6款免费好用的AI文本转语音工具,智能合成超逼真配音
今天给大家介绍6款免费的AI文本转语音工具,一键智能合成,轻松满足你的配音需求!无论是制作视频、有声读物还是学习外语,这些工具都能帮你生成自然流畅、接近真人的语音。
1、免费在线文本转语音工具
2、声动视界SoundView
声动视界SoundView是国产一站式「AI音频+视频+图像」多模态创作云,一句话slogan:“上传一段声音,即刻生成声动大片。”面向短视频博主、广告制片、教育讲师、自媒体与广电机构,提供「文字→声音→画面→成片」全自动链路,10分钟完成传统团队3天的制作量。

声动视界SoundView核心功能:
1、AI配音:600+主播音色,覆盖中/英/日/韩/粤/川/东北等30种方言;情感、新闻、客服、纪录片、儿童故事等12种风格;单句可插入笑声、停顿、重读,媲美真人。
2、AI脚本:输入关键词或文章链接,自动拆镜、写口播、加BGM、配SFX,一键生成30-60秒短视频文案,支持热点榜单自动选题。
3、声音驱动视频:上传5-60秒音频→选择2D真人/3D卡通/漫画脸虚拟形象→自动生成口型、表情、头部动作,分辨率最高4K60fps。
4、AI视频生成:文本描述→生成5-15秒动态镜头;提供「镜头语言」开关(推拉摇移、景深、运动模糊),可无缝衔接实拍素材。
5、AI图像&海报:文本生成2K-8K海报、分镜、插画;内置200+行业模板(美食、科技、电商、教育),可一键套版替换商品图。
6、智能字幕&翻译:自动语音识别(ASR)→时间轴→字幕样式库;支持130种语言互译,双语字幕一键导出SRT/ASS/XML。
7、AI降噪&分离:一键去除环境噪声、口水音;伴奏/人声分离精度≥-26dB;支持批量上传ZIP。
8、数字人直播:提供OBS虚拟摄像头插件,把数字人实时推送抖音、B站、TikTok;支持弹幕驱动表情、礼物触发动作。
9、团队协作:云素材库、版本管理、在线审片、打点批注;权限颗粒度到「镜头级」;兼容PR/FCPXML导入导出。
10、API&SDK:开放REST&WebSocket,30行代码即可接入「文字→配音→数字人视频」;提供Python/Node.js/Java示例。
3、IndexTTS2
IndexTTS2是由B站(Bilibili)开发的自回归零样本语音合成模型,于2025年9月8日正式开源。IndexTTS2是首个支持精确时长控制的自回归TTS模型。支持零样本声音克隆,仅需一个音频文件即可精准复制音色、节奏和说话风格,支持多语言。IndexTTS2实现了情感音色分离控制,用户可以独立指定音色来源和情绪来源。
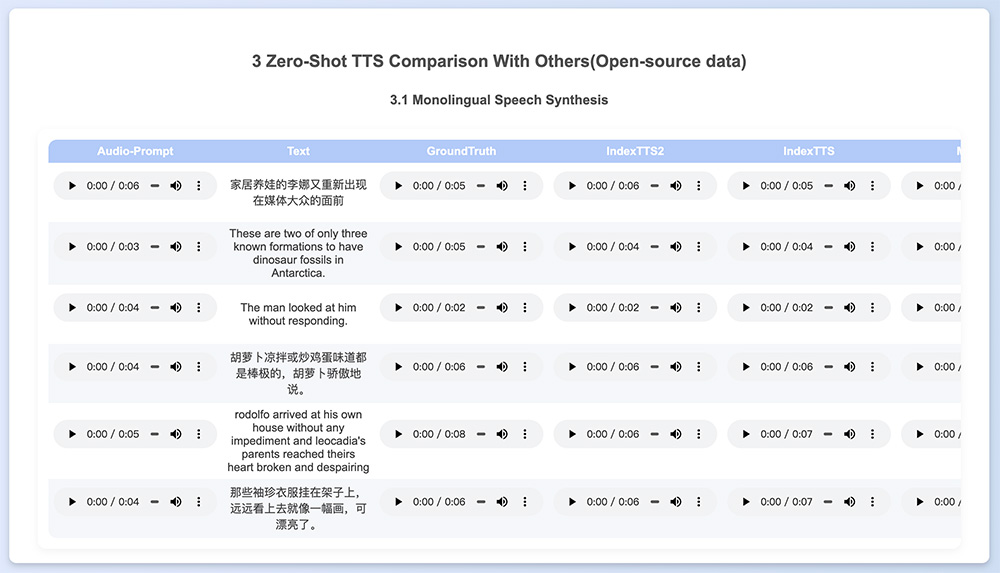
IndexTTS2相关网址链接:
1、项目官网:https://index-tts.github.io/index-tts2.github.io/
2、Github仓库:https://github.com/index-tts/index-tts
3、HuggingFace模型库:https://huggingface.co/IndexTeam/IndexTTS-2
4、arXiv技术论文:https://arxiv.org/pdf/2506.21619
IndexTTS2功能特点
1、精确时长控制:首次在自回归架构中实现了精准时长控制,支持两种生成模式。一种可通过明确指定生成的token数实现精确时长控制,另一种则自由生成,保持输入提示的韵律特征。这使得IndexTTS2特别适合视频配音等需严格音画同步的应用场景。
2、情感音色分离控制:实现了情感特征与说话人音色的解耦,用户可以独立指定音色来源和情绪来源。例如,可以用一段音频保留音色,再用另一段不同情感的音频或文本描述赋予情绪,在零样本条件下,模型能精准还原目标音色并完全重现指定情绪。
3、多模态情感输入:支持多种情感输入方式,包括音频情感参考、文本情感描述、情感向量精确控制等,用户可以根据需要选择合适的方式进行情感控制。
4、高情感表达下的语音清晰度提升:引入了GPT潜在表示,并设计了三阶段训练策略,增强了生成语音的稳定性和清晰度。
5、基于文本的情感控制:通过微调Qwen3模型,实现了“软指令”机制,允许用户通过自然语言描述来直观控制情绪方向,降低了使用门槛。
6、强大的技术性能:在多数据集实验中,IndexTTS2在词错率、说话人相似度和情绪保真度上均超越了当前最先进零样本TTS模型。
4、UnifiedTTS
UnifiedTTS是一个一站式文本转语音(TTS)API服务平台,旨在帮助开发者快速集成多种主流的语音合成服务。通过统一的API接口,UnifiedTTS 整合了包括 Microsoft Azure、MiniMax、阿里云和 ElevenLabs 等在内的多家主流TTS服务提供商。开发者无需分别研究不同供应商的API文档,只需通过UnifiedTTS的单一接口,即可接入这些服务。

UnifiedTTS功能特点:
1、统一接口:一个接口连接所有 TTS 服务,无需研究各供应商的 API 文档,显著节省开发时间和集成成本。
2、统一参数:提供标准化参数,自动转换为对应供应商的格式,解决不同 TTS 接口参数不一致的问题。
3、统一管理:无需注册多个供应商账户,一站式管理 API 密钥和账单。
4、多语言支持:支持中文、英文、日文、韩文等多种语言,满足全球业务需求。
5、灵活切换:简单更改参数即可在不同供应商模型之间切换,提供多种语音和风格选项,可根据业务需求灵活切换到最适合的语音服务。
6、性能监控:实时监控供应商响应速度和质量,提供详细的使用统计和性能报告,实现服务的完全可视化。
UnifiedTTS使用方法:
1、一键登录:访问 [UnifiedTTS 官网],免费注册账号并登录,即可获得试用积分。
2、获取 API 密钥:在用户仪表盘中生成专属的 API 密钥,用于后续的 API 调用。
3、开始调用:使用 UnifiedTTS 提供的 API,结合获取的 API 密钥,开始进行语音合成调用。
5、FireRedTTS-2
FireRedTTS-2是由小红书开源的一款面向多说话者对话生成的长篇流式文本转语音(TTS)系统,旨在提供稳定、自然的语音输出,同时实现可靠的说话人切换和语境感知的韵律。该系统在支持多语言、实现超低延迟方面取得了显著突破,使其成为长对话、实时交互场景的理想选择。
FireRedTTS-2项目资源:
1、GitHub仓库:https://github.com/FireRedTeam/FireRedTTS2
2、项目官网:https://fireredteam.github.io/demos/firered_tts_2/
3、arXiv技术论文:https://arxiv.org/pdf/2509.02020v1
FireRedTTS-2核心功能:
1、长对话语音生成能力:支持生成长达3分钟的四说话者对话,并可通过扩展训练语料轻松扩展至更长、更多说话者的对话场景。这为多角色叙事和复杂场景模拟提供了可能。
2、广泛的多语言支持:支持英语、中文、日语、韩语、法语、德语和俄语等多种语言。同时,它还支持零样本(zero-shot)语音克隆,可应用于跨语言及语码转换(code-switching)场景。
3、超低延迟流式生成:基于新型12.5Hz流式语音分词器和双Transformer架构,实现了灵活的逐句生成,显著降低了首包延迟。在L20 GPU上,其首包延迟可低至140ms,同时保持高质量音频输出。
4、卓越的稳定性与音质:在独白和对话测试中,展现出高相似度、低词错误率(WER)/字符错误率(CER)的强大稳定性,确保了生成语音的清晰度和自然度。
5、随机音色生成功能:提供随机音色生成能力,这对于创建大量多样化的自动语音识别(ASR)或语音交互训练数据,具有极高的实用价值。
FireRedTTS-2应用场景:
2、播客与有声内容生成:用于制作多说话人、多语言的播客和长篇有声读物。
3、智能聊天机器人与虚拟助手:为聊天框架集成提供实时、富有情感和上下文感知的语音交互。
4、语音克隆与定制化声音:支持零样本语音克隆,用于生成与目标说话人高度相似的语音。
5、语音交互系统开发:提供多样化的测试素材和随机音色生成,满足不同场景的语音交互需求。
6、多语言客服与国际会议:适用于需要多语言支持的语音应用,如国际化服务。
6、AI speaker
AI Speaker是一款基于微软 TTS 服务的在线文字转语音(TTS)工具,能够将文字即时转换为自然流畅的语音。它支持多种语言和声音选择,提供高度拟人的情感表达,适用于多种场景。
AI Speaker功能特点:
1、多语言与多声音支持:
- 支持超过100种语言和600多种AI声音。
- 同一声色支持中英双语,多语言混读衔接自然流畅。
2、自定义语音效果:
- 用户可以调整语速、音调和音量,以满足不同需求。
3、多种客户端支持:
- 支持网页端、浏览器插件和移动APP,实现多端同步。
4、文本合成语音并转换成MP3:
- 支持导出整段合成的音频,也可导出每个段落的音频。
5、多种AI主播:
- 提供320多位AI主播,满足不同风格需求。
6、免费使用与商业用途支持:
- 免费版本支持每次合成5000字以内,VIP版本支持更长文本。
- 合成的音频文件拥有100%版权,可用于商业用途。

基金从业资格考试题库
一站式备考基金从业资格考试,收录2021-2025年模拟题库!
 亚马逊全球网点布局大盘点(包括所有开店流程)
亚马逊全球网点布局大盘点(包括所有开店流程) eMAG全球3大国际站大盘点
eMAG全球3大国际站大盘点 美客多全球6大国际站大盘点
美客多全球6大国际站大盘点 盘点12款免费的PDF在线转换工具
盘点12款免费的PDF在线转换工具 盘点12个夸克网盘电影免费播放观看
盘点12个夸克网盘电影免费播放观看 2025年最新电影免费看
2025年最新电影免费看 最近韩国电影片在线观看
最近韩国电影片在线观看 5款免费AI商拍工具,一键生成爆款商品图
5款免费AI商拍工具,一键生成爆款商品图 盘点8款高效AI搜索工具,助力智能信息检索
盘点8款高效AI搜索工具,助力智能信息检索 热门的ai老照片修复软件有哪些 2025高人气Ai绘图软件排行
热门的ai老照片修复软件有哪些 2025高人气Ai绘图软件排行 12款网盘工具,谁才是你的存储神器?
12款网盘工具,谁才是你的存储神器? 几款免费AI 3D模型生成工具,快速制作逼真三维模型!
几款免费AI 3D模型生成工具,快速制作逼真三维模型! 7个AI智能体平台,让AI应用开发变得简单又高效
7个AI智能体平台,让AI应用开发变得简单又高效 5款免费AI面试助手,助力求职笔试与面试轻松通关
5款免费AI面试助手,助力求职笔试与面试轻松通关 11款热门AI音乐生成工具,国内外免费资源大推荐!
11款热门AI音乐生成工具,国内外免费资源大推荐!热门工具
 十行笔记
十行笔记 3Dpresso
3Dpresso TwitterXDownload视频下载
TwitterXDownload视频下载 Ludo.ai
Ludo.ai 配音神器Pro
配音神器Pro最新工具
 模力漫
模力漫 YouWear
YouWear 岩芯数智
岩芯数智 DreaMoving
DreaMoving instaVerse
instaVerse热门标签
生活服务国产AI影视名站AI金融事务实用工具创意设计短剧搜索AI三维生成体育频道电影下载ppt模板AI制作PPT编程工具学习大语言模型在线教育平台媒体运营小说文学教师必备查询检测