-

- AI语音转换IndexTTS2支持零样本声音克隆,仅需一个音频文件即可精准复制音色、节奏和说话风格,支持多语言。
爱站权重:


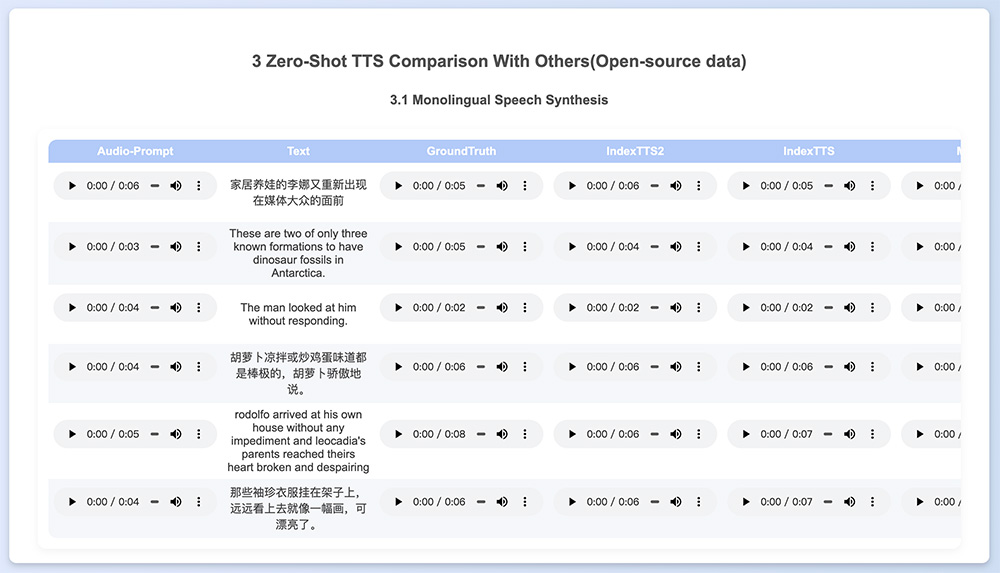
IndexTTS2是由B站(Bilibili)开发的自回归零样本语音合成模型,于2025年9月8日正式开源。IndexTTS2是首个支持精确时长控制的自回归TTS模型。支持零样本声音克隆,仅需一个音频文件即可精准复制音色、节奏和说话风格,支持多语言。IndexTTS2实现了情感音色分离控制,用户可以独立指定音色来源和情绪来源。
IndexTTS2相关网址链接:
1、项目官网:https://index-tts.github.io/index-tts2.github.io/
2、Github仓库:https://github.com/index-tts/index-tts
3、HuggingFace模型库:https://huggingface.co/IndexTeam/IndexTTS-2
4、arXiv技术论文:https://arxiv.org/pdf/2506.21619
IndexTTS2功能特点
1、精确时长控制:首次在自回归架构中实现了精准时长控制,支持两种生成模式。一种可通过明确指定生成的token数实现精确时长控制,另一种则自由生成,保持输入提示的韵律特征。这使得IndexTTS2特别适合视频配音等需严格音画同步的应用场景。
2、情感音色分离控制:实现了情感特征与说话人音色的解耦,用户可以独立指定音色来源和情绪来源。例如,可以用一段音频保留音色,再用另一段不同情感的音频或文本描述赋予情绪,在零样本条件下,模型能精准还原目标音色并完全重现指定情绪。
3、多模态情感输入:支持多种情感输入方式,包括音频情感参考、文本情感描述、情感向量精确控制等,用户可以根据需要选择合适的方式进行情感控制。
4、高情感表达下的语音清晰度提升:引入了GPT潜在表示,并设计了三阶段训练策略,增强了生成语音的稳定性和清晰度。
5、基于文本的情感控制:通过微调Qwen3模型,实现了“软指令”机制,允许用户通过自然语言描述来直观控制情绪方向,降低了使用门槛。
6、强大的技术性能:在多数据集实验中,IndexTTS2在词错率、说话人相似度和情绪保真度上均超越了当前最先进零样本TTS模型。

数据统计
特别声明&浏览提醒
本站AI工具导航站提供的「IndexTTS2」的相关内容都来源于网络,不保证外部链接的准确性和完整性。在2025年09月14日 08时14分41秒收录时,该网站上的内容都属于合规合法,后期网站的内容如出现违规,可以直接联系网站管理员(ai@ipkd.cn)进行删除,AI工具导航站不承担任何责任。在浏览网页时,请注意您的账号和财产安全,切勿轻信网上广告!
 11款免费AI翻译工具,一键开启高效翻译模式!
11款免费AI翻译工具,一键开启高效翻译模式! 打工人开工的12款办公室ai工具
打工人开工的12款办公室ai工具 多款免费AI声音克隆工具,精准复刻音色,你也可以当主播
多款免费AI声音克隆工具,精准复刻音色,你也可以当主播 盘点7款主流AI训练模型:技术特性与应用场景解析
盘点7款主流AI训练模型:技术特性与应用场景解析 CopilotKit – 开源AI原生应用前端操作系统
CopilotKit – 开源AI原生应用前端操作系统 2025年ai声音克隆哪个最好 盘点值得推荐的AI声音克隆工具2025
2025年ai声音克隆哪个最好 盘点值得推荐的AI声音克隆工具2025 5个免费AI漫画生成工具,一键开启漫画创作之旅!
5个免费AI漫画生成工具,一键开启漫画创作之旅!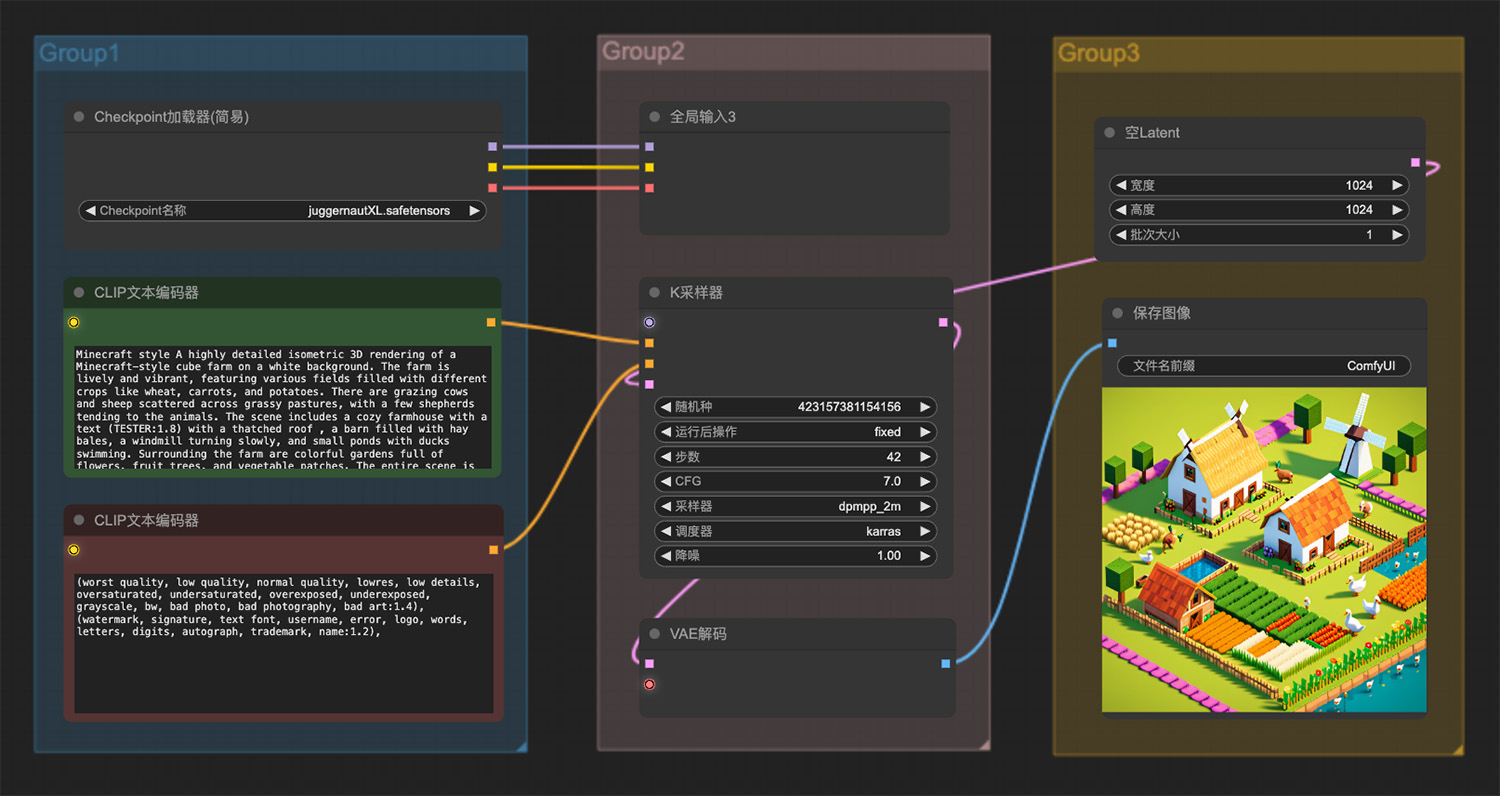 一幅3D农场游戏画面ComfyUI工作流
一幅3D农场游戏画面ComfyUI工作流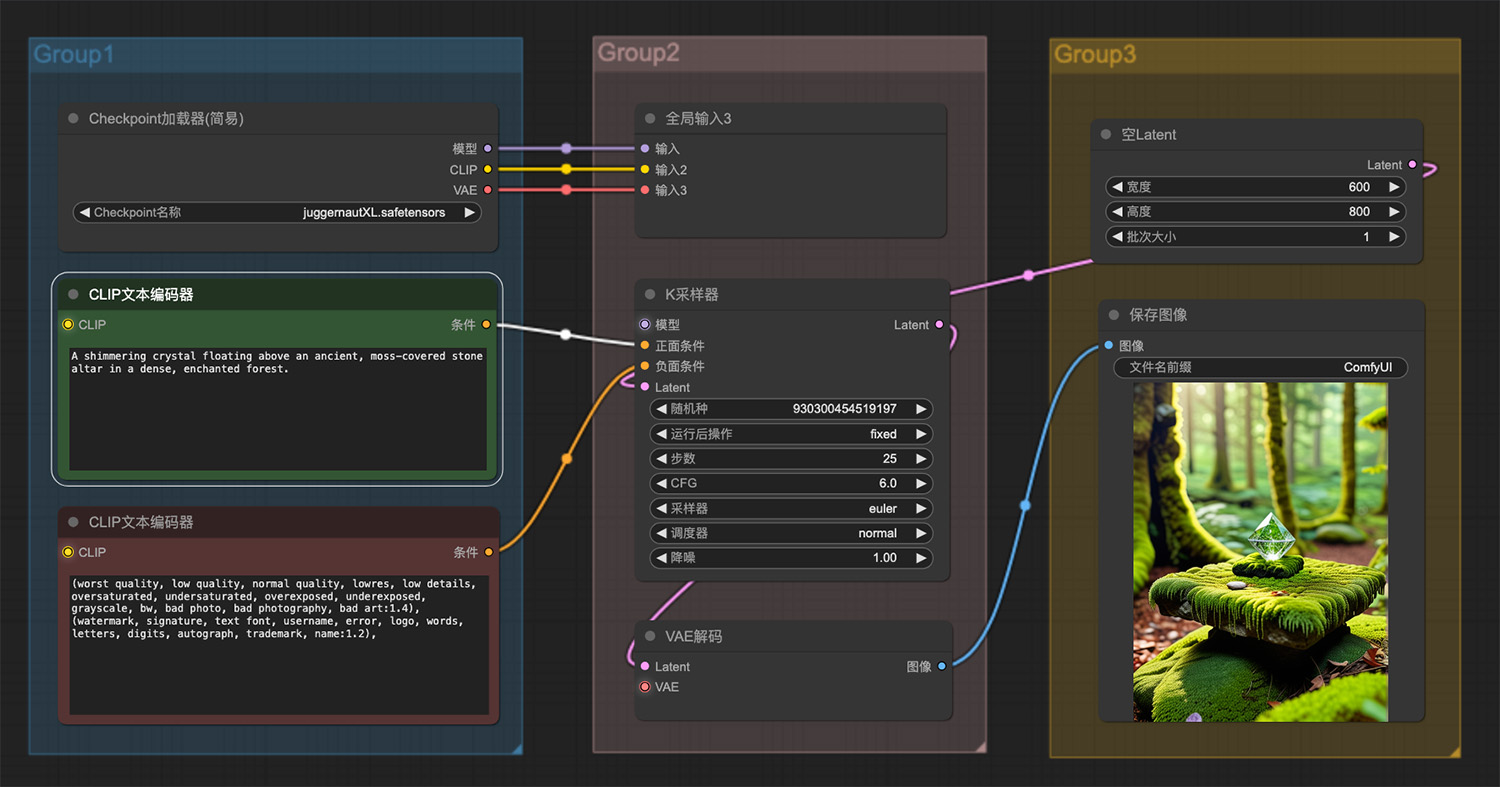 一颗闪闪发光的水晶漂浮在森林里
一颗闪闪发光的水晶漂浮在森林里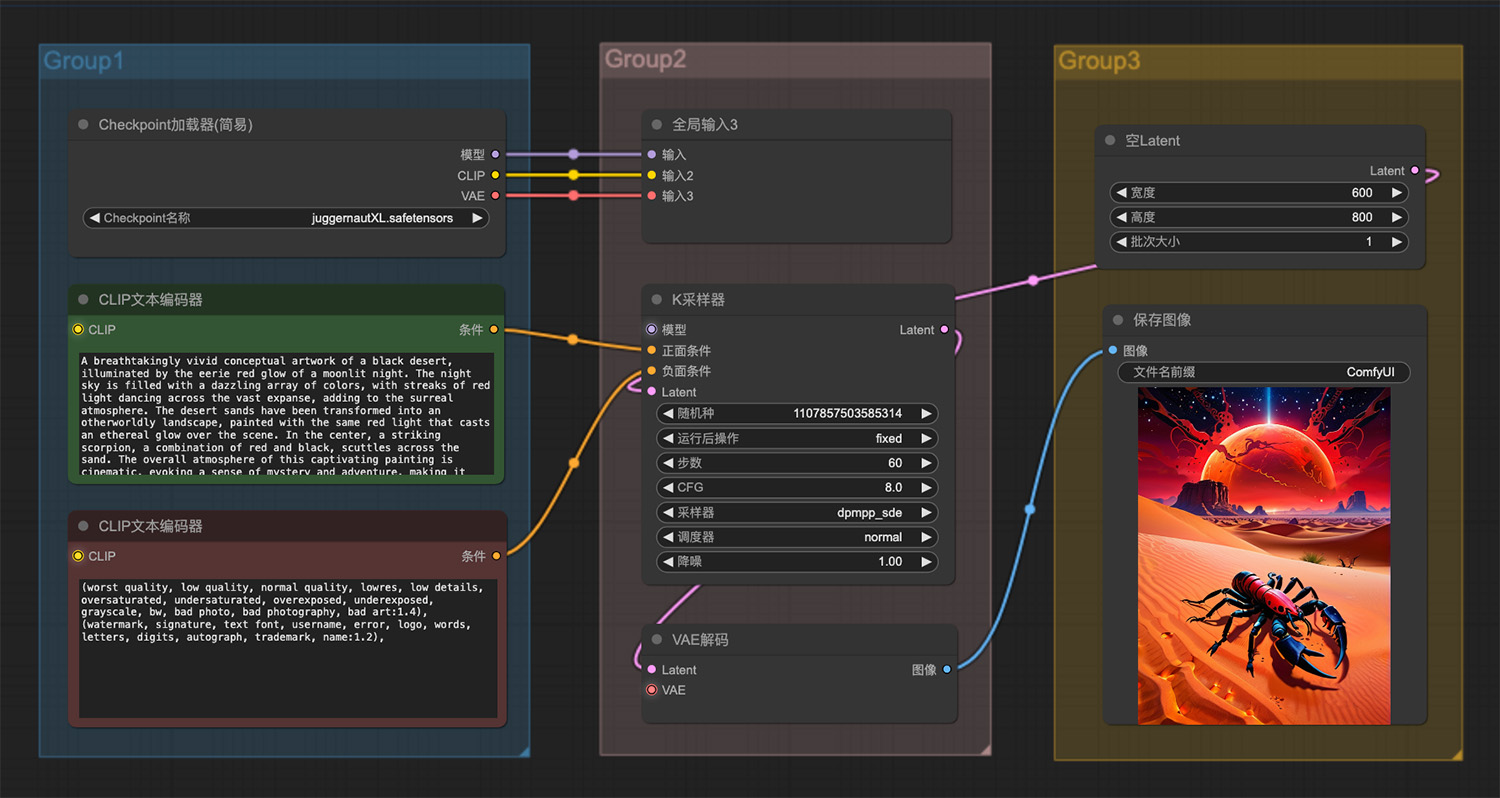 沙漠里一只红黑相间的蝎子
沙漠里一只红黑相间的蝎子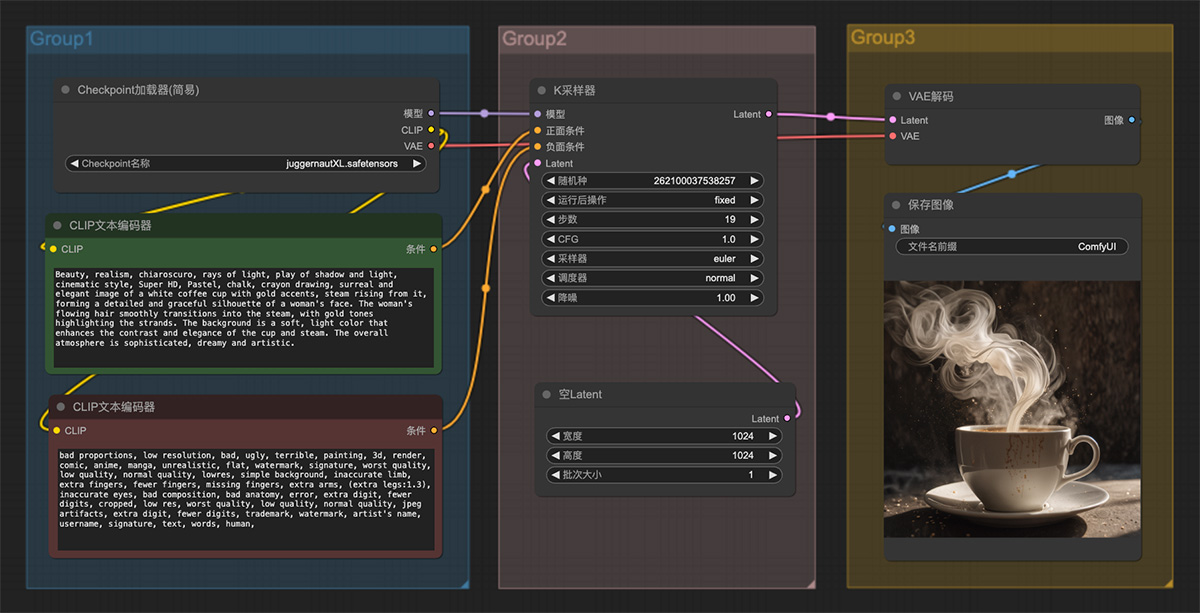 一个白色的咖啡杯,蒸汽从杯子里冒出来
一个白色的咖啡杯,蒸汽从杯子里冒出来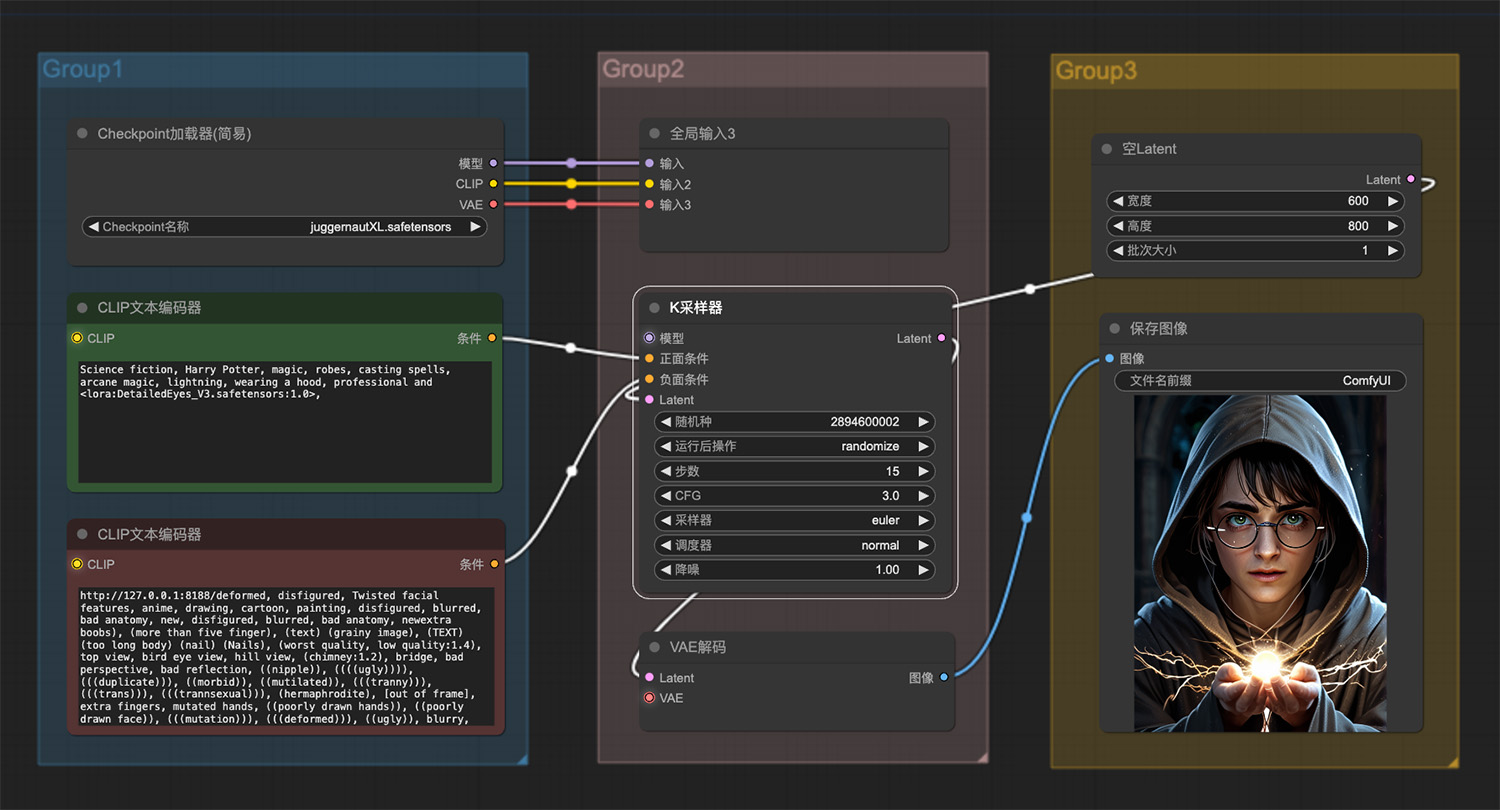 哈利波特魔法ComfyUI工作流
哈利波特魔法ComfyUI工作流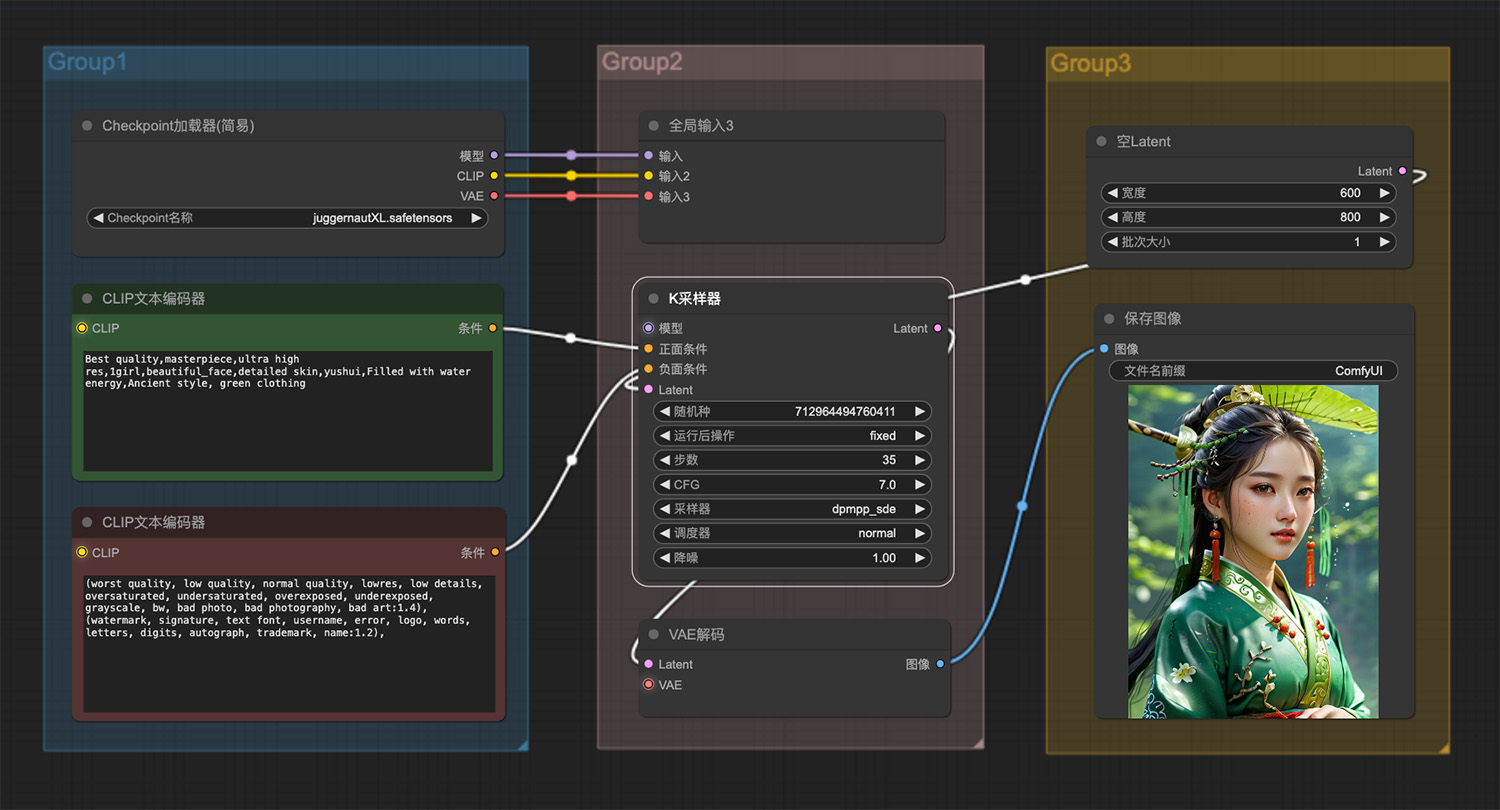 一个穿绿衣服国风古典女孩
一个穿绿衣服国风古典女孩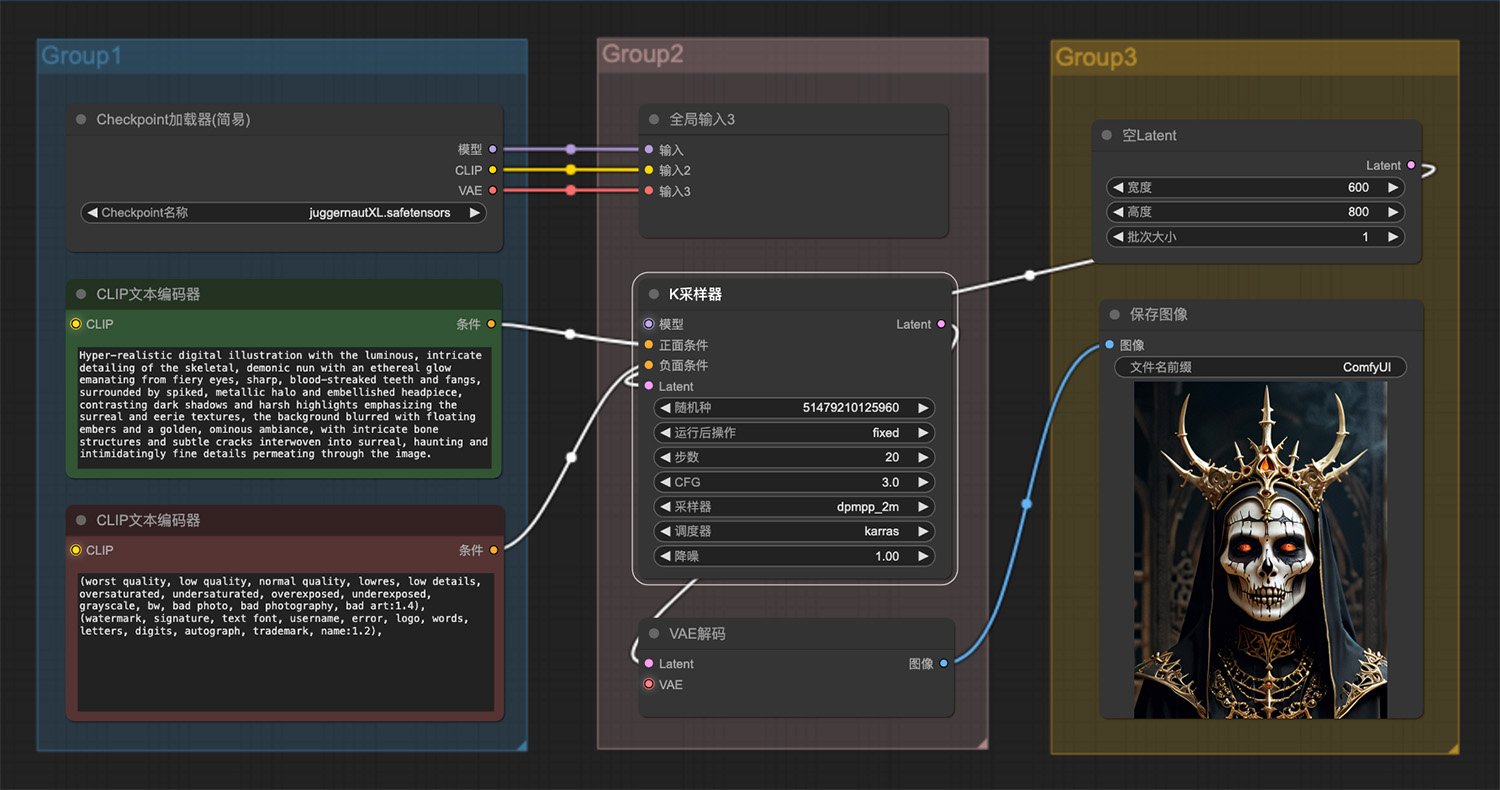 骨骼般的恶魔修女ComfyUI工作流
骨骼般的恶魔修女ComfyUI工作流 一位美丽的女士在座机上讲话ComfyUI工作流
一位美丽的女士在座机上讲话ComfyUI工作流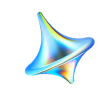 即梦AI绘画网页版
即梦AI绘画网页版 阿里·通义千问网页版
阿里·通义千问网页版 藏族日历小程序
藏族日历小程序
 NovaVSS
NovaVSS 讯飞智作
讯飞智作 妙幕SmartSub
妙幕SmartSub 知意配音
知意配音 分轨
分轨
 彝族日历小程序
彝族日历小程序
 LOVO
LOVO 自得语音
自得语音 MELO音乐
MELO音乐 Notiv
Notiv Fish Audio
Fish Audio