
-

- AI开发助手Scrapling数据采集工具核心解决传统爬虫“网站改版即失效”“反爬对抗复杂”“多工具拼接繁琐”三大痛点,实现“一次编写、长期稳定”的爬虫开发体验。


Scrapling是2024年10月开源的Python自适应Web爬虫框架,由开发者Karim Shoair打造,核心解决传统爬虫“网站改版即失效”“反爬对抗复杂”“多工具拼接繁琐”三大痛点,实现“一次编写、长期稳定”的爬虫开发体验。
Scrapling核心定位:
1、官方定义:
An adaptive Web Scraping framework that handles everything from a single request to a full-scale crawl(自适应爬虫框架,覆盖从单次请求到大规模抓取的全场景)。
2、核心理念:
网站会变,但爬虫不该失效,以“一库到底、零妥协”为目标,整合请求、解析、反爬、自动化、并发能力。
3、开源状态:
GitHub 48K+ Star、45K+ Fork,活跃开发,BSD-3-Clause协议(支持商业使用)。
Scrapling核心特点:
1、自适应元素定位(独创核心能力):
- AI驱动智能解析:首次抓取自动记录元素多维特征(标签、文本、属性、DOM路径、父子节点关系)。
- 自动重定位:网站结构改版、CSS/XPATH失效时,通过相似度算法自动找回目标元素,无需手动改代码。
- 性能极强:解析速度比 BeautifulSoup 快784倍,内存占用低,低配设备也能流畅运行。
2、全场景反爬绕过(开箱即用):
- 内置 StealthyFetcher:基于魔改 Firefox(Camoufox),一键绕过 Cloudflare Turnstile、验证码、JS 检测、IP 追踪等90%+常见反爬机制。
- 浏览器指纹伪装:支持 TLS 指纹匹配、真实浏览器 Header 模拟,规避行为分析。
- 多会话支持:FetcherSession、DynamicSession、StealthySession 三种会话,适配不同反爬强度。
3、企业级爬虫框架能力:
- 类 Scrapy 架构:支持 start_urls、async parse 回调、Request/Response 对象,上手无门槛。
- 高并发调度:可配置并发数、域名限流、下载延迟,支持代理自动轮换。
- 断点续爬:基于检查点的持久化,Ctrl+C 优雅关闭,重启后无缝恢复任务。
- 全链路工具链:CLI 命令行、交互式 Shell、Docker 镜像、AI 扩展(MCP 服务器)。
Scrapling开源项目官网:
1、GitHub 仓库(主站):https://github.com/D4Vinci/Scrapling
2、官方文档:https://scrapling.readthedocs.io/en/latest/
3、PyPI 包:https://pypi.org/project/scrapling/
Scrapling数据采集工具数据评估:
【Scrapling数据采集工具】浏览人数已经达到 次,如你需要查询该站的相关权重信息,建议直接到 5118、爱站 或 Chinaz 搜索域名「」查看最新权重、收录与关键词排名;若需精确的 IP、PV、跳出率等核心指标,仍需与站长沟通获取后台数据。总体判断时,可把访问速度、索引量、用户停留体验等因素一起纳入考量,并结合自身需求再做决策。
Scrapling数据采集工具(官网)打不开万能教程:
1、微信/QQ内打不开:
把链接复制到系统浏览器再访问,微信/QQ内置页常自动拦截第三方站。
2、浏览器报“违规”:
部分国产浏览器的误拦截,换用系统原生浏览器即可:iPhone→Safari,安卓→Edge、Alook、X、Via 等轻量浏览器,均不会误屏蔽。
3、网络加载慢或空白:
先切换 4G/5G 与 Wi-Fi 对比;可以尝试使用网络加速器,将网络切换至更稳定的运营商。另外,部分网站可能需要科学上网才能访问,如 Google、Hugging Face 等一些国外服务器的网站(不推荐)。
数据统计
特别声明&浏览提醒
本站AI工具导航站提供的「Scrapling数据采集工具」的相关内容都来源于网络,不保证外部链接的准确性和完整性。在2026年05月16日 13时29分44秒收录时,该网站上的内容都属于合规合法,后期网站的内容如出现违规,可以直接联系网站管理员(ai@ipkd.cn)进行删除,AI工具导航站不承担任何责任。在浏览网页时,请注意您的账号和财产安全,切勿轻信网上广告!
 11款免费AI简历生成工具,轻松打造专业求职简历
11款免费AI简历生成工具,轻松打造专业求职简历 盘点12个夸克网盘电影免费播放观看
盘点12个夸克网盘电影免费播放观看 ControlFoley – 小米研究团队推出的统一可控型视频转音频生成框架
ControlFoley – 小米研究团队推出的统一可控型视频转音频生成框架 6款AI视频翻译与配音工具,一键生成多语言视频
6款AI视频翻译与配音工具,一键生成多语言视频 盘点8款高效AI搜索工具,助力智能信息检索
盘点8款高效AI搜索工具,助力智能信息检索 10款AI换脸工具,一键变身,轻松玩转创意视频
10款AI换脸工具,一键变身,轻松玩转创意视频 盘点8个欧美电影免费观看电视剧大全
盘点8个欧美电影免费观看电视剧大全 6款免费AI视频剪辑软件,智能自动编辑,省钱又高效
6款免费AI视频剪辑软件,智能自动编辑,省钱又高效 树枝上一只色彩斑斓的小鸟
树枝上一只色彩斑斓的小鸟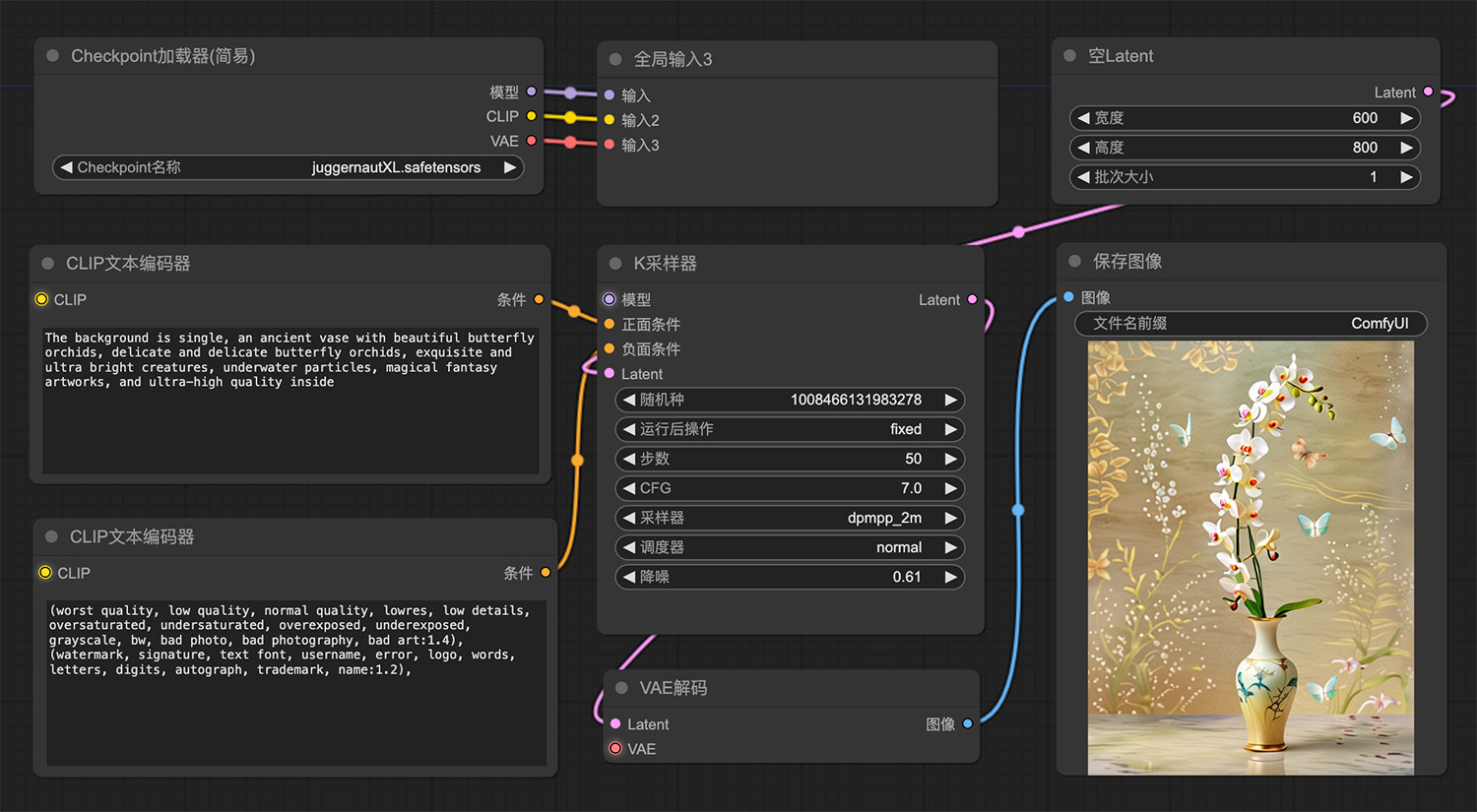 蝴蝶兰comfyui工作流
蝴蝶兰comfyui工作流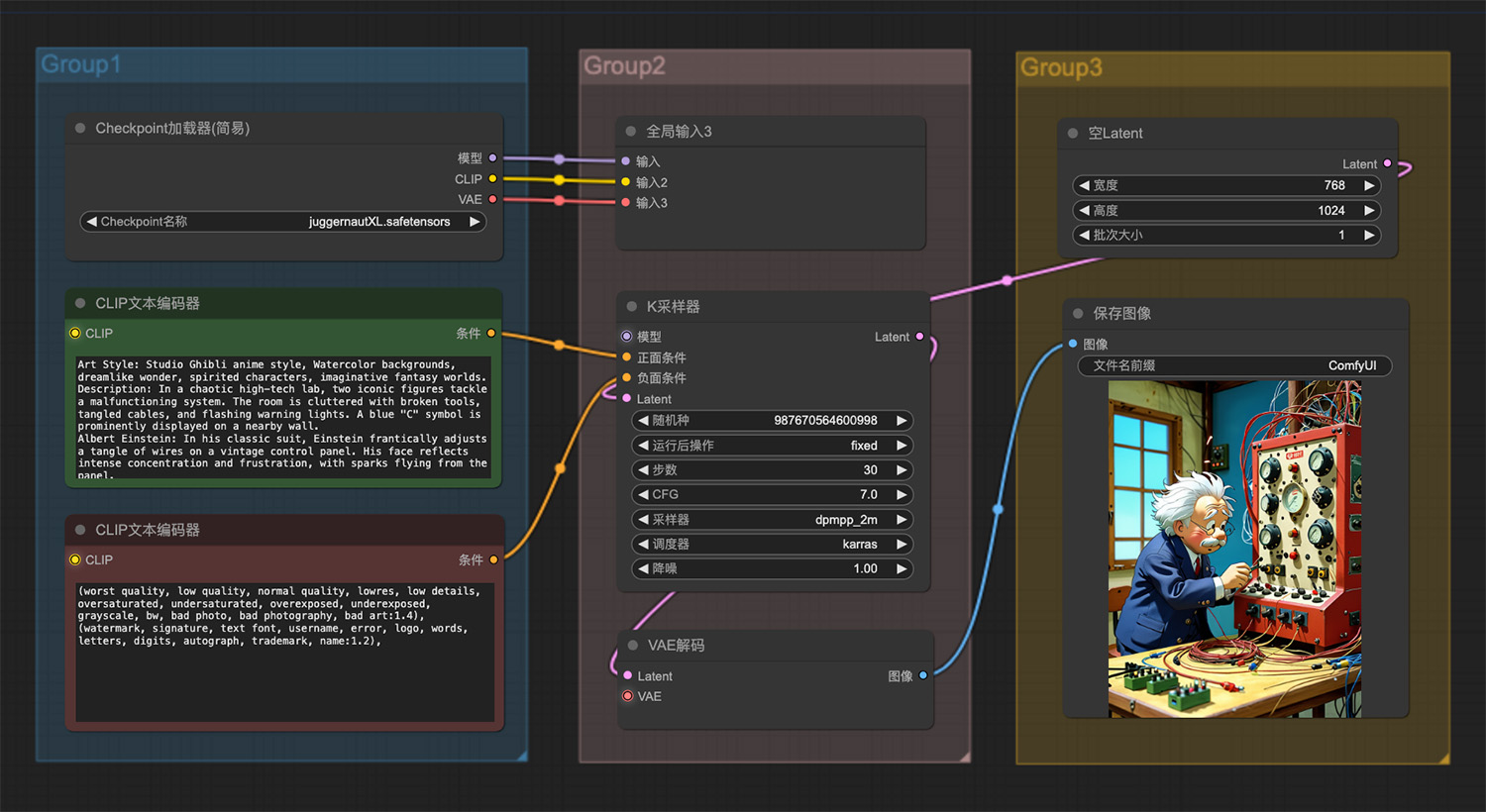 爱因斯坦在做实验3d动漫ComfyUI工作流
爱因斯坦在做实验3d动漫ComfyUI工作流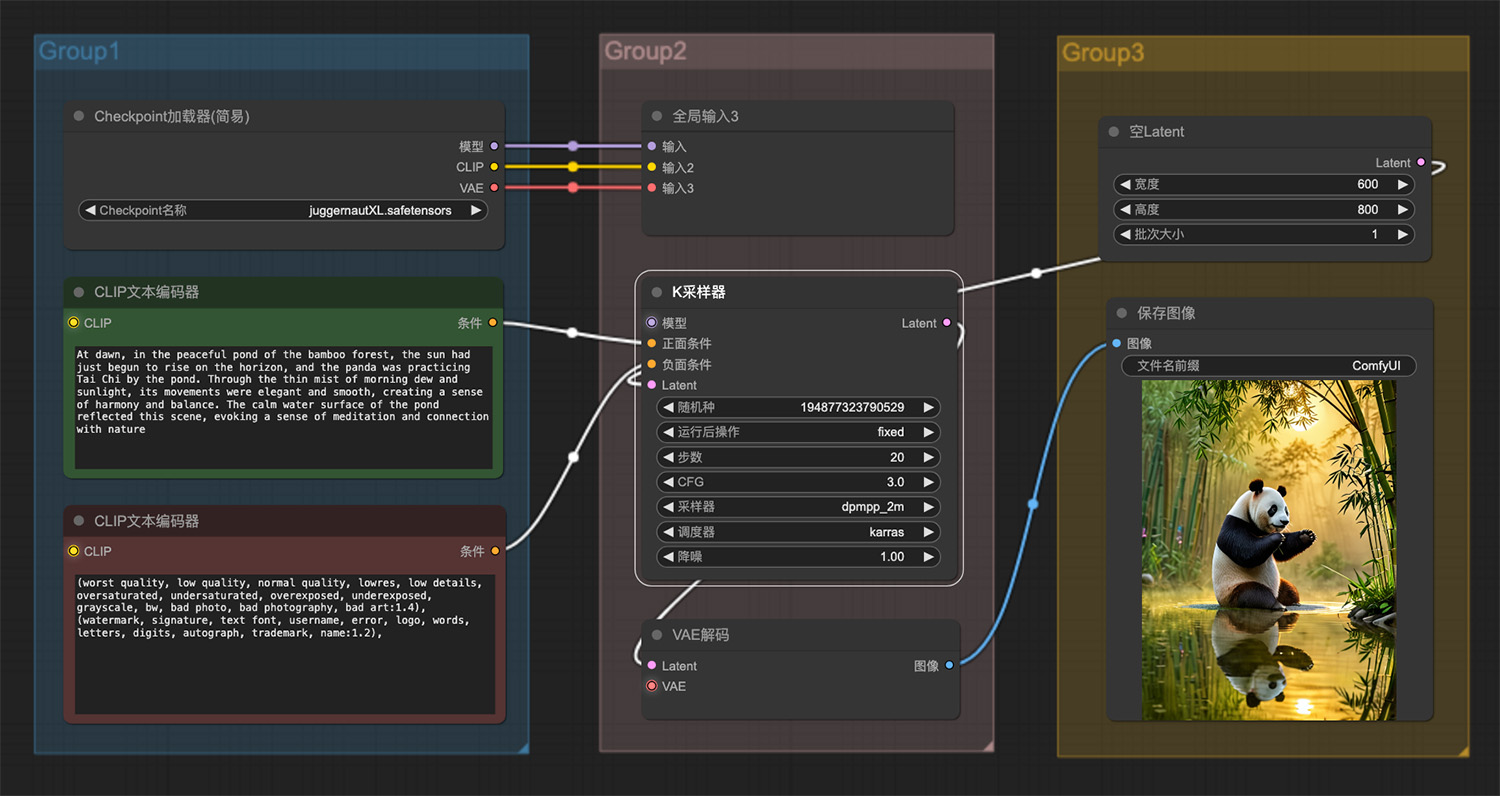 池塘边的大熊猫ComfyUI工作流
池塘边的大熊猫ComfyUI工作流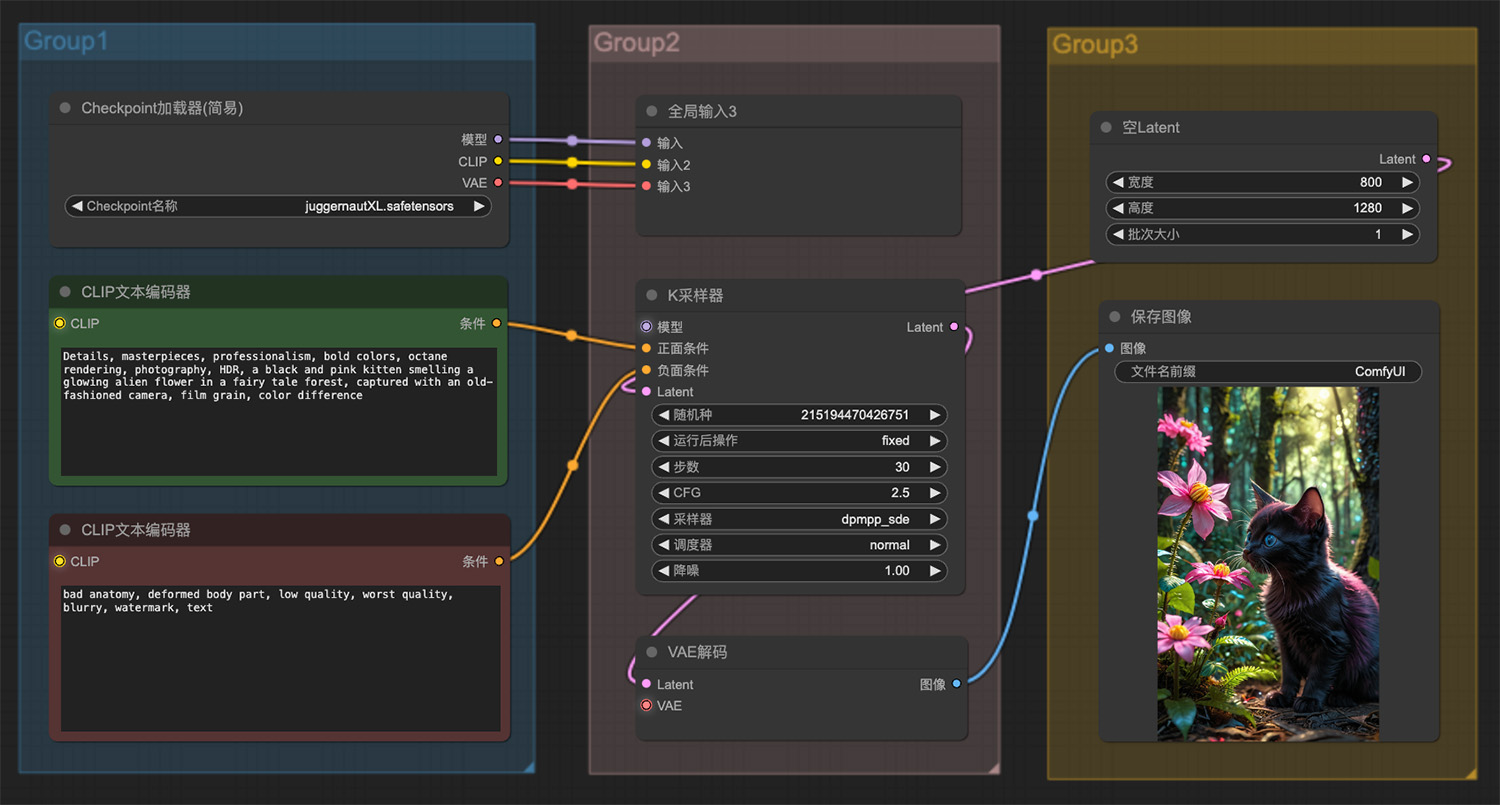 一只黑色的小猫在童话森林里嗅着一朵发光的外星花
一只黑色的小猫在童话森林里嗅着一朵发光的外星花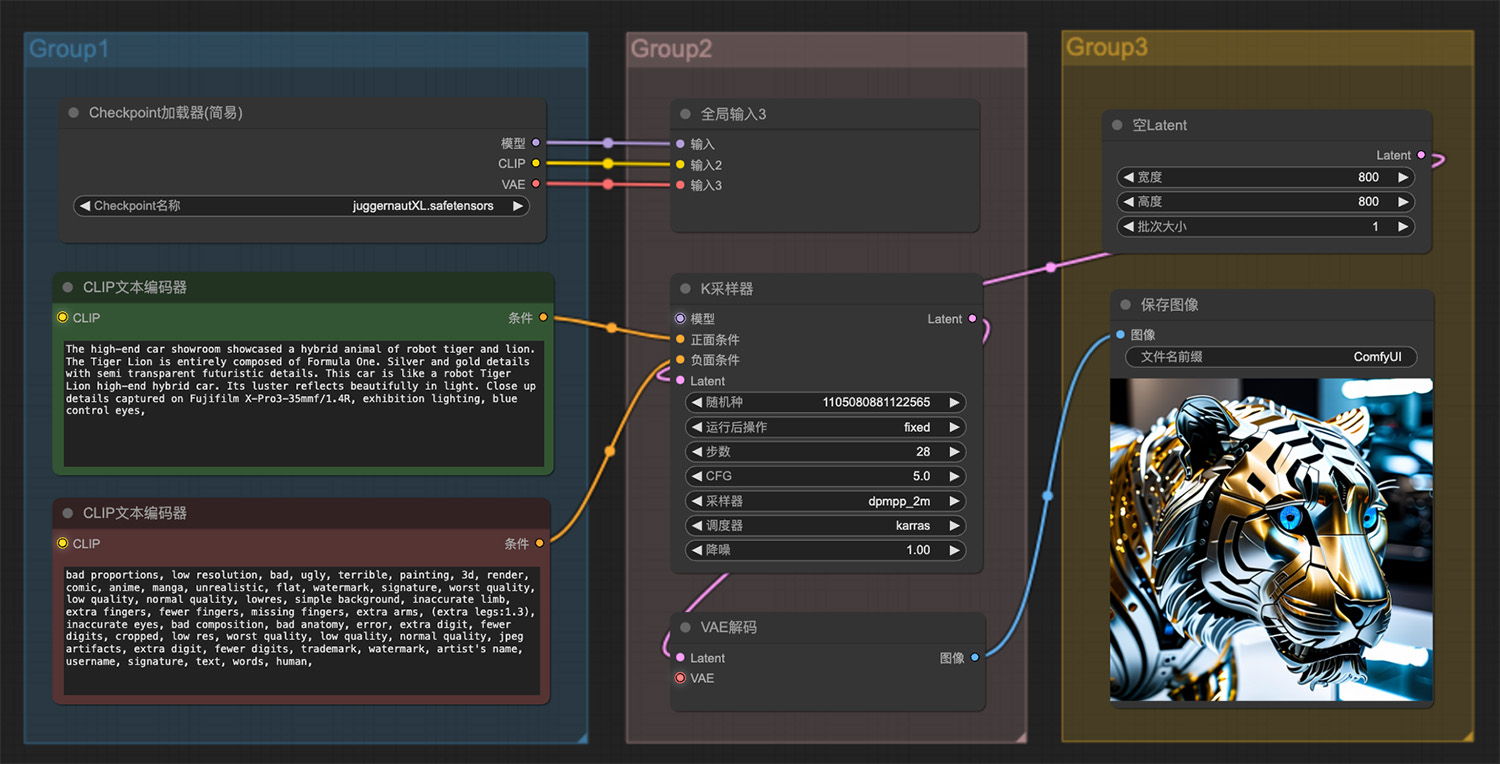 一辆机器人虎狮高端混合动力车ComfyUI工作流
一辆机器人虎狮高端混合动力车ComfyUI工作流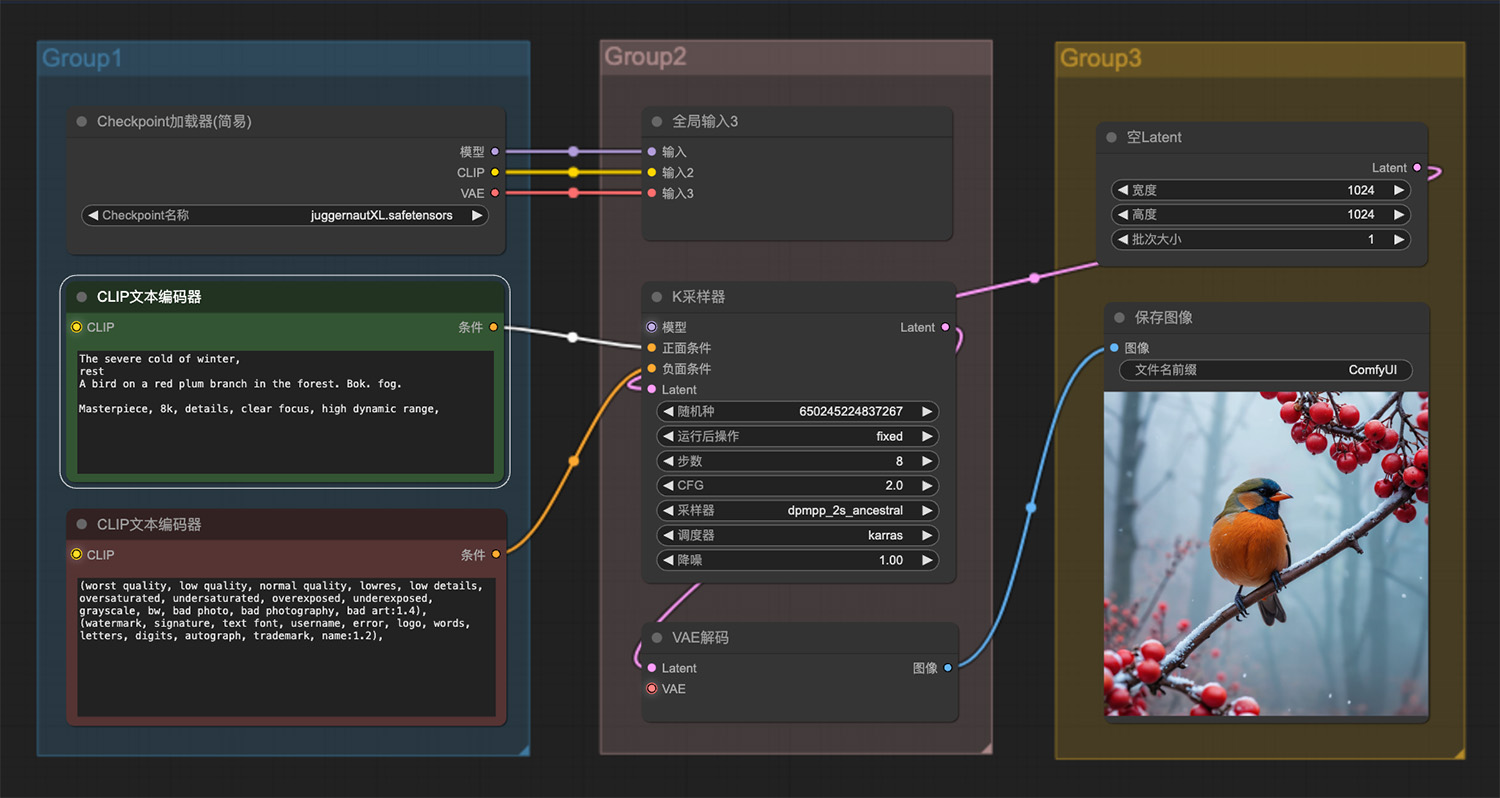 冬天的严寒里红梅枝上停留着一只鸟
冬天的严寒里红梅枝上停留着一只鸟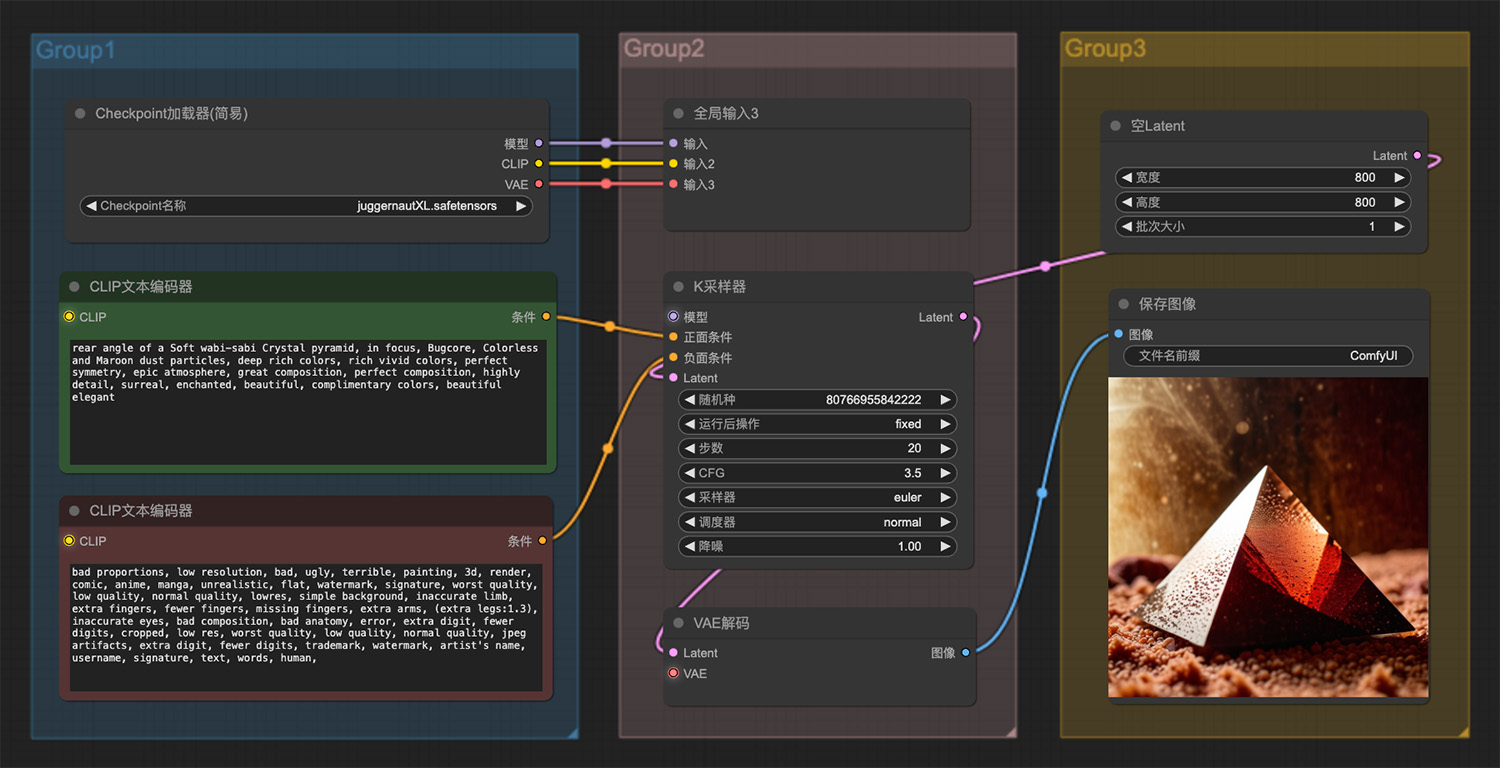 一颗柔和的水晶金字塔ComfyUI工作流
一颗柔和的水晶金字塔ComfyUI工作流 即梦AI绘画网页版
即梦AI绘画网页版 藏族日历小程序
藏族日历小程序
 JoyCode
JoyCode Webifier
Webifier 和鲸AI平台
和鲸AI平台 HTTPie AI
HTTPie AI OSS Insight
OSS Insight Strix
Strix ShowMeAI
ShowMeAI PPIO派欧云
PPIO派欧云 旷视AI平台
旷视AI平台 OpenCLI
OpenCLI Mintlify
Mintlify