-

- AI开发助手Polar英伟达开源的智能体强化学习(Agentic RL)训练框架,核心亮点为零源码侵入式接入,不用改动原有智能体内核代码,即可对接GRPO等主流强化学习算法。
爱站权重:


Polar是英伟达开源的智能体强化学习(Agentic RL)训练框架,核心亮点为零源码侵入式接入,不用改动原有智能体内核代码,即可对接GRPO等主流强化学习算法。依托在LLM API链路部署代理拦截数据,抓取Token粒度交互信息并还原训练轨迹,让Codex CLI、Claude Code、通义千问Qwen Code、Pi等各类代码智能体快速改造为可用的强化学习训练环境。
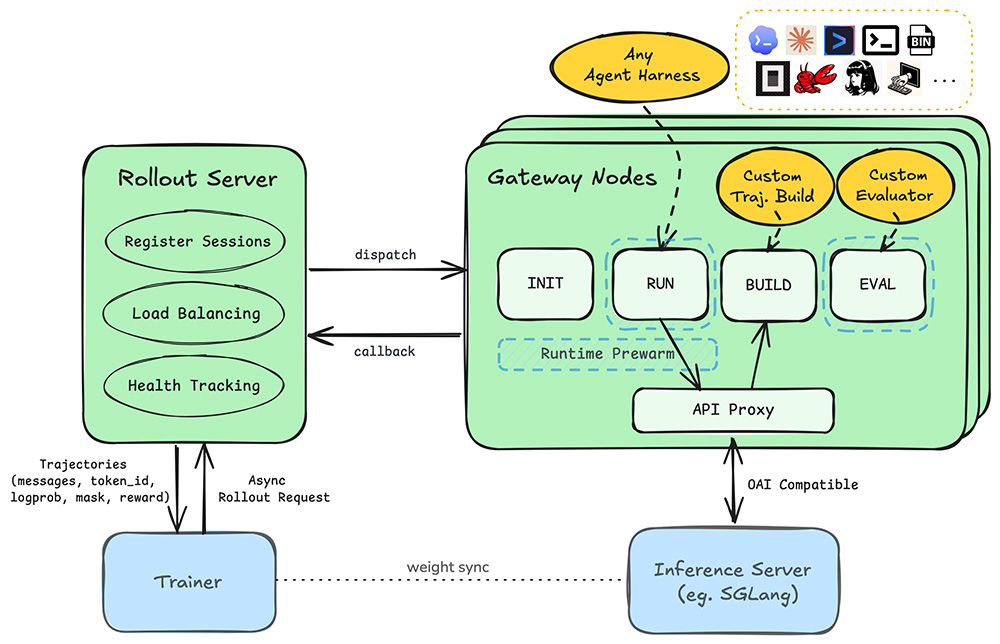
Polar核心功能:
1、API透明代理采集:
在智能体与推理服务中间架设多协议兼容代理,适配OpenAI、Anthropic、Google三类主流API规范,在无感转发请求的同时,完整留存提示词、采样Token、对数概率、模型返回内容全量数据。
2、双模式轨迹自动重构:
提供逐请求、前缀合并两种轨迹组装方案,把多轮串联的模型调用数据规整成训练框架可直接读取的强化学习样本。
3、分布式异步架构:
采用分层服务拆分:Rollout Server管控任务分发与负载均衡,Gateway节点承担环境预热、智能体运行、轨迹合成、效果评测,实现训练与智能体执行流程解耦。
4、主流代码智能体开箱适配:
原生兼容Claude Code、Codex、Qwen Code、OpenCode、Pi、Gemini CLI等多款代码智能体运行基座。
5、容器隔离运行:
支持Docker、无特权Apptainer两种容器方案,为智能体提供安全隔离的执行沙箱。
Polar部署使用流程:
1、部署基座:
启动Rollout Server与Gateway节点,对接SGLang等后端推理服务;
2、路由转接:
修改目标智能体模型接口地址,指向Polar网关代理地址;
3、配置适配:
依托环境变量、服务商参数、启动命令快速编写智能体适配脚本;
4、提交任务:
调用Polar开放API,选定智能体类型、运行容器、评测方案、轨迹生成策略;
5、对接训练:
Slime、Megatron等训练引擎通过回调接口拉取轨迹数据,落地GRPO强化学习迭代优化。
Polar产品核心优势:
1、零侵入改造:
无需修改智能体底层源码,大幅降低现有项目落地RL训练成本;
2、通用兼容:
不限智能体形态,所有依托LLM API调用的智能体(含闭源二进制程序)均可接入;
3、算力高效:
异步架构隔离CPU环境初始化与GPU训练任务,前缀合并策略最高缩短约5.39倍训练耗时;
4、原始数据保真:
直接抓取推理侧原生Token数据,规避文本二次转码造成的训练标签失真;
5、集群弹性扩容:
基于Rollout服务化架构,可横向拓展,支撑超大集群分布式强化学习训练。

数据统计
特别声明&浏览提醒
本站AI工具导航站提供的「Polar」的相关内容都来源于网络,不保证外部链接的准确性和完整性。在2026年06月02日 20时42分59秒收录时,该网站上的内容都属于合规合法,后期网站的内容如出现违规,可以直接联系网站管理员(ai@ipkd.cn)进行删除,AI工具导航站不承担任何责任。在浏览网页时,请注意您的账号和财产安全,切勿轻信网上广告!
 6款AI视频翻译与配音工具,一键生成多语言视频
6款AI视频翻译与配音工具,一键生成多语言视频 11款免费AI思维导图工具,一键生成高效思维图
11款免费AI思维导图工具,一键生成高效思维图 8款热门AI绘画工具,国内外免费资源,轻松创作艺术佳作!
8款热门AI绘画工具,国内外免费资源,轻松创作艺术佳作! BrowserAct Skills – 面向AI Agent的浏览器自动化CLI工具
BrowserAct Skills – 面向AI Agent的浏览器自动化CLI工具 ClawHub镜像站官网:OpenClaw官方推出的中国区专属镜像站点
ClawHub镜像站官网:OpenClaw官方推出的中国区专属镜像站点 5款AI短剧创作软件,自动剪辑,一键生成你的创意短剧!
5款AI短剧创作软件,自动剪辑,一键生成你的创意短剧! 8款二次元AI绘画工具,一键生成动漫风插画,免费试用!
8款二次元AI绘画工具,一键生成动漫风插画,免费试用! 打工人开工的12款办公室ai工具
打工人开工的12款办公室ai工具 一轮月亮悬挂在树上的天空中ComfyUI工作流
一轮月亮悬挂在树上的天空中ComfyUI工作流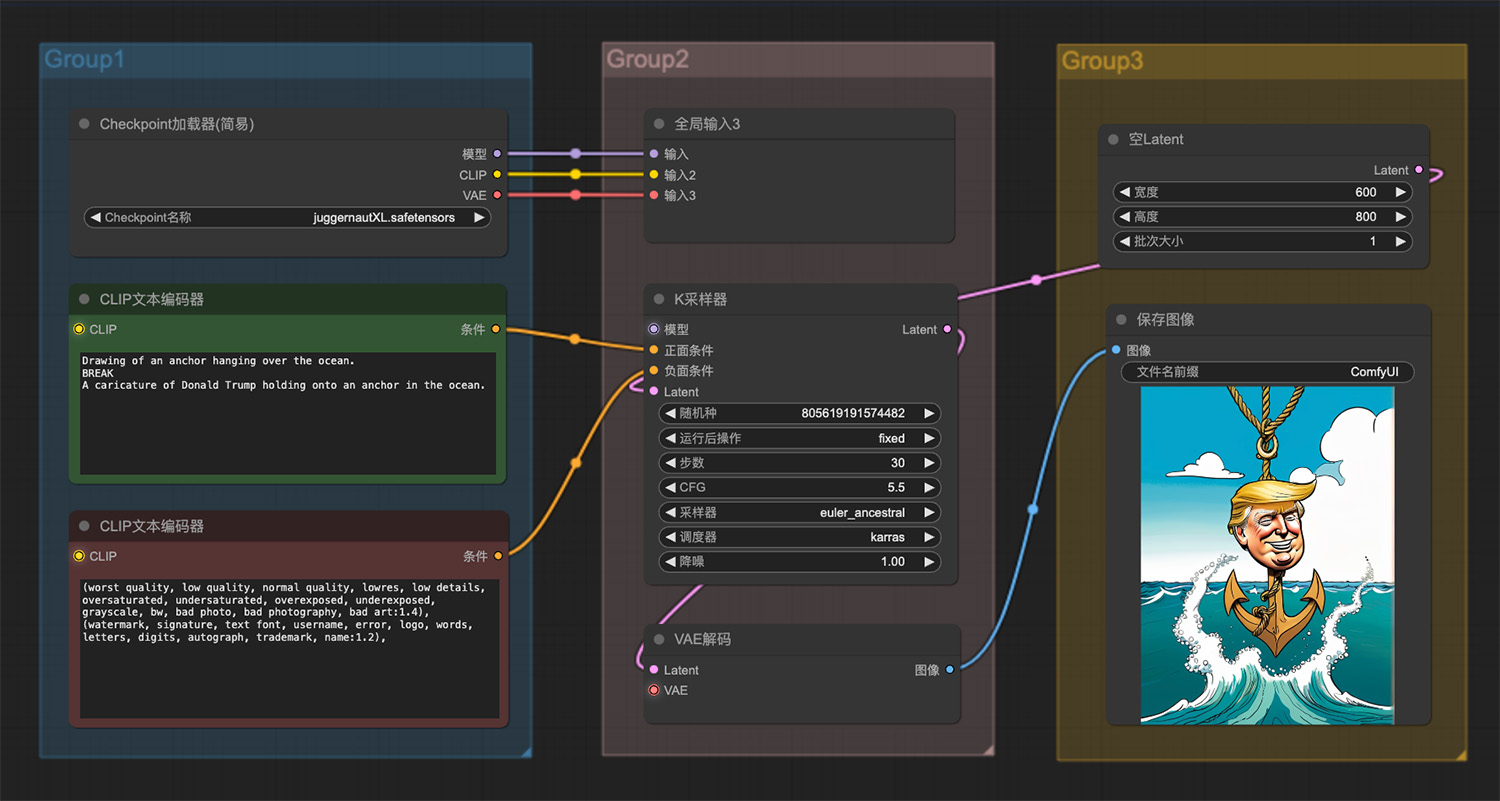 懂王特朗普3d漫画ComfyUI工作流
懂王特朗普3d漫画ComfyUI工作流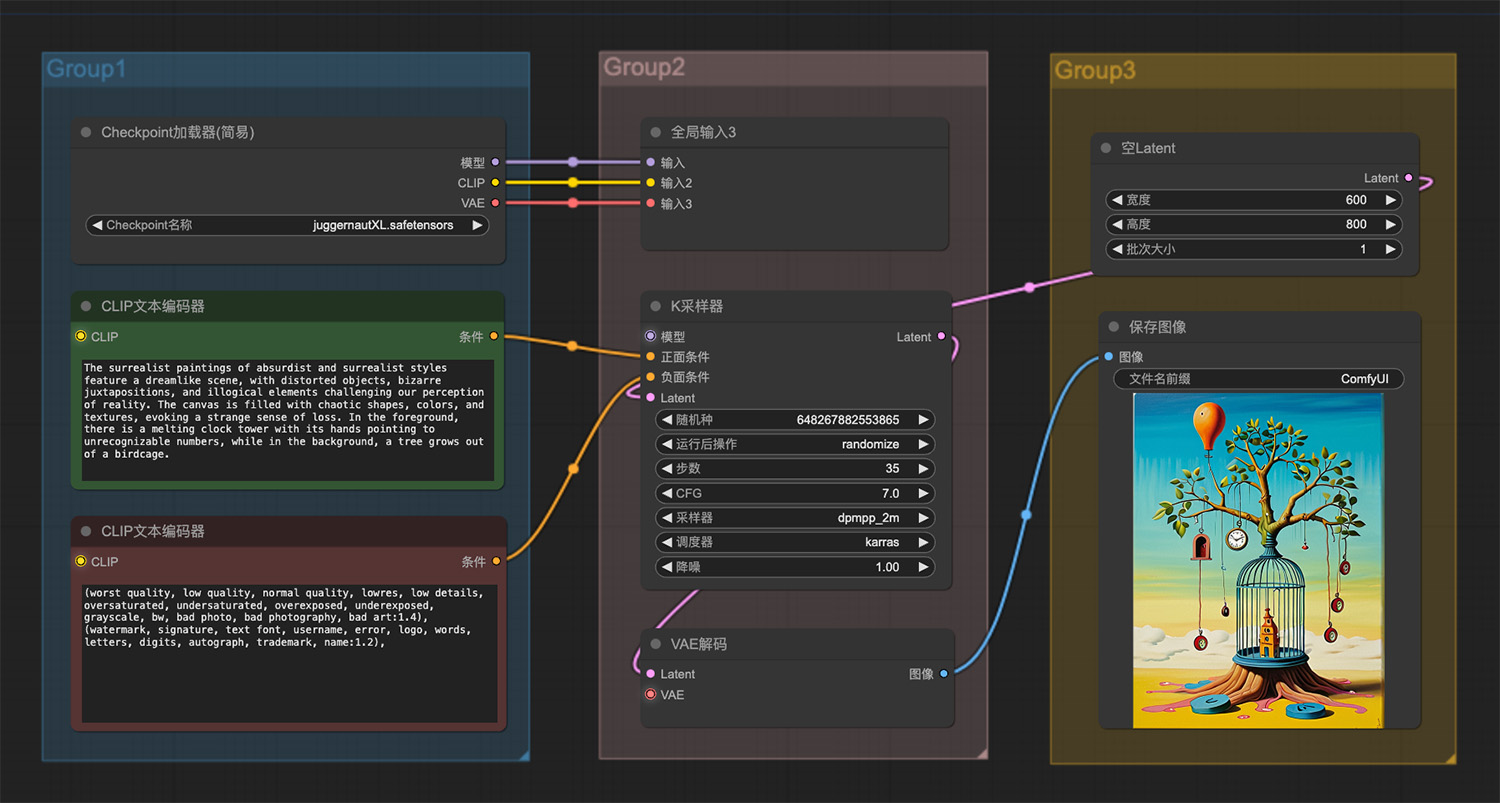 一棵树从鸟笼里长出来的梦幻般场景
一棵树从鸟笼里长出来的梦幻般场景 一朵由琥珀制成的孤独美丽的玫瑰
一朵由琥珀制成的孤独美丽的玫瑰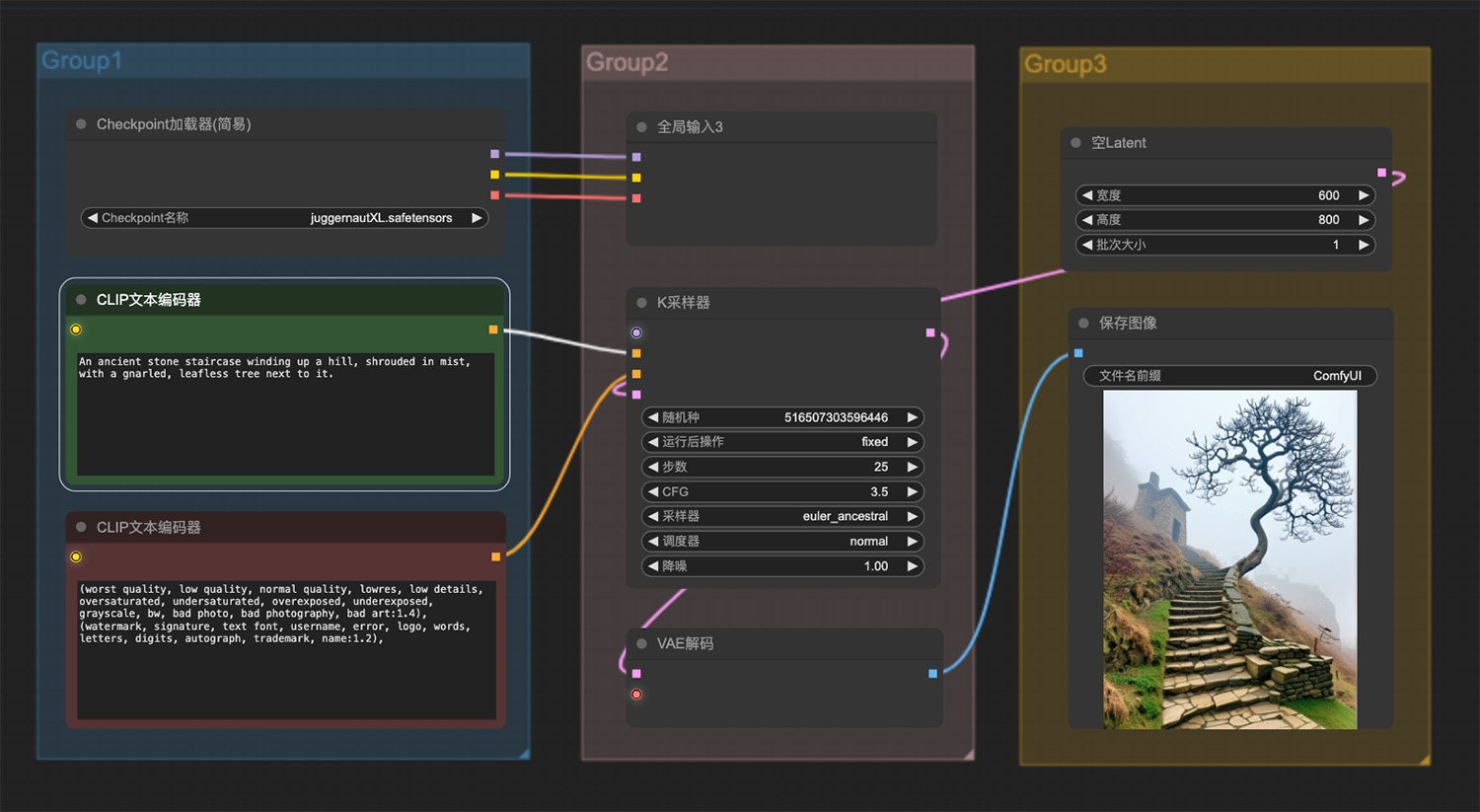 一座古老的石阶,旁边有一棵树
一座古老的石阶,旁边有一棵树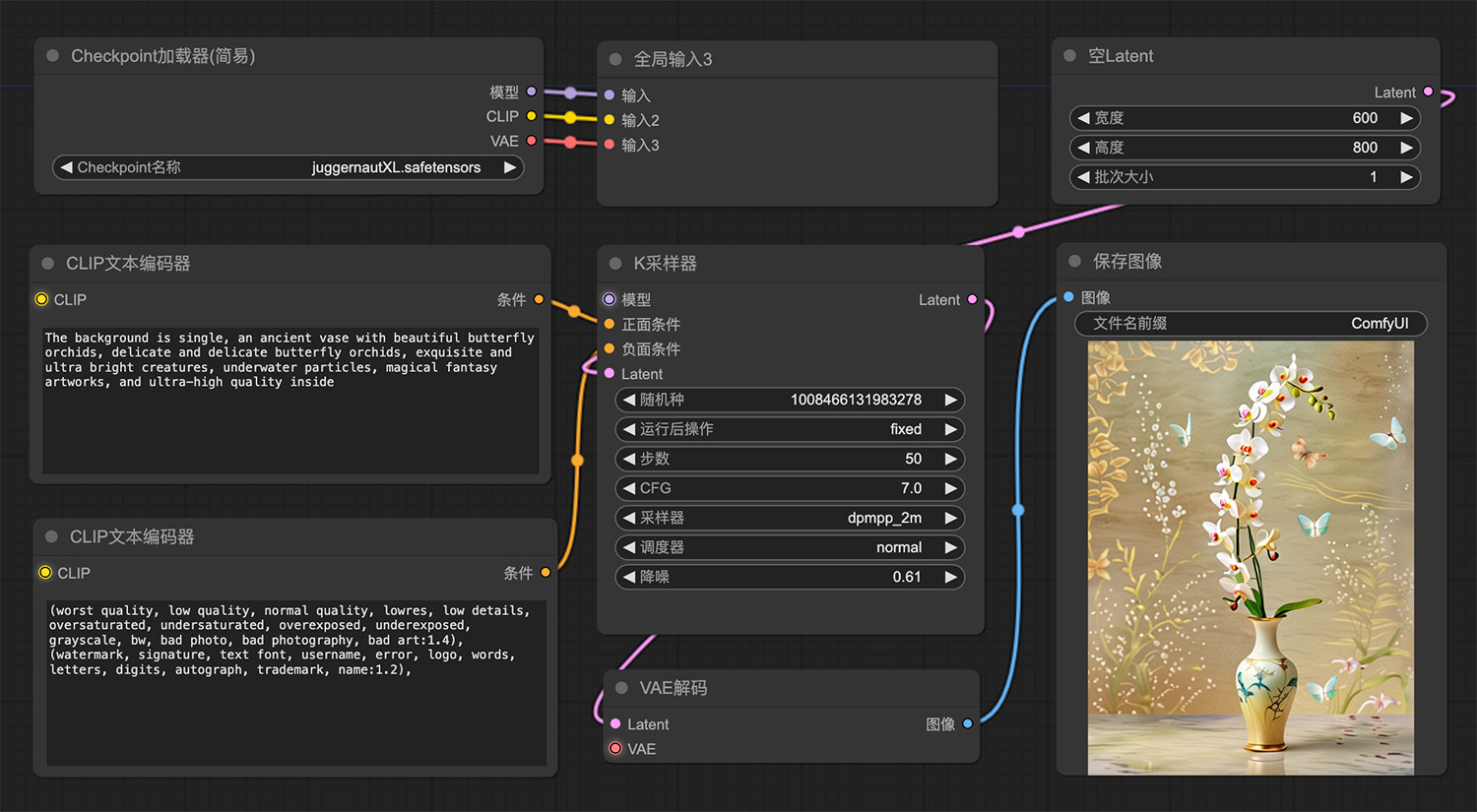 蝴蝶兰comfyui工作流
蝴蝶兰comfyui工作流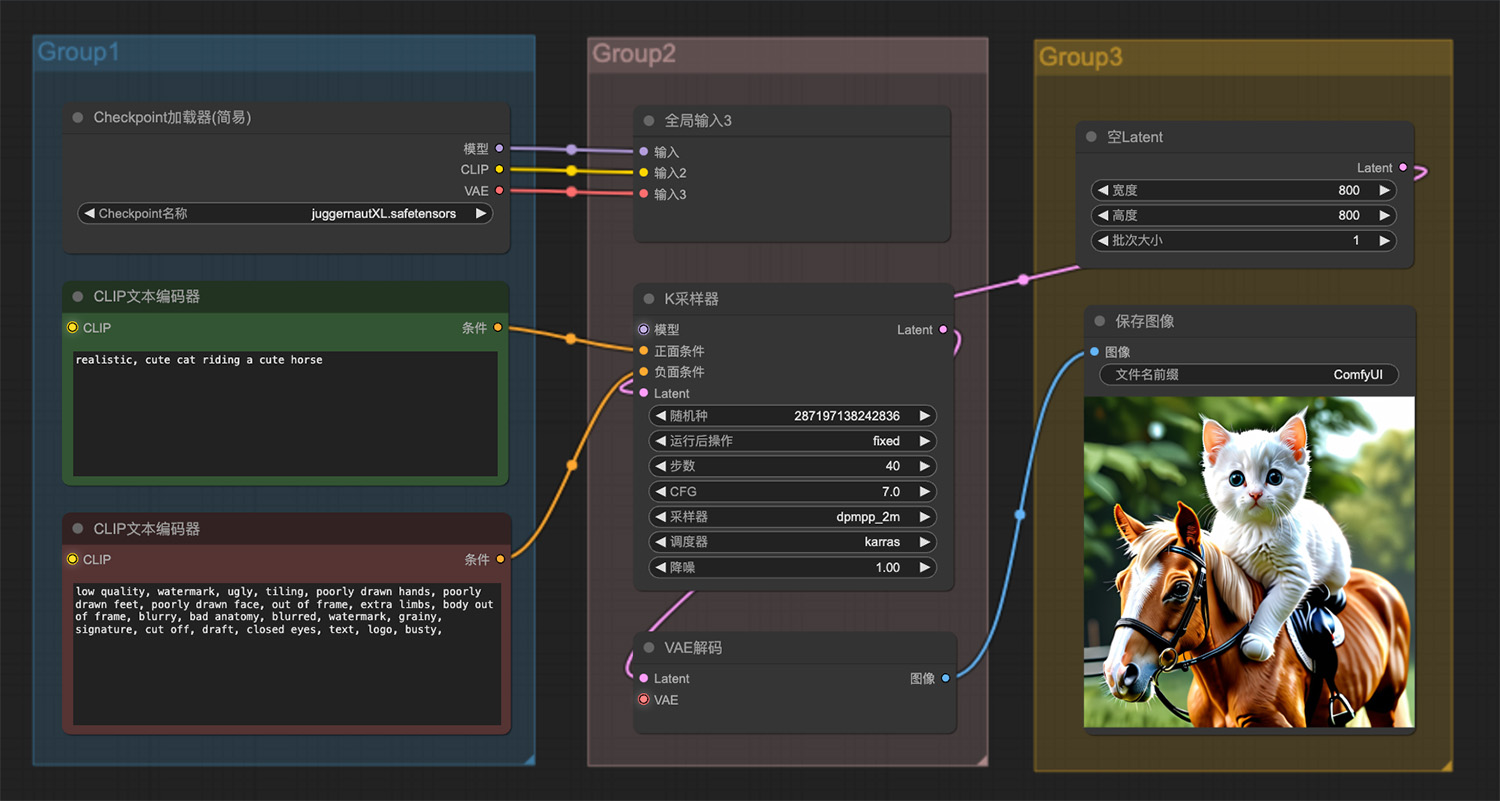 一只可爱的猫骑着一匹可爱的马ComfyUI工作流
一只可爱的猫骑着一匹可爱的马ComfyUI工作流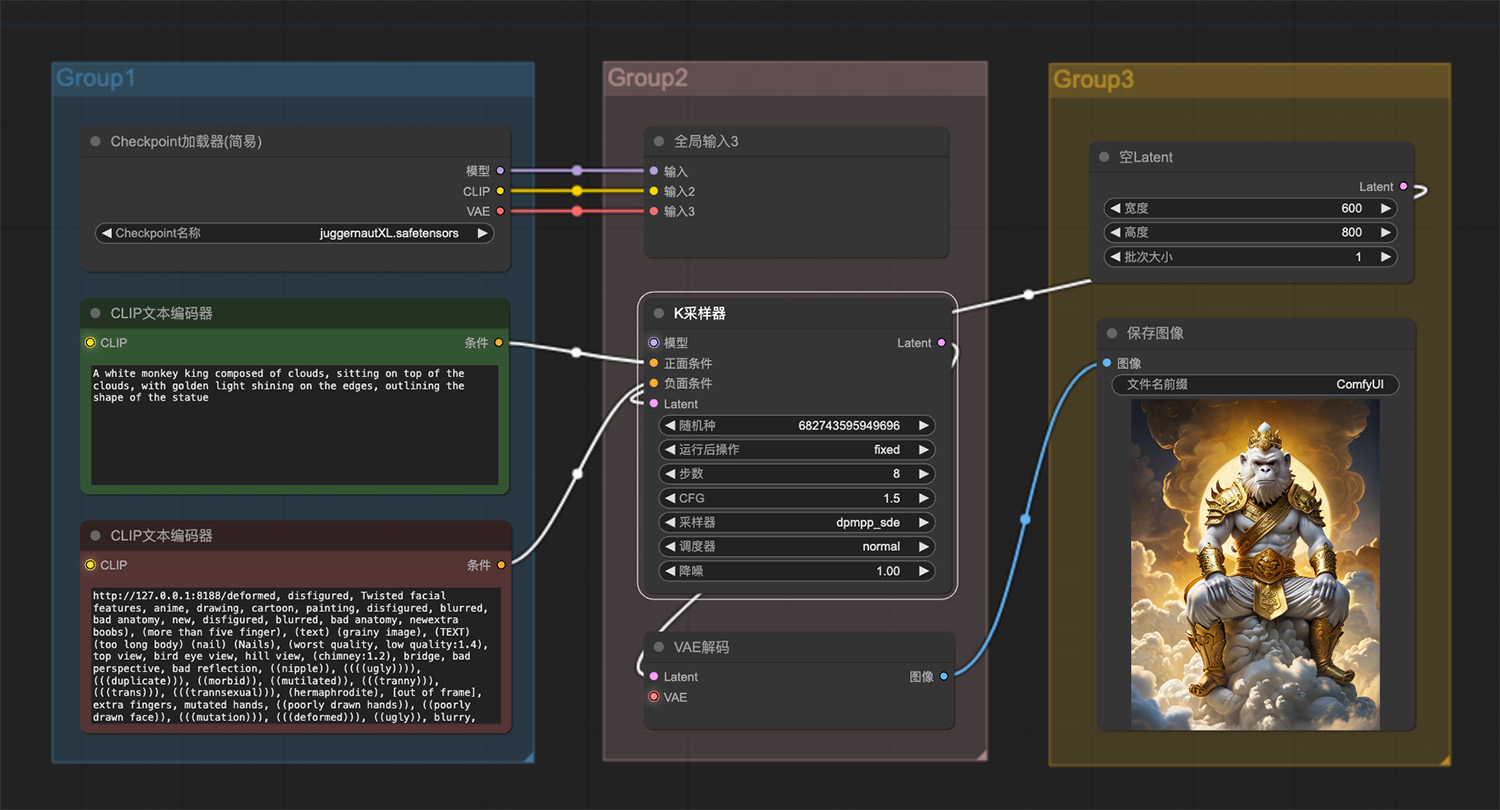 一尊白玉猴王ComfyUI工作流
一尊白玉猴王ComfyUI工作流 即梦AI绘画网页版
即梦AI绘画网页版 藏族日历小程序
藏族日历小程序
 Meta AI
Meta AI Sky-code
Sky-code 花火数图
花火数图 Strix
Strix Kilo Code
Kilo Code Crew44
Crew44
 彝族日历小程序
彝族日历小程序
 MyClaw
MyClaw FlutterFlow
FlutterFlow Atoms
Atoms theORQL
theORQL Loki.Build
Loki.Build