-

- AI创新应用女娲.skill与普通角色扮演不同,女娲.skill不追求“复活”人物本身,而是借助用户的问题,运行该人物的思维框架,且每个Skill的信息源与提炼逻辑均完全公开透明,可追溯、可验证。
爱站权重:


女娲.skill是独立开发者花叔开源的Skill工具,并非简单的AI角色扮演应用,而是一套专业的“思维蒸馏”系统。只需输入任意人名,6个Agent便会并行采集公开资料,通过三重严格验证提炼目标人物的认知操作系统,最终生成包含心智模型、决策启发式、表达DNA及诚实边界的可对话AI Skill。
女娲.skill项目GitHub地址:https://github.com/alchaincyf/nuwa-skill

女娲.skill核心功能:
1、六路并行采集:
部署6个调研Agent同步抓取目标人物的著作、深度访谈、社交媒体动态、批评视角、关键决策记录及人生时间线,全面覆盖各类公开信息源,确保信息采集的全面性与客观性。
2、三重验证提炼:
对采集到的观点执行严格筛选,仅收录同时满足“跨域复现性、问题生成力、认知排他性”三大标准的内容作为正式心智模型,保障提炼结果的专业性与准确性。
3、自动生成Skill:
系统自动输出结构化认知操作系统,包含3-7个心智模型、5-10条决策启发式、表达DNA、核心价值观与反模式,以及明确的诚实边界声明,形成完整可复用的思维框架。
4、质量验证闭环:
通过已知问题测试方向一致性、边缘问题测试推断边界、风格测试确保表达匹配,有效避免Skill出现过度自信或泛泛而谈的情况,保障输出质量。
5、主题Skill蒸馏:
可针对特定领域(如X运营),综合多位专家的方法论,提炼生成领域级认知框架,满足专业化、场景化的思维复用需求。
6、全链路透明审计:
每个Skill的references/目录完整保留一手与二手信息源、调研文件及提炼逻辑,全程可回溯、可验证,确保生成过程的透明性与可信度。
7、生态质量进化:
配套“达尔文.skill”评估体系,从8个维度对所有Skill进行批量评分与自动优化,持续提升整个Skill生态的质量水位。
女娲.skill使用步骤:
1. 安装基础环境:
确保本地已安装Anthropic的命令行编程助手Claude Code,或兼容skills.sh协议的第三方环境(如OpenClaw),为女娲.skill的部署奠定基础。
2. 一键部署女娲:
在终端执行命令`npx skills add alchaincyf/nuwa-skill`,即可将女娲.skill快速添加到Claude Code的技能库中,完成部署。
3. 发起蒸馏指令:
在Claude Code对话界面输入“蒸馏一个XXX”或“造一个关于XXX的skill”,将XXX替换为目标人物姓名或具体领域主题,启动思维蒸馏流程。
4. 全自动运行:
女娲.skill将自动调度6个Agent并行采集公开资料,依次完成提炼、验证、生成等环节,全程无需人工干预,约2-3小时后输出SKILL.md文件。
5. 直接调用Skill:
Skill生成后,可在对话中直接调用,借助目标人物的认知框架回答问题,例如“用乔布斯的视角评估这个产品”。
6. 质量复核优化(可选):
可使用配套的“达尔文.skill”,对新生成的Skill进行8维度评分,根据评估反馈手动调整参数或重新蒸馏,进一步提升Skill质量。
7. 透明审计溯源:
每个Skill的references/目录包含完整的调研文件和信息源,可随时查阅回溯,验证生成逻辑与数据依据,确保使用放心。

数据统计
特别声明&浏览提醒
本站AI工具导航站提供的「女娲.skill」的相关内容都来源于网络,不保证外部链接的准确性和完整性。在2026年04月27日 19时20分54秒收录时,该网站上的内容都属于合规合法,后期网站的内容如出现违规,可以直接联系网站管理员(ai@ipkd.cn)进行删除,AI工具导航站不承担任何责任。在浏览网页时,请注意您的账号和财产安全,切勿轻信网上广告!
 2025年ai声音克隆哪个最好 盘点值得推荐的AI声音克隆工具2025
2025年ai声音克隆哪个最好 盘点值得推荐的AI声音克隆工具2025 打工人必备!10款浏览器摸鱼插件,轻松应对工作间隙!
打工人必备!10款浏览器摸鱼插件,轻松应对工作间隙! 6款免费AI写作神器,一键生成文章、报告、公文、论文,高效又省心!
6款免费AI写作神器,一键生成文章、报告、公文、论文,高效又省心! 8款热门AI绘画工具,国内外免费资源,轻松创作艺术佳作!
8款热门AI绘画工具,国内外免费资源,轻松创作艺术佳作! DeepSeek:开启人工智能的深度探索之旅,解锁未来科技的无限可能!
DeepSeek:开启人工智能的深度探索之旅,解锁未来科技的无限可能! 5个免费AI漫画生成工具,一键开启漫画创作之旅!
5个免费AI漫画生成工具,一键开启漫画创作之旅! 几款免费AI 3D模型生成工具,快速制作逼真三维模型!
几款免费AI 3D模型生成工具,快速制作逼真三维模型! 5款AI短剧创作软件,自动剪辑,一键生成你的创意短剧!
5款AI短剧创作软件,自动剪辑,一键生成你的创意短剧! 一只由水晶制成的蜂鸟
一只由水晶制成的蜂鸟 文生图工作流:一幅海底睡莲,碧海蓝天comfyui工
文生图工作流:一幅海底睡莲,碧海蓝天comfyui工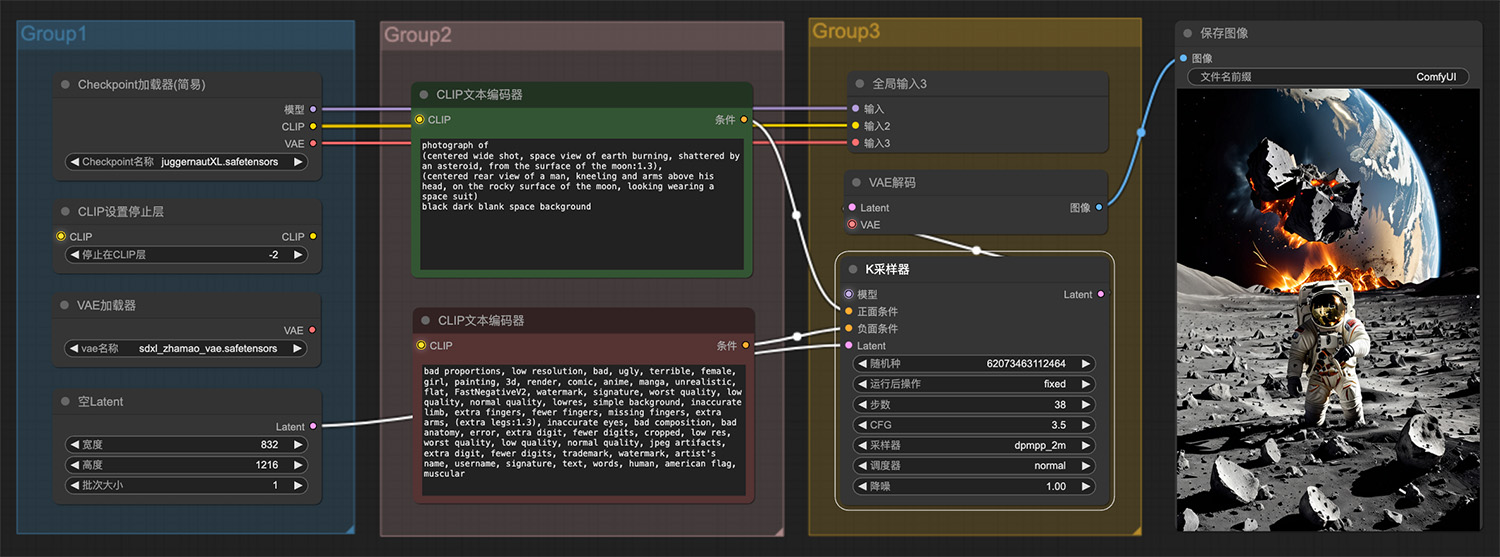 一名男子跪在月球岩石表面看见小行星碰撞
一名男子跪在月球岩石表面看见小行星碰撞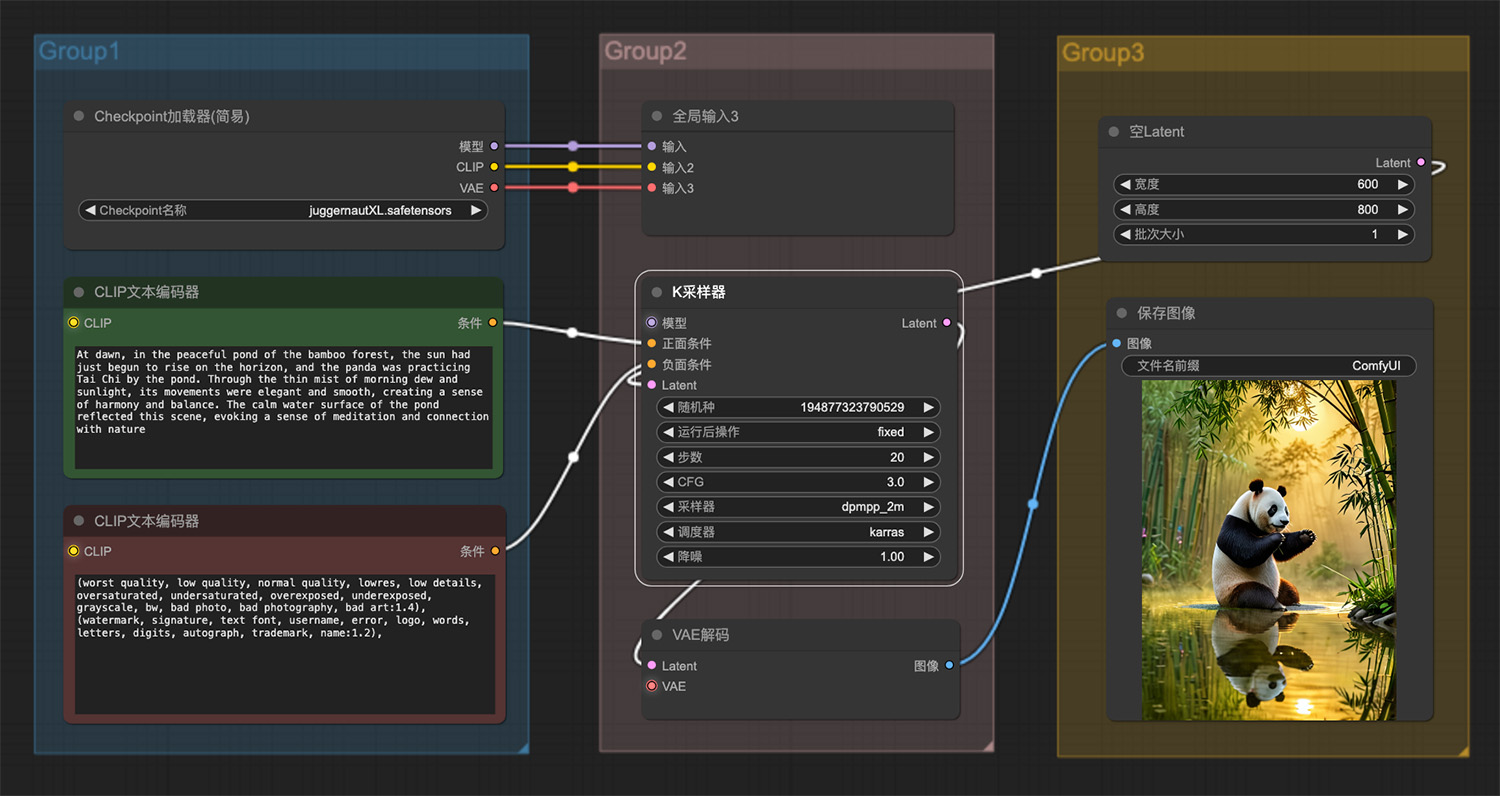 池塘边的大熊猫ComfyUI工作流
池塘边的大熊猫ComfyUI工作流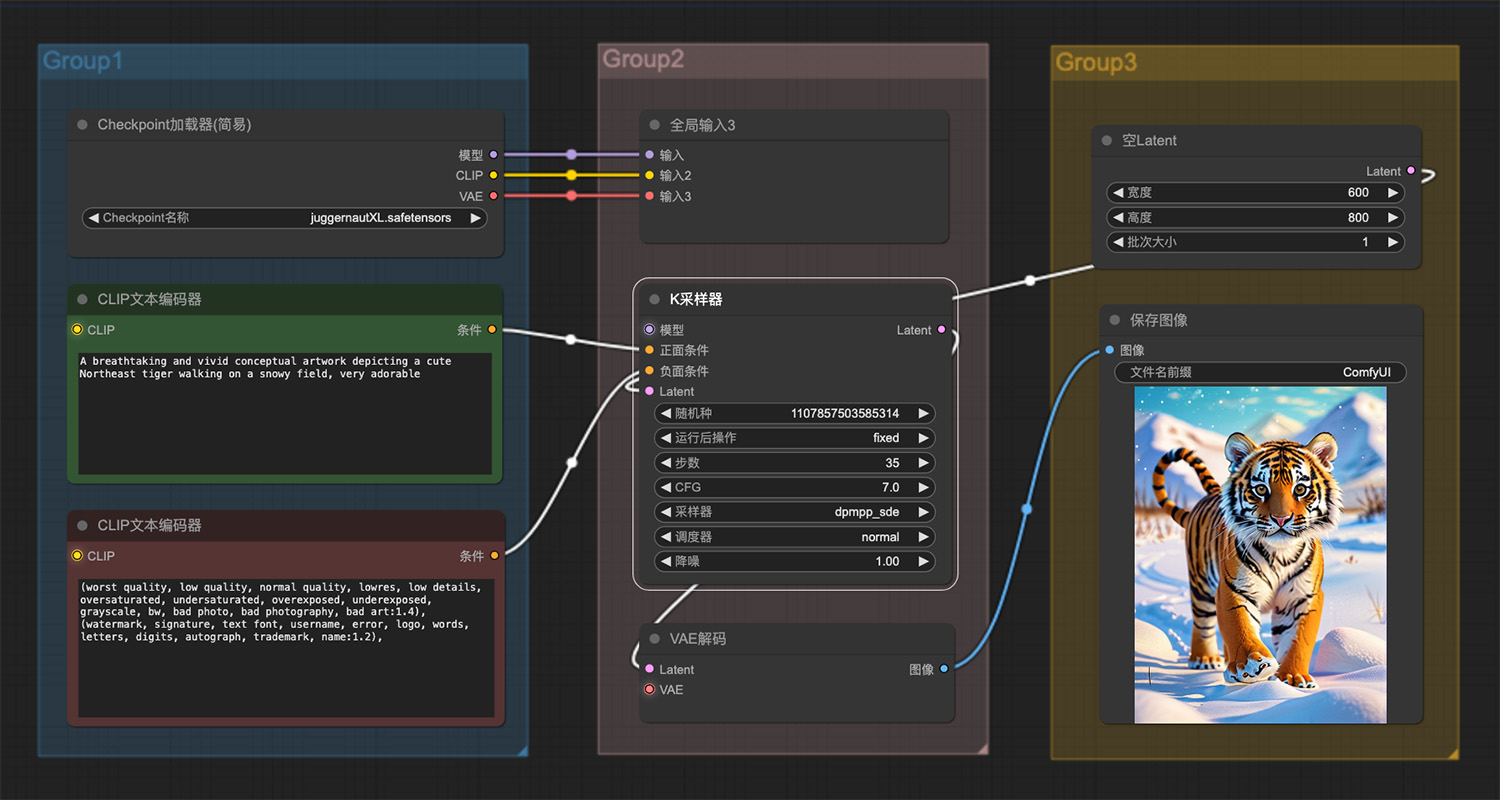 雪地里一只可爱的小老虎
雪地里一只可爱的小老虎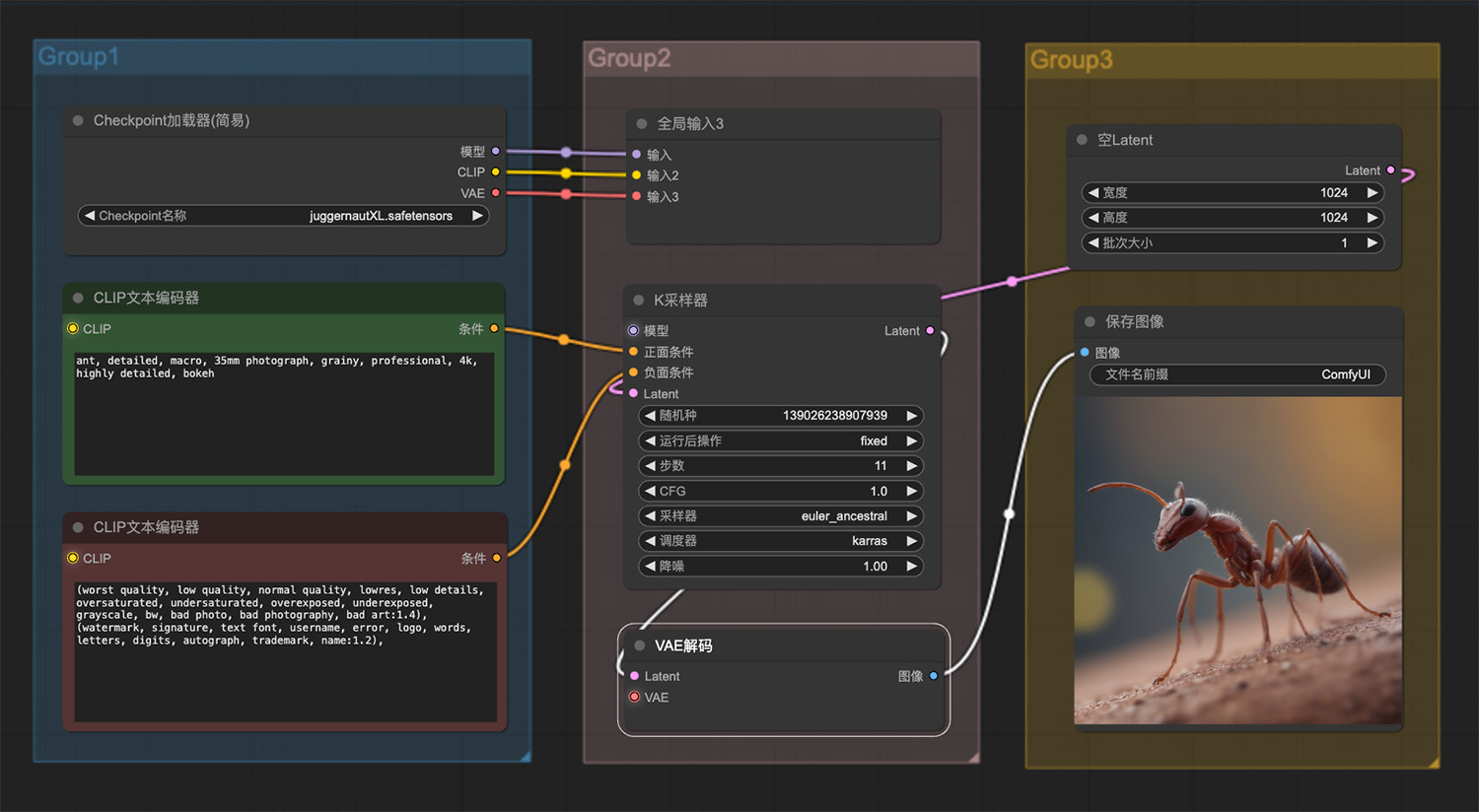 一只处于战斗状态下的蚂蚁ComfyUI工作流
一只处于战斗状态下的蚂蚁ComfyUI工作流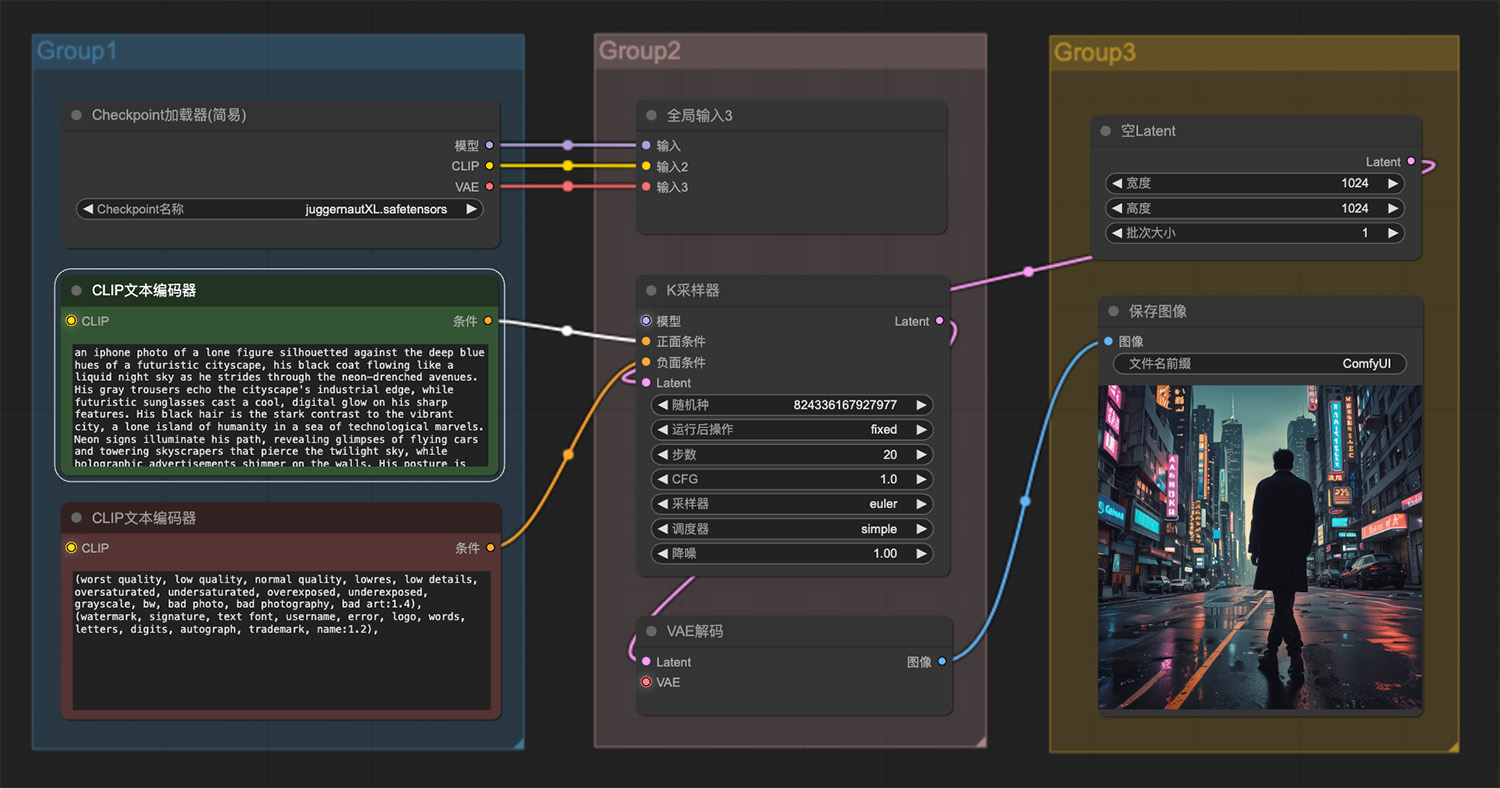 一个孤独的身影在未来主义城市
一个孤独的身影在未来主义城市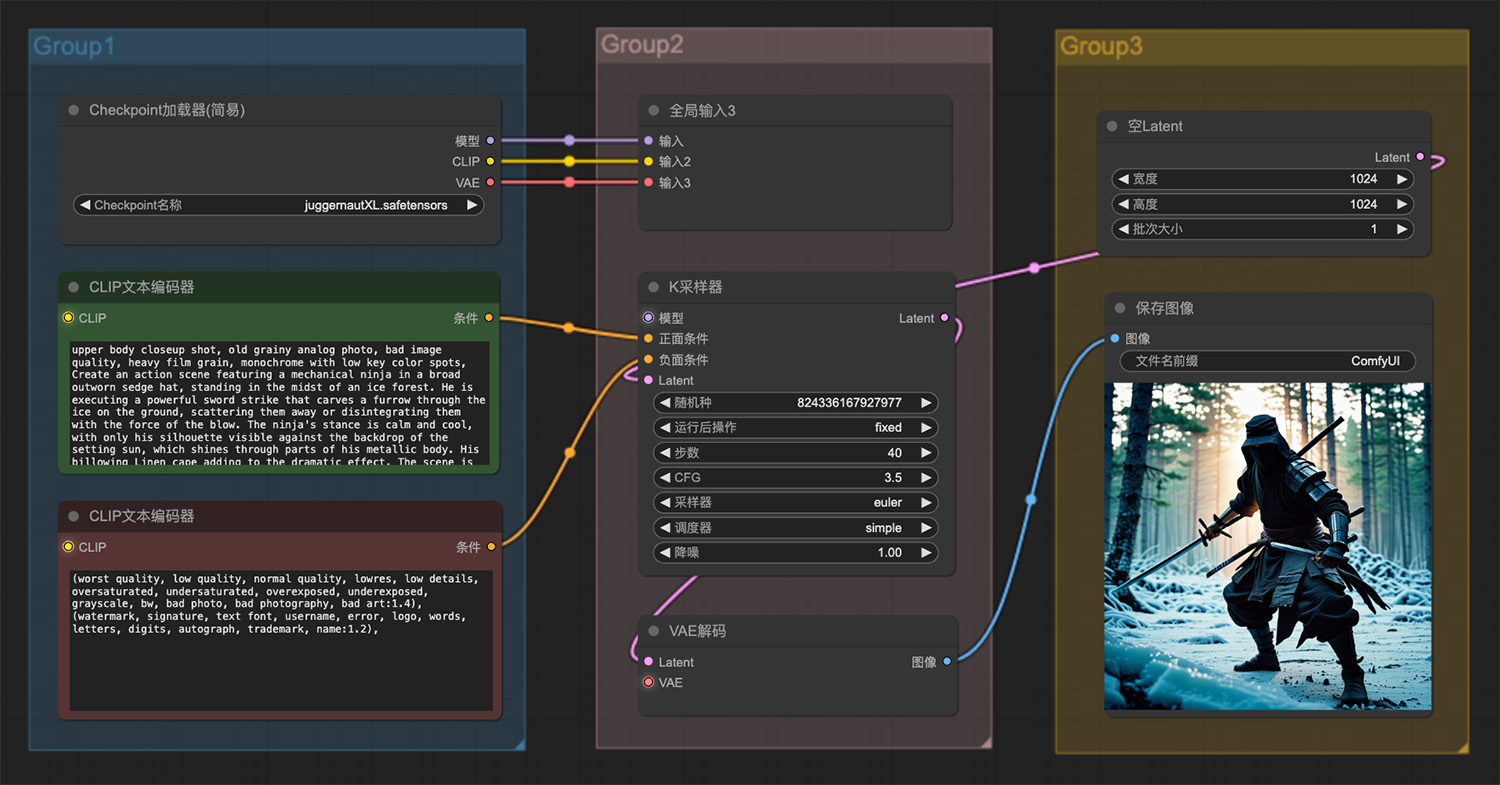 一个戴着破旧莎帽子的机械忍者站在冰林中
一个戴着破旧莎帽子的机械忍者站在冰林中 即梦AI绘画网页版
即梦AI绘画网页版 阿里·通义千问网页版
阿里·通义千问网页版 藏族日历小程序
藏族日历小程序
 SEOmatic AI
SEOmatic AI BestBlogs
BestBlogs 卡兹克.skill
卡兹克.skill Character Generator
Character Generator Computer Use Preview
Computer Use Preview
 彝族日历小程序
彝族日历小程序
 思想白板iThinkAir
思想白板iThinkAir 云言AI智搜
云言AI智搜 IFTTT
IFTTT 小微助手
小微助手 RedClaw
RedClaw