画工具,国内外免费资源,轻松创作艺术佳作!
8款热门AI绘画工具,国内外免费资源,轻松创作艺术佳作! 几款免费AI 3D模型生成工具,快速制作逼真三维模型!
几款免费AI 3D模型生成工具,快速制作逼真三维模型!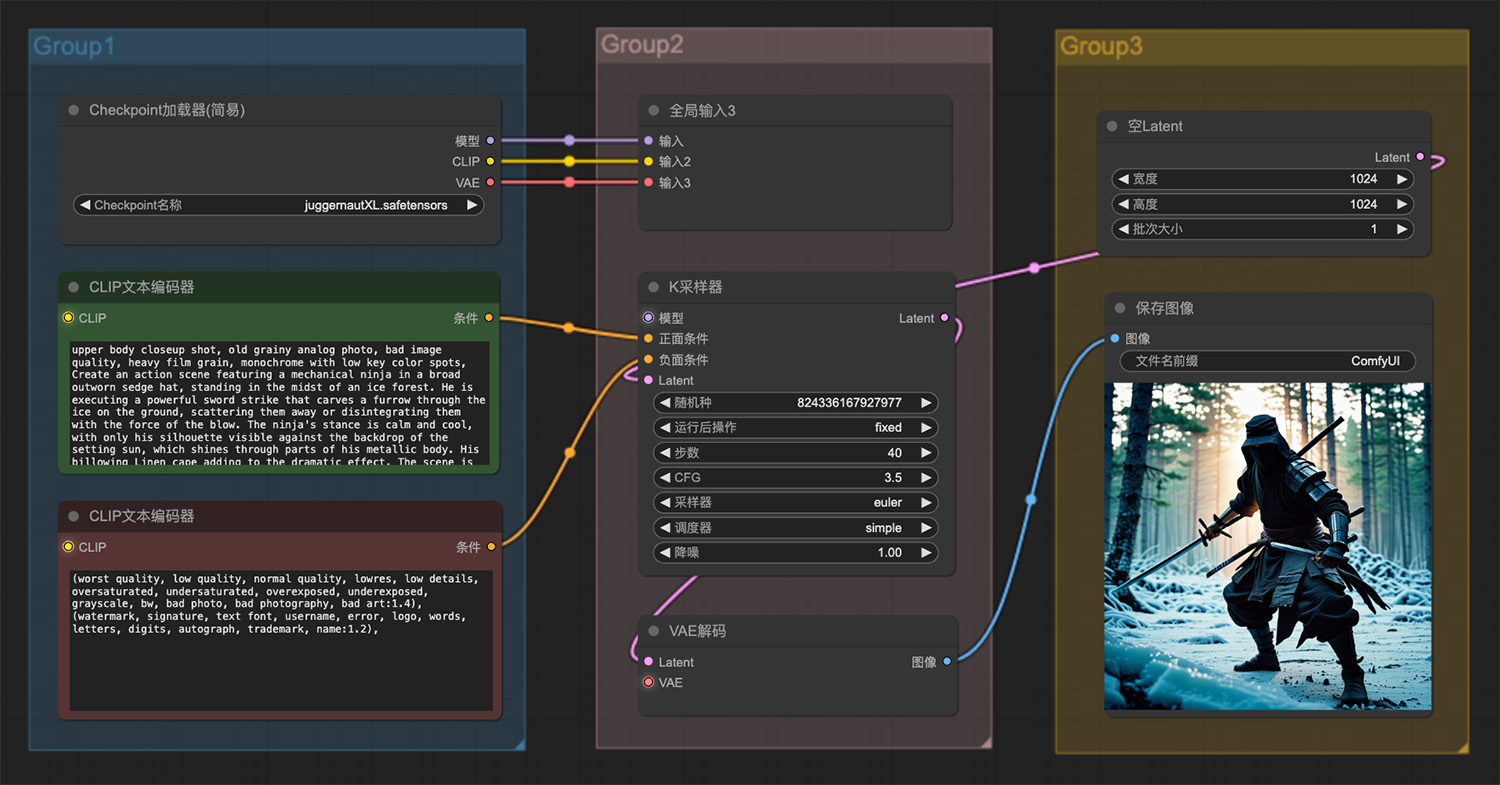 一个戴着破旧莎帽子的机械忍者站在冰林中
一个戴着破旧莎帽子的机械忍者站在冰林中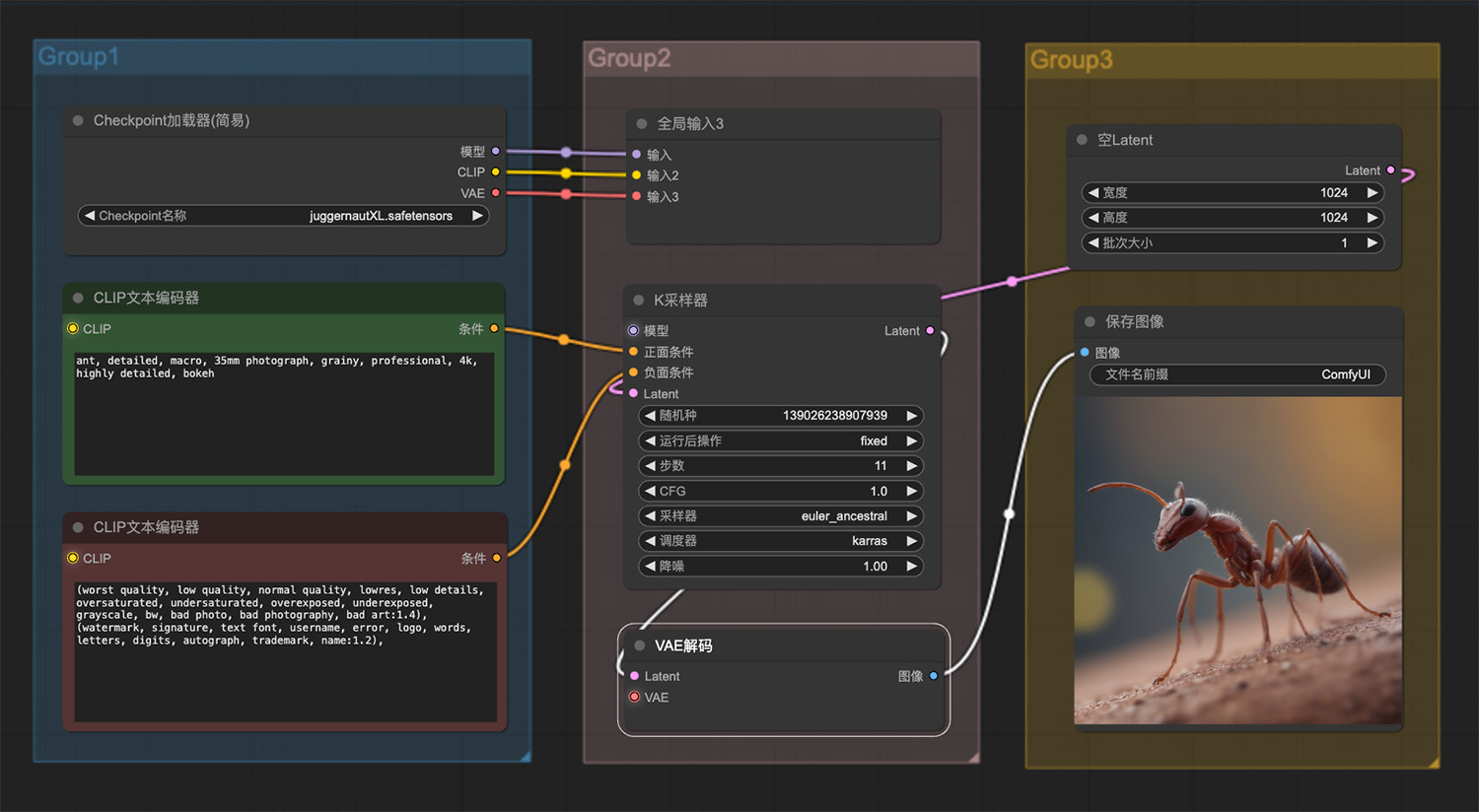 一只处于战斗状态下的蚂蚁ComfyUI工作流
一只处于战斗状态下的蚂蚁ComfyUI工作流 一只由水晶制成的蜂鸟
一只由水晶制成的蜂鸟 文生图工作流:一幅海底睡莲,碧海蓝天comfyui工
文生图工作流:一幅海底睡莲,碧海蓝天comfyui工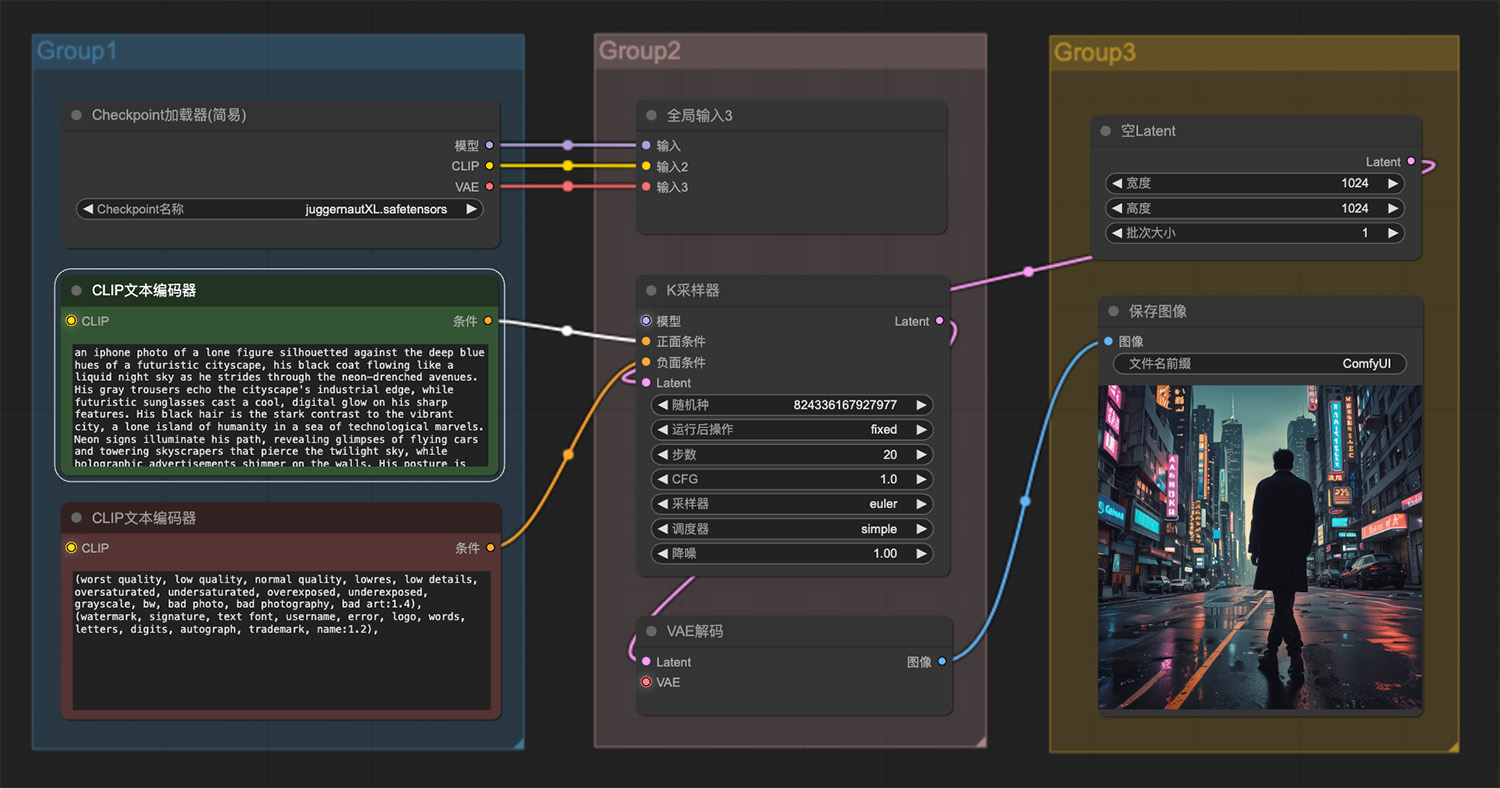 一个孤独的身影在未来主义城市
一个孤独的身影在未来主义城市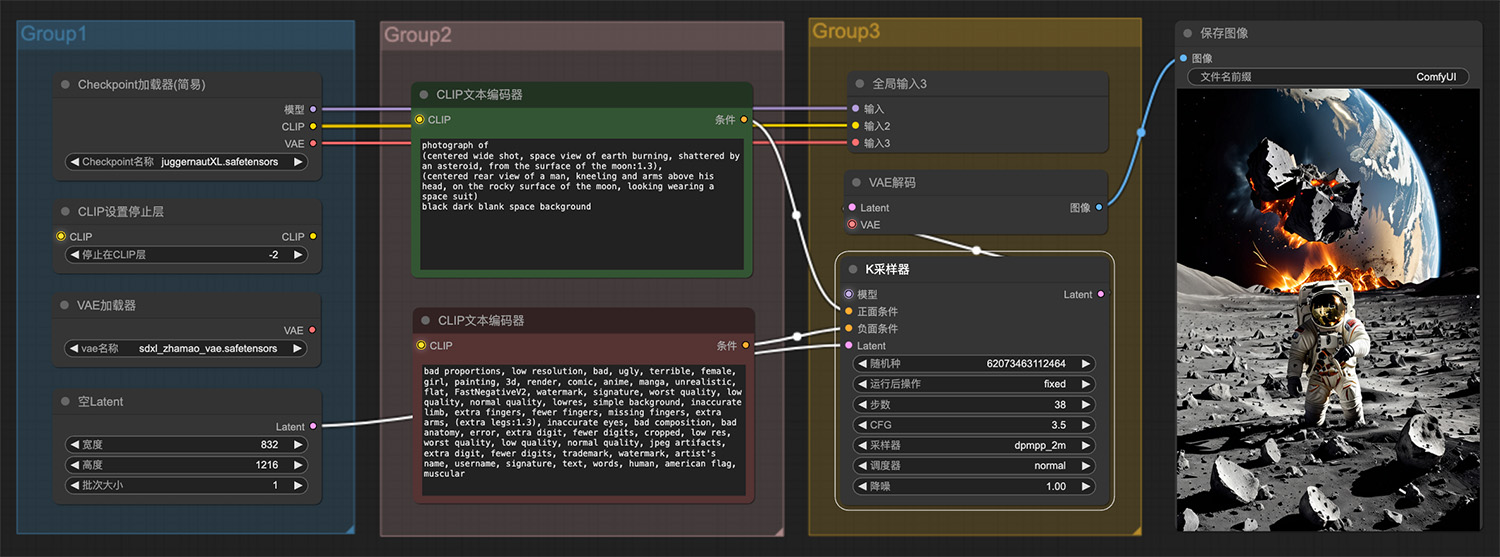 一名男子跪在月球岩石表面看见小行星碰撞
一名男子跪在月球岩石表面看见小行星碰撞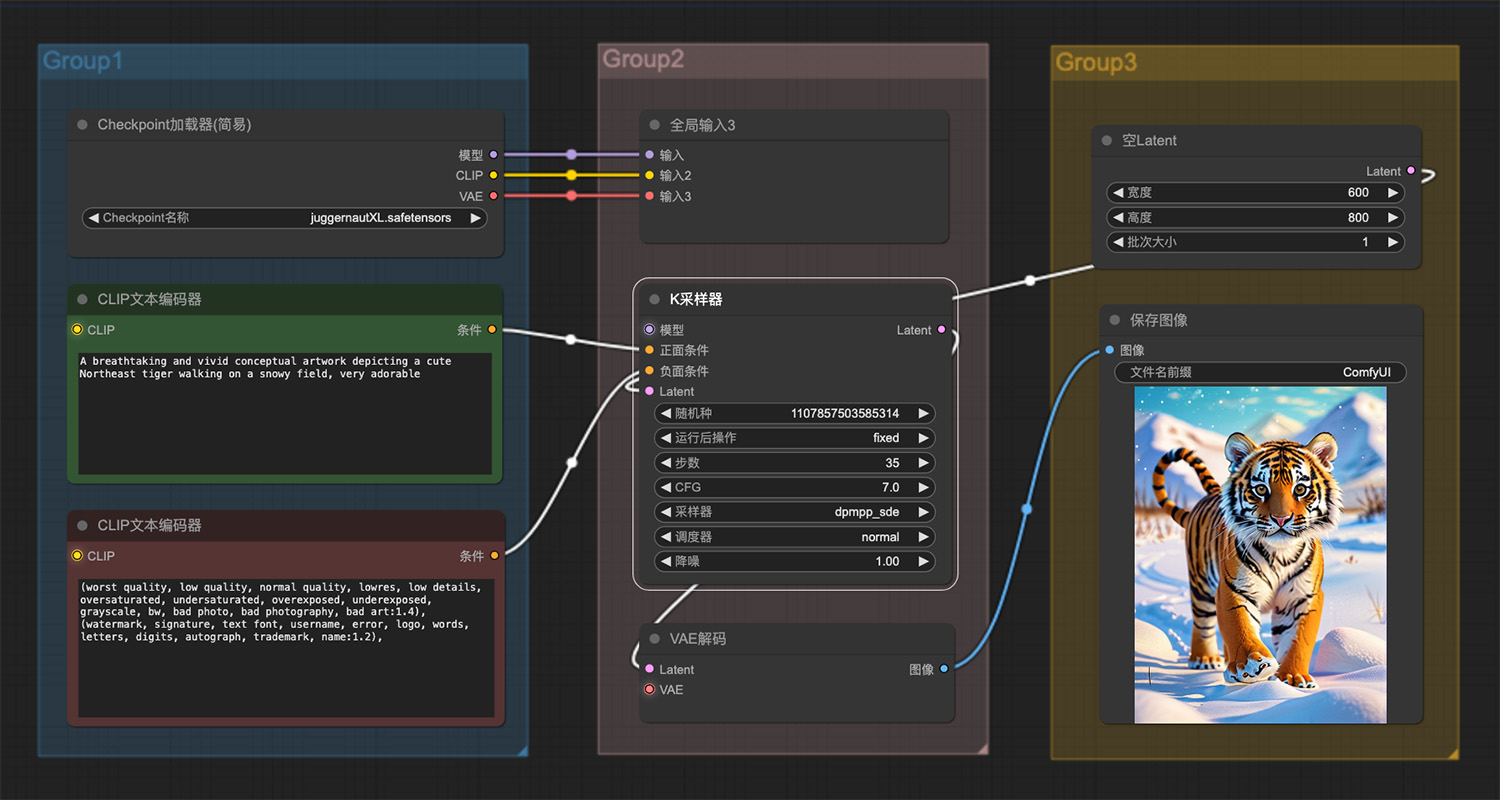 雪地里一只可爱的小老虎
雪地里一只可爱的小老虎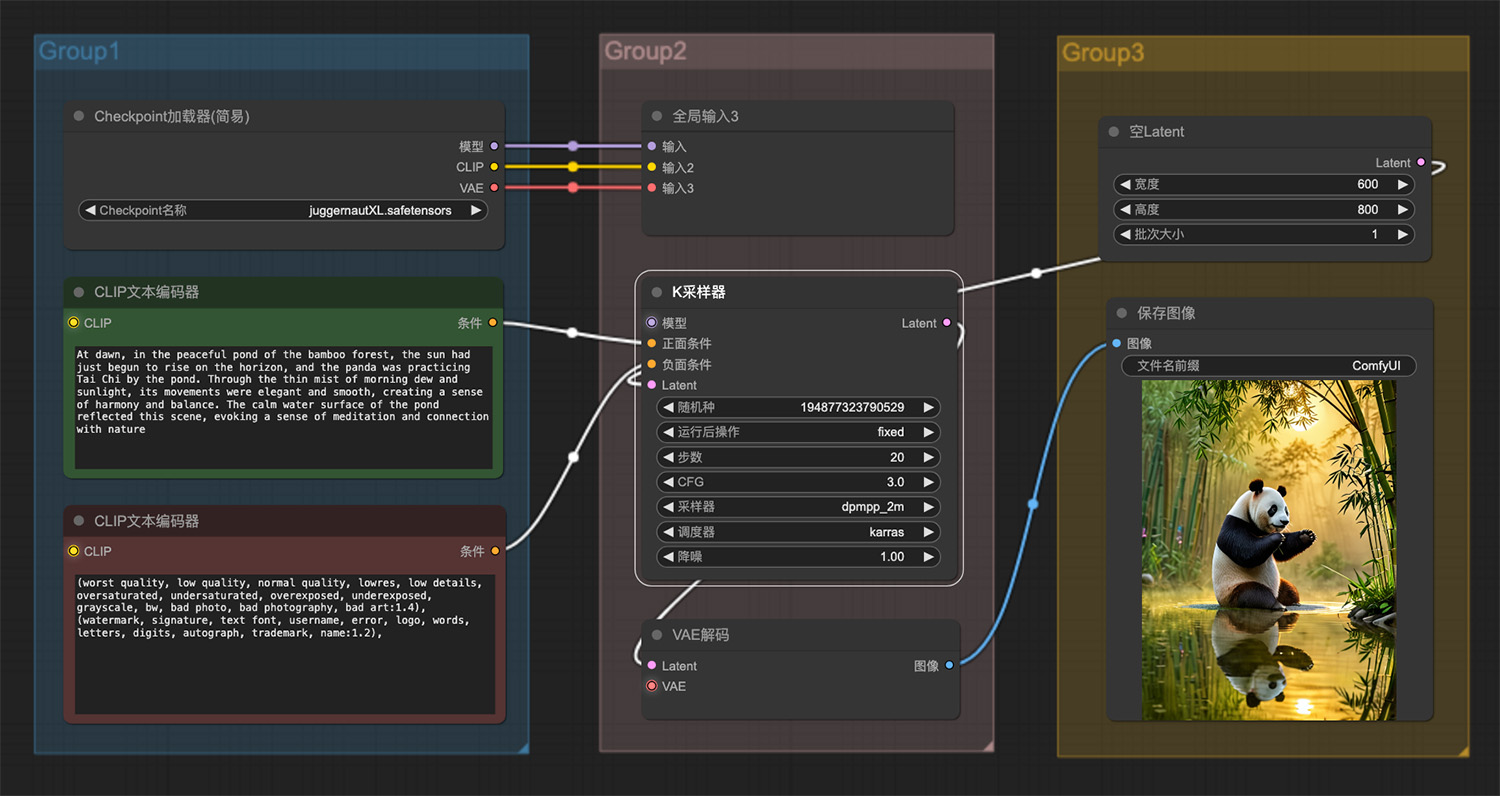 池塘边的大熊猫ComfyUI工作流
池塘边的大熊猫ComfyUI工作流 即梦AI绘画网页版
即梦AI绘画网页版 阿里·通义千问网页版
阿里·通义千问网页版 藏族日历小程序
藏族日历小程序
 Computer Use Preview
Computer Use Preview BestBlogs
BestBlogs Character Generator
Character Generator 卡兹克.skill
卡兹克.skill SEOmatic AI
SEOmatic AI
 彝族日历小程序
彝族日历小程序
 小微助手
小微助手 IFTTT
IFTTT 思想白板iThinkAir
思想白板iThinkAir RedClaw
RedClaw 云言AI智搜
云言AI智搜