ControlFoley – 小米研究团队推出的统一可控型视频转音频生成框架
ControlFoley是小米研究团队推出的统一可控型视频转音频生成框架,聚焦音视频算法研究,专门解决传统视频转音频(V2A)任务中跨模态冲突下文本可控性弱、参考音频时序与音色纠缠、风格控制不精准等行业痛点。模型可一站式实现文本引导、文本控制、参考音频风格迁移多模态视频配音,依托联合视觉编码、时间-音色解耦、模态鲁棒训练三大核心技术,大幅提升音视频语义对齐、时序同步与高保真音质表现,在多项权威评测基准上达到业界顶尖水平,综合性能媲美工业级视频音效生成系统。

ControlFoley项目地址:
1、项目官网入口:https://yjx-research.github.io/ControlFoley_web_page/
2、GitHub仓库:https://github.com/xiaomi-research/controlfoley
3、HuggingFace模型库:https://huggingface.co/YJX-Xiaomi/ControlFoley
4、arXiv技术论文:https://arxiv.org/abs/2604.15086
⚠️ GitHub仓库、HuggingFace模型库:受境外网络访问限制,暂无法正常打开
ControlFoley技术原理:
1、联合视觉编码范式:
融合CLIP模型与自研时空音视频编码器,强化音视频时空关联对齐能力,兼顾语义理解与音画时序同步效果,从底层提升文本指令的可控性。
2、时间-音色解耦设计:
剥离参考音频中冗余的时序干扰信息,精准保留独有音色特征,避免参考音频打乱视频原生动作节奏,实现风格可控不脱节。
3、模态鲁棒训练机制:
采用统一多模态表示对齐(REPA)+ 随机模态丢弃训练策略,适配视频、文本、参考音频多种输入组合,大幅提升跨模态语义冲突场景下的生成稳定性。
4、专属评测基准:
自建VGGSound-TVC评测基准,专门用于量化评估图文语义冲突场景下的模型文本可控能力,填补行业标准化评测空白。
ControlFoley主要功能:
1、文本引导视频配音:
输入视频+文字描述提示词,智能生成与画面动作高度同步的高保真环境音、动作音效,还原真实物理声场。
2、文本可控视频配音:
面对视频画面与文本指令语义冲突的场景,可优先遵循文本创作意图生成音效,同时严格保持音画时间轴同步。
3、参考音频可控配音:
以参考音频为风格模板做音色迁移,复刻指定声线、曲风、环境氛围,且不破坏视频原有动作时序节奏。
ControlFoley核心优势:
1、多任务统一框架:
单个模型全覆盖文本引导、文本控制、参考音频风格配音三类主流需求,无需切换多个工具。
2、跨模态强可控性:
攻克视觉与文本语义冲突难题,是少有的能在矛盾指令下仍保持精准意图理解的V2A模型。
3、音画时序高精度同步:
时空编码架构深度捕捉画面动作节奏,生成音效贴合画面动作卡点。
4、音色与时序解耦:
参考音频只决定音色风格,不干扰视频时序,创作自由度更高。
5、高保真物理声场还原:
支持文字生成自然环境音、乐器声、机械声、自然声响等各类真实世界音效,音质还原度高。
6、性能对标工业级:
在各类视频转音频任务中综合表现优异,可控性、同步性、音质均优于同类型开源模型。
ControlFoley使用流程:
1、资源获取:
可通过官方项目官网体验在线演示,技术论文可直接访问arXiv链接查阅;代码与模型权重仓库因境外访问限制暂无法访问。
2、环境部署:
参照官方技术文档配置Python运行环境,安装音视频处理、AI推理相关依赖库。
3、选定任务模式:
根据创作需求选择文本引导、文本控制、参考音频控制任一任务类型。
4、上传输入素材:
导入待配音视频;按需补充文本提示词,或上传用于风格参考的音频文件。
5、模型推理生成:
依托模型多模态对齐与时间-音色解耦能力,自动生成时序匹配、语义贴合的专属音效。
6、合成导出:
输出高保真音频轨道,与原视频合成,完成视频音效配音与后期微调。
ControlFoley应用场景:
1、短视频二创:
为无原声、素材片段定制化生成匹配文案与画面的专属音效,规避模型随机生成偏差。
2、动画/游戏制作:
为角色动作、场景环境定制打击音效、氛围音、特效音,统一作品听觉风格。
3、影视后期制作:
借助参考音频批量校准全片音效音色,保持系列作品听觉风格统一。
4、广告创意制作:
通过文本指令快速定制符合品牌调性、节奏卡点的背景音乐与环境音效。
5、自媒体与直播运营:
为直播切片、剧情剪辑视频补充沉浸式定制音效,提升内容质感与观看体验。
6、音频算法研究:
可为多媒体、计算机视觉、语音声学领域科研人员提供基准模型与评测方案。
标签:

 AGenUI模型 - 高德地图联合阿里千问C端开源的原生A2UI框架
AGenUI模型 - 高德地图联合阿里千问C端开源的原生A2UI框架 Mavis官网 - MiniMax Agent推出的多智能体协同工作模式
Mavis官网 - MiniMax Agent推出的多智能体协同工作模式 Xiaomi OneVL - 小米具身智能团队自研的开源自动驾驶大模型
Xiaomi OneVL - 小米具身智能团队自研的开源自动驾驶大模型 Webwright – 微软研究院开源的终端原生网页智能体框架
Webwright – 微软研究院开源的终端原生网页智能体框架 ControlFoley – 小米研究团队推出的统一可控型视频转音频生成框架
ControlFoley – 小米研究团队推出的统一可控型视频转音频生成框架 SenseNova-Skills – 商汤OpenSenseNova团队开源模块化AI办公技能库
SenseNova-Skills – 商汤OpenSenseNova团队开源模块化AI办公技能库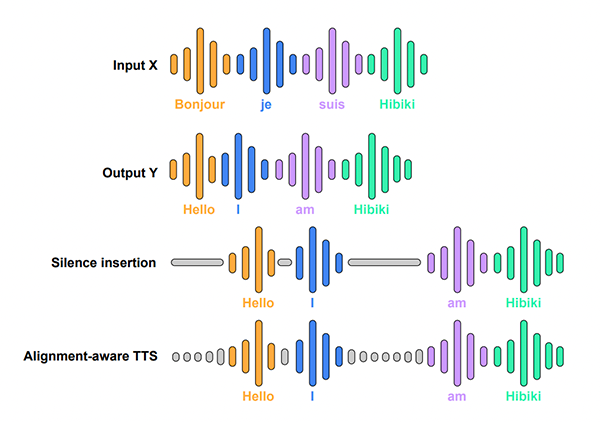 Hibiki:一款由Kyutai开发的实时同声传译语音模型
Hibiki:一款由Kyutai开发的实时同声传译语音模型 生成式人工智能服务管理暂行办法
生成式人工智能服务管理暂行办法 Fish Speech:一款开源文本转语音(TTS)工具
Fish Speech:一款开源文本转语音(TTS)工具 6款免费AI写作神器,一键生成文章、报告、公文、论文,高效又省心!
6款免费AI写作神器,一键生成文章、报告、公文、论文,高效又省心! 几款免费AI绘图工具,一键生成流程图与办公图表
几款免费AI绘图工具,一键生成流程图与办公图表热门工具
 Friday AI
Friday AI 小库AI云
小库AI云 企查猫(企业查询宝)
企查猫(企业查询宝) Tabbit Browser
Tabbit Browser 飞书智能会议纪要
飞书智能会议纪要热门标签
AI数字虚拟人二手交易音频工具体育频道新媒运营批量处理效率工具AI辅助工具ChatGPT投诉举报谷歌插件影视资源搜索引擎影音娱乐法律咨询