-

- AI创新应用Qwen2-VL阿里巴巴达摩院最新发布的视觉多模态AI模型,基于Qwen2打造。


Qwen2-VL是阿里巴巴达摩院最新发布的视觉多模态AI模型,基于Qwen2打造。它在图像和视频理解方面展现了卓越的能力,并且具备多种功能特点。
Qwen2-VL项目官网:https://qwenlm.github.io/zh/blog/qwen2-vl/
Qwen2-VL GitHub 仓库:https://github.com/QwenLM/Qwen2-VL
Qwen2-VL HuggingFace 模型库: https://huggingface.co/collections/Qwen/qwen2-vl(需科学上网)
Qwen2-VL 体验 Demo:https://huggingface.co/spaces/Qwen/Qwen2-VL(需科学上网)
Qwen2-VL api服务: https://help.aliyun.com/zh/model-studio/developer-reference/qwen-vl-api
Qwen2-VL能够处理不同分辨率和长宽比的图片,这意味着它可以适应各种图像输入,无需将图像分割成块,从而确保模型输入与图像固有信息之间的一致性。此外,它还支持对20分钟以上长视频的理解能力,使其在视频分析任务中表现出色。
Qwen2-VL不仅限于静态图像和视频的理解,它还可以集成到手机、机器人等设备中,根据视觉环境和文字指令进行自动操作。这一功能使其成为一个强大的视觉智能体,可以自主执行复杂任务。例如,在安防和智能客服场景中,Qwen2-VL可以实时分析用户展示的产品图像或条形码,并给出相关商品信息,大幅提升人机交互体验。
此外,Qwen2-VL引入了突破性的技术如Naive Dynamic Resolution和Multimodal Rotary Position Embedding (M-ROPE),这些技术增强了其在多模态任务中的表现。Naive Dynamic Resolution允许模型动态映射任意分辨率的图像为视觉令牌,而M-ROPE则通过分解位置嵌入来捕捉一维文本、二维视觉和三维视频的位置信息。
Qwen2-VL还展示了其在多语言文本理解、文档理解等任务上的卓越性能,适用于广泛的多模态应用开发。测试数据显示,其72B模型在大多数指标上超过了OpenAI的GPT-4o和Anthropic的Claude3.5-Sonnet等知名闭源模型,成为目前最强的多模态AI模型之一。

数据统计
特别声明&浏览提醒
本站AI工具导航站提供的「Qwen2-VL」的相关内容都来源于网络,不保证外部链接的准确性和完整性。在2024年09月06日 10时10分49秒收录时,该网站上的内容都属于合规合法,后期网站的内容如出现违规,可以直接联系网站管理员(ai@ipkd.cn)进行删除,AI工具导航站不承担任何责任。在浏览网页时,请注意您的账号和财产安全,切勿轻信网上广告!
 5款AI短剧创作软件,自动剪辑,一键生成你的创意短剧!
5款AI短剧创作软件,自动剪辑,一键生成你的创意短剧! 打工人必备!10款浏览器摸鱼插件,轻松应对工作间隙!
打工人必备!10款浏览器摸鱼插件,轻松应对工作间隙! 2025年ai声音克隆哪个最好 盘点值得推荐的AI声音克隆工具2025
2025年ai声音克隆哪个最好 盘点值得推荐的AI声音克隆工具2025 DeepSeek:开启人工智能的深度探索之旅,解锁未来科技的无限可能!
DeepSeek:开启人工智能的深度探索之旅,解锁未来科技的无限可能! 几款免费AI 3D模型生成工具,快速制作逼真三维模型!
几款免费AI 3D模型生成工具,快速制作逼真三维模型! 5个免费AI漫画生成工具,一键开启漫画创作之旅!
5个免费AI漫画生成工具,一键开启漫画创作之旅! 6款免费AI写作神器,一键生成文章、报告、公文、论文,高效又省心!
6款免费AI写作神器,一键生成文章、报告、公文、论文,高效又省心! 8款热门AI绘画工具,国内外免费资源,轻松创作艺术佳作!
8款热门AI绘画工具,国内外免费资源,轻松创作艺术佳作!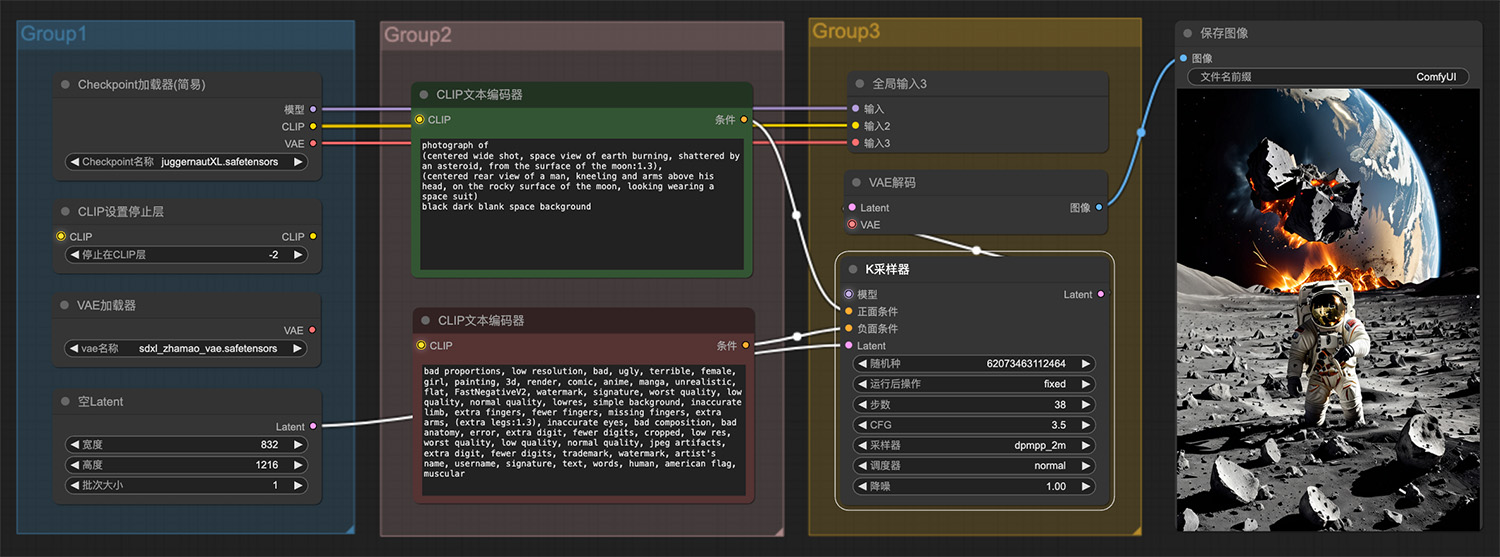 一名男子跪在月球岩石表面看见小行星碰撞
一名男子跪在月球岩石表面看见小行星碰撞 文生图工作流:一幅海底睡莲,碧海蓝天comfyui工
文生图工作流:一幅海底睡莲,碧海蓝天comfyui工 一只由水晶制成的蜂鸟
一只由水晶制成的蜂鸟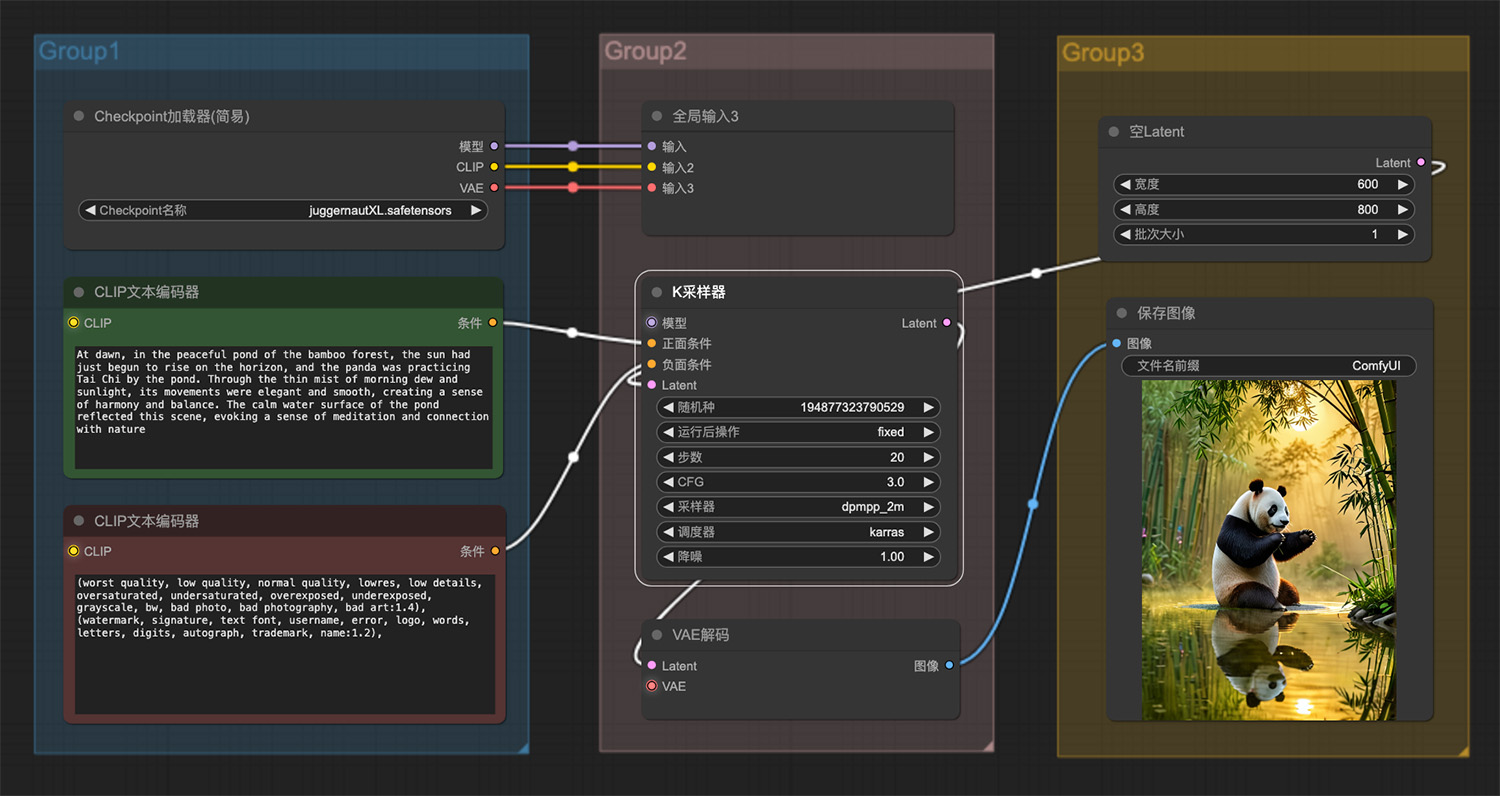 池塘边的大熊猫ComfyUI工作流
池塘边的大熊猫ComfyUI工作流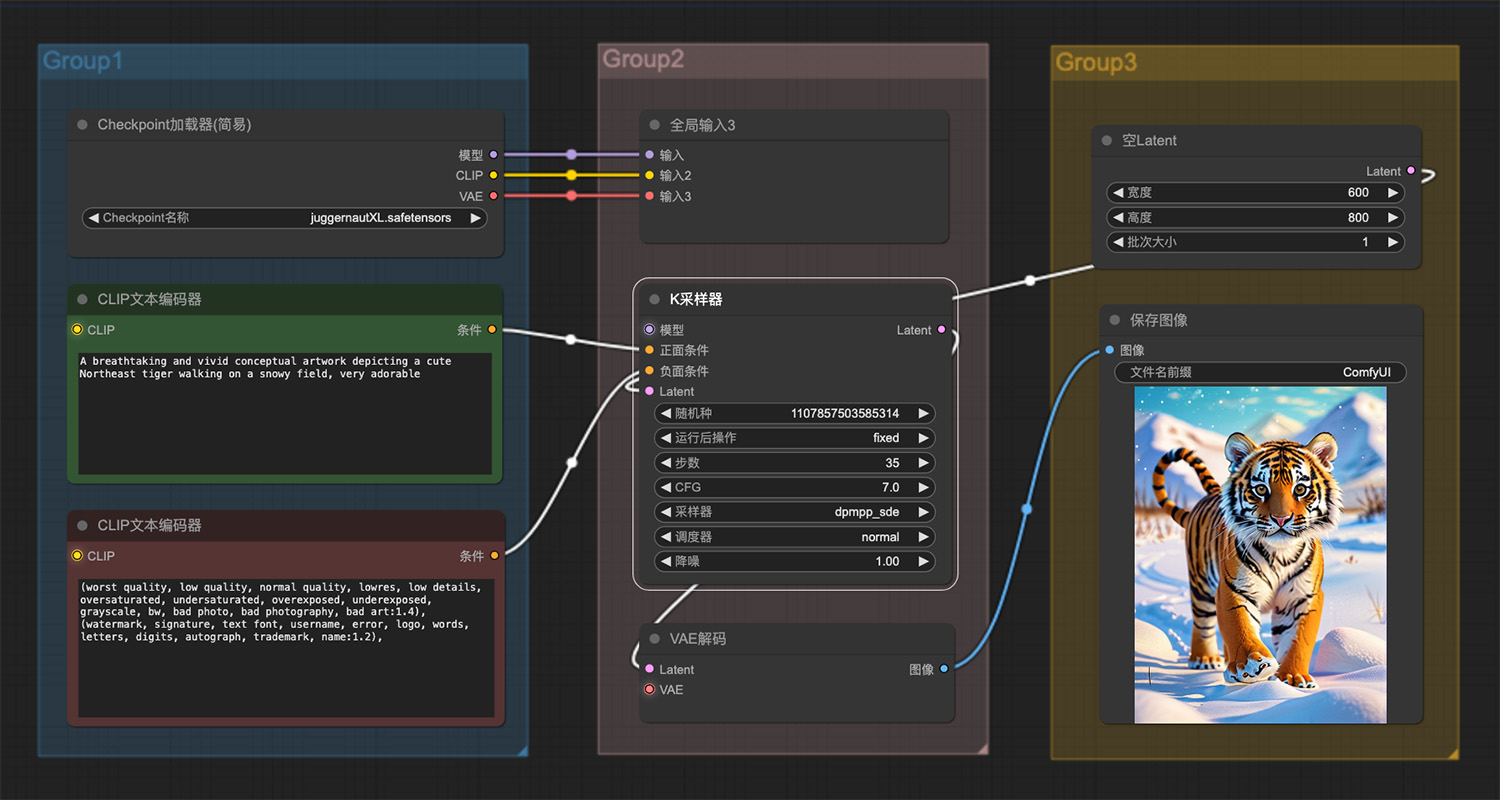 雪地里一只可爱的小老虎
雪地里一只可爱的小老虎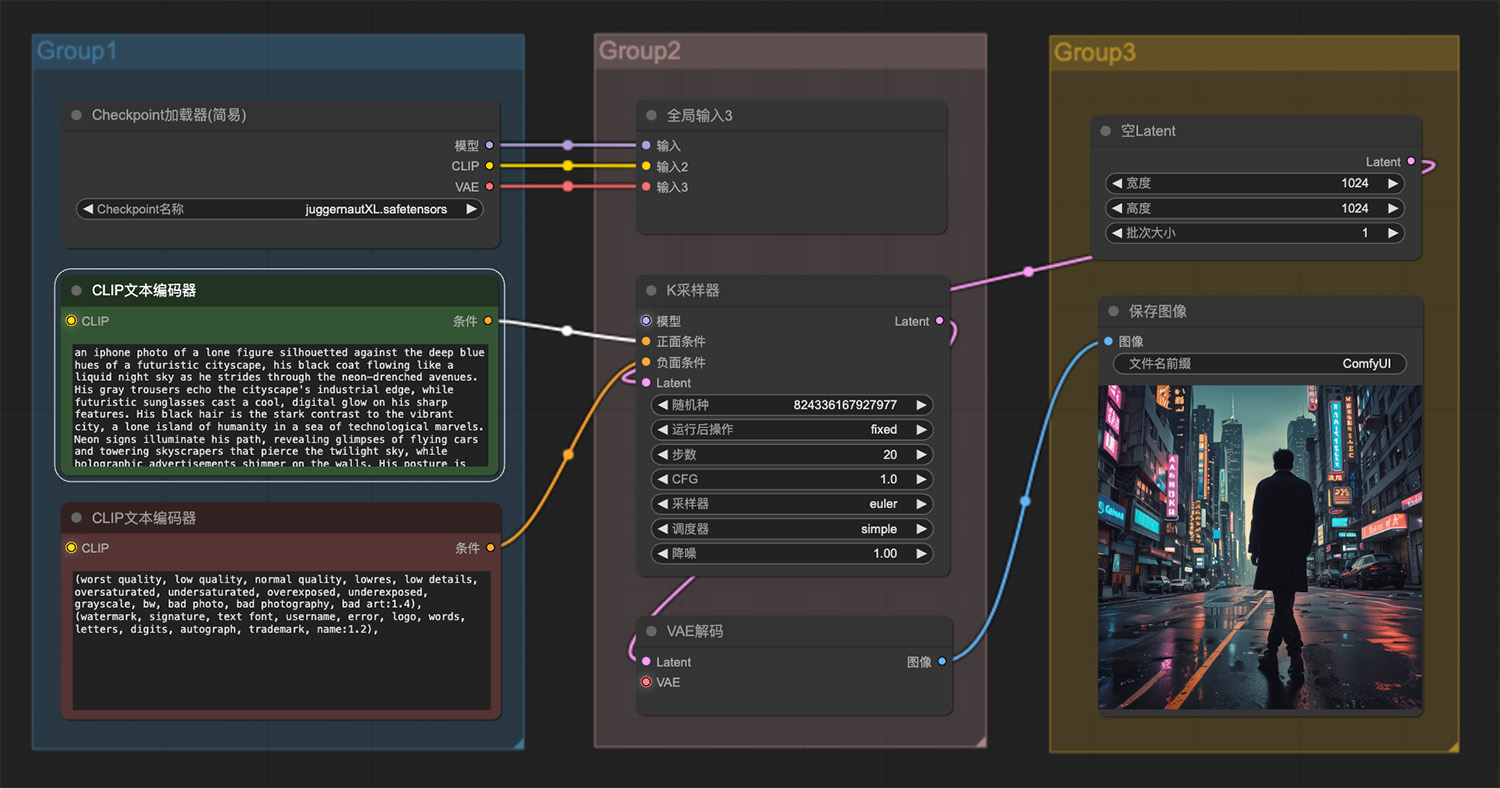 一个孤独的身影在未来主义城市
一个孤独的身影在未来主义城市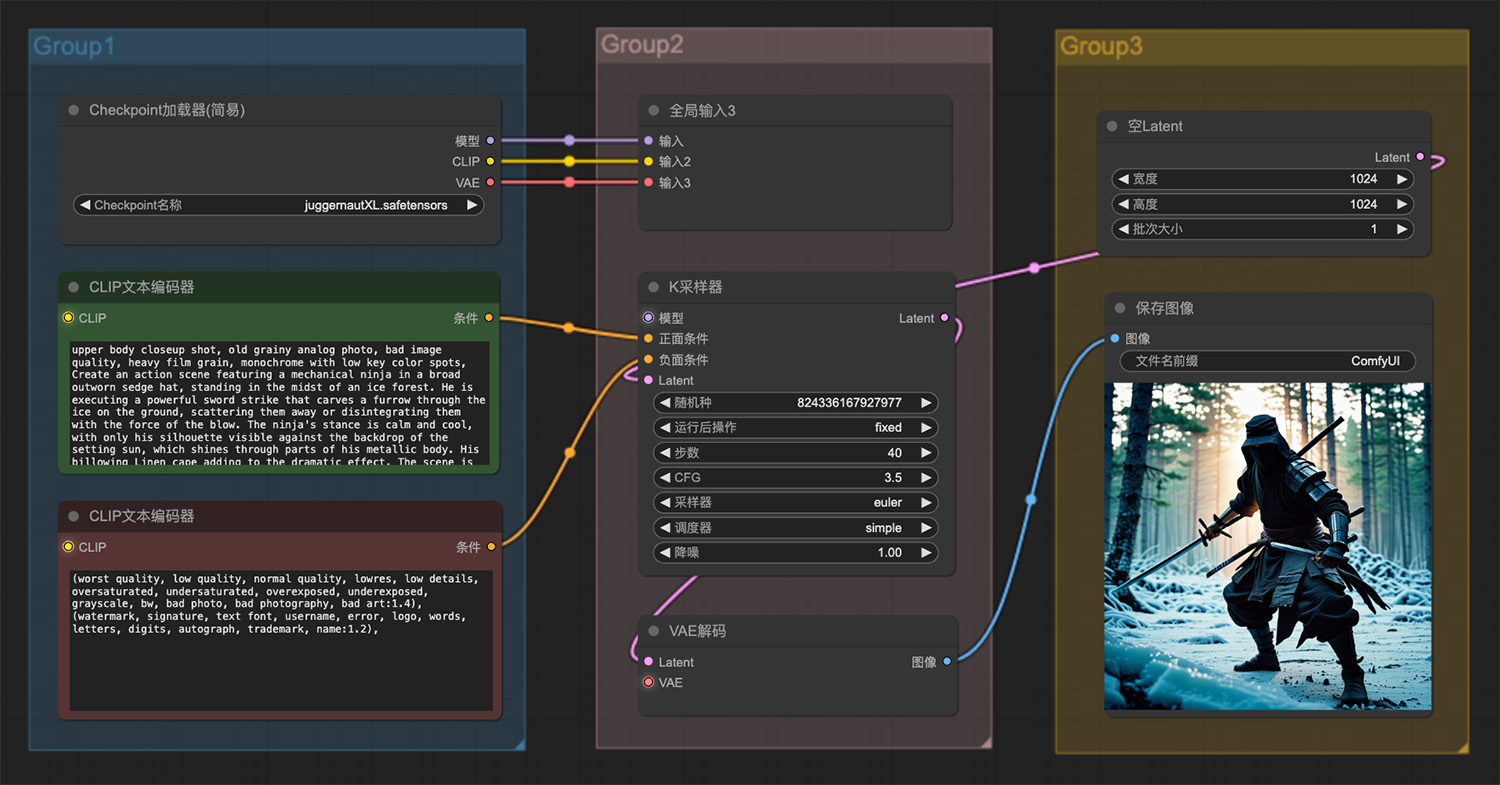 一个戴着破旧莎帽子的机械忍者站在冰林中
一个戴着破旧莎帽子的机械忍者站在冰林中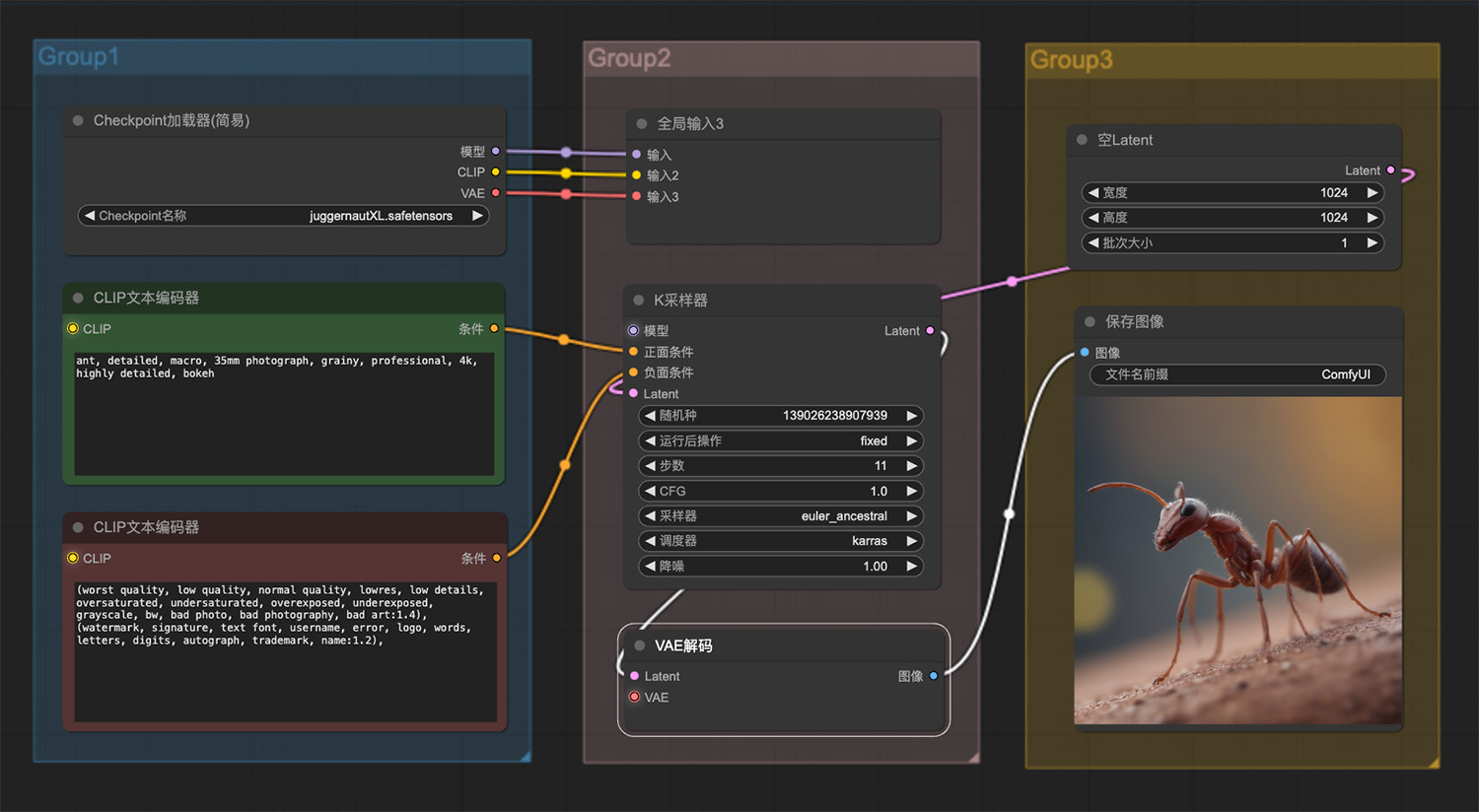 一只处于战斗状态下的蚂蚁ComfyUI工作流
一只处于战斗状态下的蚂蚁ComfyUI工作流 即梦AI绘画网页版
即梦AI绘画网页版 阿里·通义千问网页版
阿里·通义千问网页版 藏族日历小程序
藏族日历小程序
 SEOmatic AI
SEOmatic AI 卡兹克.skill
卡兹克.skill Computer Use Preview
Computer Use Preview Character Generator
Character Generator BestBlogs
BestBlogs
 彝族日历小程序
彝族日历小程序
 小微助手
小微助手 IFTTT
IFTTT 思想白板iThinkAir
思想白板iThinkAir RedClaw
RedClaw 云言AI智搜
云言AI智搜