-
- AI开发助手SemanticAudio在AudioCaps、TTABench两大权威音频评测基准中,综合表现全面超越TangoFlux等主流方案,同步实现文本语义匹配度与音频生成音质双重突破。
爱站权重:


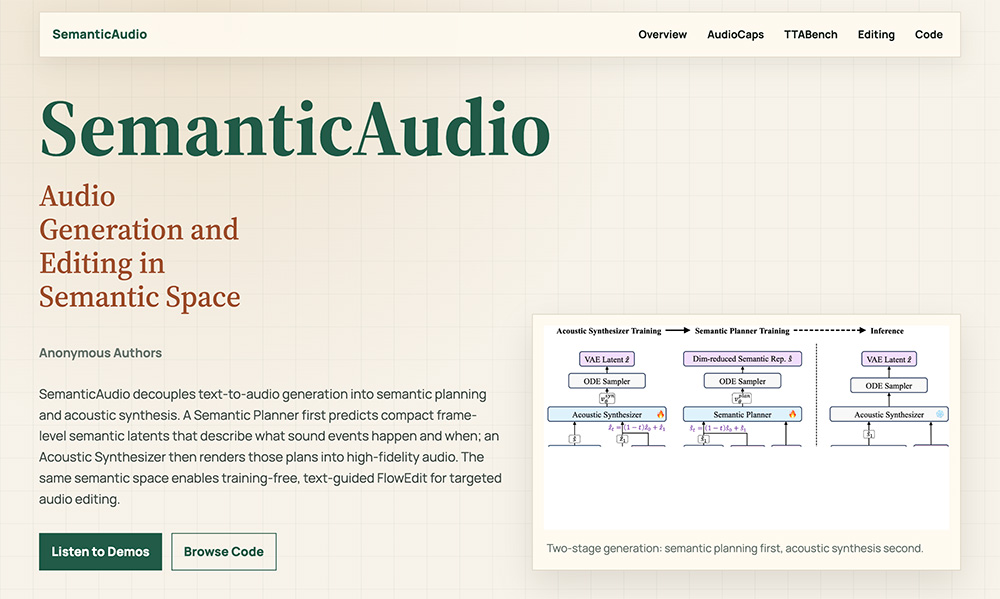
SemanticAudio是由香港中文大学、LIGHTSPEED、上海交通大学联合研发的新一代音频生成与编辑开源框架。框架创新将文生音频拆分为语义规划、声学合成双阶段流水线:
先在高层语义潜空间完成全部声音事件的类型、时序、场景结构全局规划,再交由声学模型渲染高保真波形音频;配套无训练成本的文本引导FlowEdit音频编辑能力。在AudioCaps、TTABench两大权威音频评测基准中,综合表现全面超越TangoFlux等主流方案,同步实现文本语义匹配度与音频生成音质双重突破。

一、产品核心功能:
1、通用文生音频生成:
输入自然语言描述,一键生成环境音、人物人声、物体动作音效、多层叠加复杂声场等高清音频素材
2、两阶段语义规划生成:
独立语义规划模块先行梳理全场景声音逻辑,再合成声学细节,解决多音效时序错乱、元素丢失问题
3、零训练文本驱动音频编辑:
依托FlowEdit ODE微分流机制,直接在语义空间完成音频修改,无需微调模型权重
4、帧级时序语义嵌入:
输出带完整时间维度的结构化语义表征,精准还原复杂音频内多声音事件的先后顺序与局部动态变化
二、产品核心优势:
1、文本语义匹配度大幅领先:
先全局语义布局再渲染波形,AudioCaps数据集CLAP-L指标达0.381,高于TangoFlux的0.361,长复杂提示词理解更精准
2、免训练可控编辑能力:
基于语义速度场实现音频属性定向修改,编辑后Delta CLAP提升至0.094,编辑效果优于同类方案且无需额外训练成本
3、高保真音质与强可控性平衡:
FD指标19.1、主观MOS评分3.72,在优化文本对齐效果的同时保留细腻真实的听觉质感
4、多事件复杂场景稳定生成:
显式建模多声音主体、时序先后逻辑,大幅减少音效缺失、顺序颠倒、图文语义错位等常见生成缺陷
5、贴合人类音频创作逻辑:
遵循“先搭建声场结构,再填充声学细节”的创作范式,模拟真人音频制作思考流程,可控性更强
三、快速使用步骤:
1、在线体验Demo:
访问官方演示页面 https://semanticaudio1.github.io/ 快速试用完整生成与编辑能力
2、输入场景提示词:
用自然语言完整描述目标混合声场,例如“犬吠声过后响起汽车鸣笛”
3、语义全局规划:
Semantic Planner 输出轻量化帧级语义潜向量,完成全场景声音事件时序、布局规划
4、高保真声学渲染:
声学合成器基于语义规划方案,输出完整高清48kHz音频波形
5、语义空间音频编辑(可选):
上传原始音频并输入修改目标文本,通过FlowEdit ODE在语义层定向调整声音主体、环境、音量、空间氛围等属性
数据统计
特别声明&浏览提醒
本站AI工具导航站提供的「SemanticAudio」的相关内容都来源于网络,不保证外部链接的准确性和完整性。在2026年07月04日 06时49分36秒收录时,该网站上的内容都属于合规合法,后期网站的内容如出现违规,可以直接联系网站管理员(ai@ipkd.cn)进行删除,AI工具导航站不承担任何责任。在浏览网页时,请注意您的账号和财产安全,切勿轻信网上广告!
 EICopilot:百度研究院推出的一款企业信息搜索与探索工具
EICopilot:百度研究院推出的一款企业信息搜索与探索工具 MoBA:一款提高大型语言模型(LLMs)处理长上下文任务的效率
MoBA:一款提高大型语言模型(LLMs)处理长上下文任务的效率 Pixal3D – 腾讯ARC实验室、清华等联合研发的单图像高精度3D成项目
Pixal3D – 腾讯ARC实验室、清华等联合研发的单图像高精度3D成项目 奈飞工厂免费Netflix影视资源的在线播放网址
奈飞工厂免费Netflix影视资源的在线播放网址 FlowGram:字节跳动开源的一款强大的前端流程搭建工具
FlowGram:字节跳动开源的一款强大的前端流程搭建工具 Gemini 3.1 Flash Live语音模型使用入口,Google推出的高质量实时语音交互模型
Gemini 3.1 Flash Live语音模型使用入口,Google推出的高质量实时语音交互模型 盘点7款主流AI训练模型:技术特性与应用场景解析
盘点7款主流AI训练模型:技术特性与应用场景解析 9款免费AI智能助手,聊天机器人开启智能生活!
9款免费AI智能助手,聊天机器人开启智能生活!
 即梦AI绘画网页版
即梦AI绘画网页版 阿里·通义千问网页版
阿里·通义千问网页版 藏族日历小程序
藏族日历小程序
 MagicForm
MagicForm TanStarter
TanStarter BrowserBash
BrowserBash 360安全大脑
360安全大脑 CodeFuse
CodeFuse
 彝族日历小程序
彝族日历小程序
 驭码 CodeRider
驭码 CodeRider 袋马daimax
袋马daimax TryCase
TryCase 易采集EasySpider
易采集EasySpider AdaL
AdaL