8个免费的大语言模型工具和软件
1、OpenAI
OpenAI是一家非营利/限额营利(capped-profit)混合体,致力于研发安全、对齐、普惠的通用人工智能(AGI)。通过访问OpenAI官网,用户可以了解如何注册账号并使用OpenAI的API接口,这些接口允许开发者与OpenAI的先进语言模型(如GPT-3和GPT-4)进行交互,应用于多种场景如文本生成、摘要、翻译和问答等。
OpenAI核心技术栈:
1、大语言模型(LLM):
- GPT-4o/GPT-4 Turbo:多模态(文本+图像+音频)生成与理解。
- GPT-3.5 Turbo:低成本、高并发对话接口。
- 上下文长度最高 128k token,支持函数调用、插件、检索增强(RAG)。
2、多模态生成:
- DALL·E 3:文本→高清图像,支持 4×、16× 超分、局部编辑。
- Whisper:语音→文本,支持 99 种语言、时间戳、翻译。
- TTS:文本→自然语音,6 种音色,实时流式输出。
3、代码与工具:
- Codex:自然语言→代码,支持 40+ 语言,GitHub Copilot 即基于其微调。
- Function Calling:让模型调用外部 API,实现“对话即服务”。
- Code Interpreter / Advanced Data Analysis:内置沙箱 Python 环境,可跑 pandas、matplotlib、scikit-learn。
4、部署与性能:
- 全球边缘节点 200+,首 token 时延 < 100 ms。
- 弹性并发:默认 10k TPM,可秒级扩容至百万级。
- 隐私合规:SOC 2 Type II、ISO 27001、GDPR、中国跨境传输认证(CBDT)。
OpenAI平台特点:
1、通用能力领先:持续霸榜多个 NLP、多模态基准(MMLU、HumanEval、HEIM)。
2、开发者友好:REST、Python、Node、Go、C#、Rust、Unity 官方 SDK;在线 Playground 即调即用。
3、按需计费:Token 级精度,输入+输出双向计费;提供 $5 免费额度,学生包 $20。
4、插件生态:ChatGPT Plugins、Actions、GPTs Store,可上架自定义应用。
5、企业级控制:数据不用于训练、可自定义数据驻留(US/EU/Asia)、私有 Azure OpenAI 服务。
6、安全对齐:RLHF + RLAIF、多模态红队、Moderation API,输出违规概率 < 0.1%。
7、开源历史:曾开源 GPT-2、CLIP、Whisper、Triton、Point-E 等,社区影响力大。
OpenAI典型应用场景:
1、对话与搜索:ChatGPT、Bing Chat、Perplexity。
2、内容创作:营销文案、SEO 文章、AI 绘图、短视频脚本。
3、开发辅助:IDE 插件(GitHub Copilot)、代码评审、单元测试生成。
4、数据分析:自然语言→SQL、Excel 公式、Python 可视化。
5、教育:个性化答疑、论文润色、口语对话评分。
6、企业流程:智能客服、知识库问答、合同审查、会议纪要。
官方网址:https://openai.com/zh-Hans-CN/
2、JuheNext
JuheNext是一个统一的大模型API聚合平台,提供简单、高效的接口,支持多种先进的AI模型,包括自然语言处理、图像生成、语义搜索和语音识别等功能。
JuheNext功能特点:
1、多模型支持:JuheNext支持超过200个大模型,包括OpenAI、Gemini、Anthropic、DeepSeek、Qwen等。
2、统一接口:提供标准化的API接口,方便开发者快速集成和调用。
3、高性能:支持高并发请求,处理速度超过100,000RPM。
4、无需VPN:提供无缝的全球网络连接,无需使用VPN。
5、高可用性:提供99%的企业级API可用性服务。
6、快速调用:通过简单的API调用,可以快速生成对自然语言提示的人类化响应、创建用于语义搜索的向量嵌入,以及从文本描述生成图像。
7、多语言支持:支持多种语言的文档和内容生成。
8、灵活部署:支持本地部署和云端部署,满足不同用户的需求。
3、靠谱AI
靠谱AI是一款集成了国内顶尖AI大模型的多功能平台,包括文心一言4.0、智谱AI、MiniMax、腾讯混元、讯飞星火、通义千问等多家主流大模型。它通过多模型切换和比较功能,为用户提供即时答案、多轮对话、创意绘画、文本创作、编程辅助、问题解答、图像生成等多种服务。
靠谱AI+DeepSeek官方网址入口:https://chats.kaopuai.com/gaokao/examination/talk

靠谱AI功能特点:
1. 多模型聚合:靠谱AI整合了多种通用和垂直大模型,用户可以根据需求选择不同的AI模型进行交互,如文心一言4.0、智谱AI等。
2. 多模态功能:平台支持创意绘画、文本创作、编程辅助、问题解答、图像生成等功能,能够满足用户在学术科研、互联网运营、创意设计、法律事务等领域的多样化需求。
3. 个性化服务:用户可以通过多轮对话与AI机器人互动,获取即时答案或满意的作品。平台还提供个性化推荐和设置功能,帮助用户优化使用体验。
4. 零代码AI机器人创建:靠谱AI支持零代码创建AI机器人,用户无需编程基础即可快速定制化AI助手,用于客服、数字员工等场景。
5. 高效学习与工作辅助:平台内置了高考志愿填报规划、心理健康支持等垂直领域应用,帮助用户在学习和工作中提高效率。
6. 隐私保护与安全:靠谱AI注重用户数据隐私保护,采用先进的算法技术确保用户信息安全。
7. 免费使用与便捷性:靠谱AI是一款免费的AI大模型聚合平台,支持PC端和移动端使用,界面简洁,操作便捷。
8. 社区与互动:平台未来计划增加AIGC角色机器人社区功能,进一步丰富用户互动体验。
靠谱AI应用场景:
- 学术科研:快速检索文献、生成科研数据。
- 互联网运营:市场分析、内容创作。
- 创意设计:图像生成、创意绘画。
- 教育辅导:课程辅导、学习规划。
- 法律事务:文书撰写、法律咨询。
- 个人生活:健康支持、心理咨询。
4、YAYI-Ultra:中科闻歌研发的
YAYI-Ultra(雅意)是由中科闻歌研发的企业级大语言模型的旗舰版本。它具备强大的多领域专业能力和多模态内容生成能力,支持数学、代码、金融、舆情、中医、安全等多个领域的专家组合。YAYI-Ultra 旨在为企业提供高精度、低能耗的智能化解决方案,缓解垂直领域迁移中的“跷跷板”现象。
YAYI-Ultra功能特点:
1、多领域专业能力:
- 支持数学、代码、金融、舆情、中医、安全等多个领域的专家组合。
- 深度增强安全、金融、媒体、舆情等领域的专业能力,并覆盖法律、中医等多业务场景。
2、多模态内容生成:
- 支持图文并茂的输出,能根据用户的问题从知识库中提取相关信息,同步给出对应的图片内容。
- 1000万+图文数据对齐,支持内容理解、审核、抽取等30+能力。
3、超长文本处理:
- 支持最长128k的输入和更长的上下文窗口。
- 支持最长20万字输入和10万字超长输出,形成从“输入理解”到“内容创作”的全链路长文本能力闭环。
4、复杂任务智能规划:
- 增强了多工具串行调用场景下的规划合理性,能将复杂任务拆解为多个子任务。
- 支持搜索引擎、代码解释器、图像解析等基础工具,以及新闻热榜追踪、传播影响力分析等垂直领域工具。
5、联网智能创作:
- 支持联网收集信息完成创作,例如写一篇关于中国儒家文化发展历史的分析报告。
6、内容安全风控:
- 实现人类价值观对齐,支持流式内容实时审核、诱导性拒识。
7、智能插件调用:
- 支持10+智能插件调用,可根据用户输入自动化选择插件,支持自定义插件库。
- 支持搜索引擎、PDF解析、计算器、天气、AI绘画、数字人等插件。
8、多语言支持:
- 支持10+语种,多语言能力提升。
9、数据分析与可视化:
- 能准确完成数据分析、计算和图表绘制任务。
YAYI-Ultra应用场景:
1、媒体领域:帮助客户将内容创作时间缩短30%-50%,内容发布频率提升20%-40%,内容差错率从5%降至0.5%左右。
2、医疗领域:基于YAYI的大医金匮中医大模型,可精准诊断500余种常见病症,辨证推理准确率高达90%。
3、财税领域:基于YAYI的财税知识大模型,模型回答准确率90.1%,支持24小时不间断的咨询服务。
YAYI-Ultra项目地址:
1、GitHub 仓库:https://github.com/wenge-research/YAYI2
2、HuggingFace 模型库:https://huggingface.co/wenge-research
5、VideoCaptioner
VideoCaptioner(卡卡字幕助手)是一款基于大语言模型(LLM)的智能视频字幕处理工具,旨在简化视频字幕的生成与优化流程。它支持语音识别、字幕断句、优化、翻译及视频合成的全流程处理,无需高性能 GPU 即可运行,操作简单高效。
VideoCaptioner功能特点:
1、语音识别:
- 支持多种语音识别引擎,包括在线接口(如B接口、J接口)和本地Whisper模型(如WhisperCpp)。
- 提供多种语言支持,支持离线运行,保护用户隐私。
- 支持人声分离和背景噪音过滤,提升语音识别的准确率。
2、字幕断句与优化:
- 基于大语言模型(LLM)进行智能断句,将逐字字幕重组为自然流畅的语句。
- 自动优化专业术语、代码片段和数学公式格式,提升字幕的专业性。
- 支持上下文断句优化,结合文稿或提示进一步提升字幕质量。
3、字幕翻译:
- 结合上下文进行智能翻译,确保译文准确且符合语言习惯。
- 采用“翻译-反思-翻译”方法论,通过迭代优化提升翻译质量。
- 支持多种语言的翻译,满足不同用户需求。
4、字幕样式调整:
- 提供多种字幕样式模板,如科普风、新闻风、番剧风等。
- 支持多种字幕格式(如SRT、ASS、VTT、TXT),满足不同平台需求。
- 支持自定义字幕位置、字体、颜色等样式设置。
5、视频字幕合成:
- 支持批量视频字幕合成,提升处理效率。
- 支持字幕最大长度设置和末尾标点,去除确保字幕美观。
- 支持关闭视频合成,仅生成字幕文件。
6、多平台视频下载与处理:
- 支持国内外主流视频平台(如B站、YouTube)的视频下载。
- 支持自动提取视频原有字幕进行处理。
- 支持导入Cookie信息,下载需要登录的视频资源。
官方网址:https://github.com/WEIFENG2333/VideoCaptioner
6、Kimi k1.5:MoonshotAI 开发的多
Kimi K1.5是一款由Moonshot AI推出的多模态思考模型,于2025年1月发布。这款模型在多模态推理、数学、代码生成和视觉理解等领域表现卓越,

Kimi K1.5功能特点和技术亮点:
1. 多模态能力:
- Kimi K1.5是一款多模态AI模型,能够同时处理文本、图像和代码等多种数据类型,支持联合训练和推理。
- 在短链思维模式(short-CoT)下,Kimi K1.5的数学、代码和视觉多模态能力超越了全球领先的SOTA模型GPT-4o和Claude 3.5 Sonnet,领先幅度高达550%。
- 在长链思维模式(long-CoT)下,Kimi K1.5的推理能力达到了OpenAI的o1正式版水平,实现了与OpenAI模型的全面对标。
2. 强大的推理能力:
- Kimi K1.5采用了强化学习(RL)技术,通过长上下文扩展(最大支持128k tokens)和部分展开(Partial Rollout)技术,显著提升了推理效率和准确性。
- 在多个基准测试中,Kimi K1.5展现了卓越的推理能力:
- 在AIME测试中,短链模式下得分为60.8分,超越了GPT-4o和Claude 3.5 Sonnet。
- 在MATH 500、Codeforces等测试中,Kimi K1.5表现优于其他主流模型。
- 在视觉任务中,Kimi K1.5在图像生成和复杂视觉任务中表现优异,甚至接近人类水平。
3. 技术创新:
- 长短期思维链技术(Long2Short) :Kimi K1.5将长链思维模式的推理优势迁移到短链模式,从而在资源有限的情况下保持高效推理。
- 强化学习框架:通过在线镜像下降法、采样策略优化和长度惩罚机制,Kimi K1.5实现了高效的模型训练和推理。
- 部分展开技术:通过减少计算资源消耗,Kimi K1.5在推理过程中实现了更高的效率和更低的延迟。
4. 开源与免费使用:
- Kimi K1.5是开源的,开发者可以通过API访问模型,并根据需求定制特定功能。
- 模型提供免费使用权限,支持实时搜索、文件分析(如PDF、Word文档等)以及图像到代码转换等功能。
5. 应用场景:
- 学术研究:Kimi K1.5在数学推理、编程和视觉任务中表现出色,适用于学术研究和教育领域。
- 商业应用:其强大的多模态处理能力使其在金融、医疗、教育、内容创作等领域具有广泛的应用潜力。
- 用户体验:Kimi K1.5支持多语言处理,并计划推出移动版本,进一步提升用户可访问性和便捷性。
6. 性能对比:
- 在短链模式下,Kimi K1.5超越了GPT-4o和Claude 3.5 Sonnet,领先幅度达550%。
- 在长链模式下,Kimi K1.5的表现接近OpenAI的o1正式版。
7. 其他亮点:
- Kimi K1.5还具备强大的图像理解能力,在AIME测试中取得了74.9分的高分。
- 模型支持实时跨100多个网站的搜索功能,并能分析多达50个文件。
7、MILS:一款由Meta AI推出的一
MILS(Multimodal Iterative LLM Solver)是由Meta AI推出的一种零样本(zero-shot)多模态任务解决方案。它通过迭代反馈机制,利用大语言模型(LLM)作为生成器(Generator)提出候选方案,并使用现成的多模态模型(如CLIP)作为评分器(Scorer)对方案进行评估和反馈,最终生成高质量的解决方案。

MILS功能特点:
1、零样本多模态描述:MILS能够在无需任何任务特定数据策展或训练的情况下,为图像、视频和音频生成高质量的描述内容。
2、生成器(Generator):使用LLM建模,接收任务描述文本和来自评分器的反馈评分,生成候选输出。输出不限于文本,可以引导后续模型生成其他模态数据(如图像)。
3、评分器(Scorer):对生成器生成的候选方案进行评分,评估其与测试样本的匹配程度。可以采用多种实现方式,如低级图像处理函数或经过训练的机器学习模型(如CLIP)。
4、无梯度优化:作为一种无梯度优化方法,MILS不需要通过反向传播进行训练,而是通过评分和反馈机制逐步改进输出结果。
5、多步推理与迭代优化:基于LLM的多步推理能力,MILS首先提示LLM生成多个候选输出,每个候选输出会被评分,通过迭代反馈的方式不断优化,最终生成最优的任务解决方案。
6、多模态嵌入逆向映射:MILS能够将多模态嵌入逆向映射为文本,实现跨模态算术等复杂应用。
MILS应用场景:
1、图像、视频和音频描述生成:MILS在图像、视频和音频的描述任务上均取得了强劲的性能,能够生成高质量的描述内容。
2、图像生成与编辑:通过优化提示词,MILS能够提升图像生成和编辑的质量,例如风格迁移等任务。
MILS项目地址:
1、GitHub仓库:https://github.com/facebookresearch/MILS
2、arXiv技术论文:https://arxiv.org/pdf/2501.18096
8、LalaEval:香港中文大学和货
LalaEval 是由香港中文大学和货拉拉数据科学团队共同推出的一个面向特定领域大语言模型(LLMs)的人工评估框架。该框架通过一套完整的端到端协议,涵盖领域规范、标准建立、基准数据集创建、评估规则构建以及评估结果的分析和解释。LalaEval 核心特点是通过争议度和评分波动分析,自动纠正人工主观错误,生成高质量的问答对。
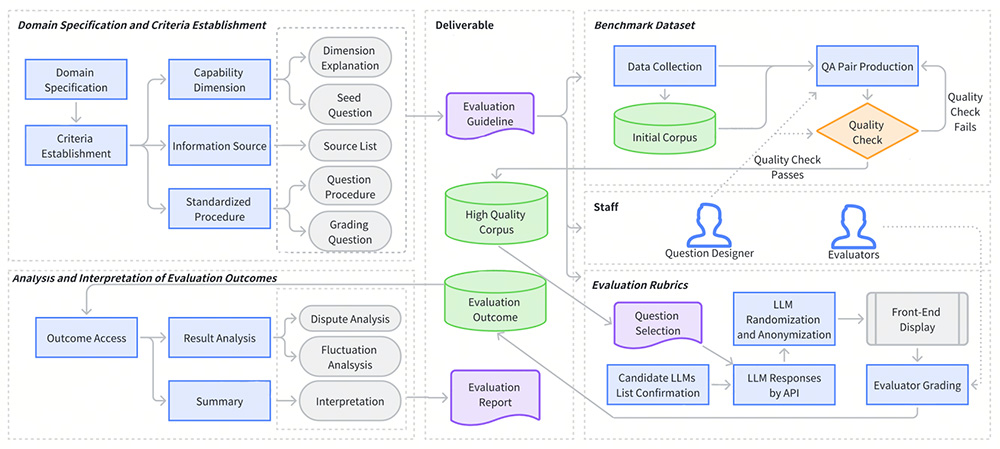
LalaEval功能特点:
1、端到端评估流程:
明确特定领域的范围和边界,与组织的目标或业务需求相关。
定义评估 LLMs 性能的能力维度,包括通用能力和领域能力。
开发标准化测试并从经过审查的信息源中收集数据。
设计详细的评分方案,为人类评估者提供结构化框架。
通过评分争议度、题目争议度、评分波动性等分析框架,自动化实现评分结果质检。
2、单盲测试原理:在评估过程中,模型的响应被匿名化并以随机顺序呈现给至少三名人类评估者,确保评分的客观性和公正性。
3、争议度和评分波动分析:自动检测和纠正人工评分中的主观性错误。
4、动态交互的部署结构:强调模块化和动态交互,能根据不同的业务场景灵活调整评估流程。
LalaEval的优点:
1、标准化评估:提供了一套标准化的评估流程,减少人工主观性。
2、高质量数据生成:能够动态生成高质量的问答对,指导领域大模型的构建和迭代优化。
3、客观公正:采用单盲测试原理,确保评分的客观性和公正性。
4、高可扩展性:设计遵循模块化和动态交互原则,能灵活扩展到其他领域。
5、自动化分析:通过争议度和评分波动分析,自动纠正人工主观错误。
LalaEval的缺点:
1、评估成本较高:人工评估过程需要投入一定的人力和时间。
2、领域依赖性:虽然具有一定的扩展性,但主要针对特定领域(如物流)设计,其他领域可能需要额外的适配。
3、数据需求:需要高质量的基准数据集来支持评估,数据收集和整理可能较为复杂。
LalaEval的项目地址:
arXiv 技术论文:https://arxiv.org/pdf/2408.13338
LalaEval应用场景:
1、物流领域大模型评估:针对同城货运等具体业务场景,评估大语言模型在物流行业的表现。
2、邀约大模型的评测:在司机邀约场景中,评估大模型在自动邀约任务中的表现。
3、企业内部大模型的定制与优化:为企业提供标准化的评估方法,根据企业自身的业务需求动态生成评测集。
4、跨领域应用的扩展性:设计遵循模块化和动态交互原则,能灵活扩展到其他领域。
 AGenUI模型 - 高德地图联合阿里千问C端开源的原生A2UI框架
AGenUI模型 - 高德地图联合阿里千问C端开源的原生A2UI框架 Mavis官网 - MiniMax Agent推出的多智能体协同工作模式
Mavis官网 - MiniMax Agent推出的多智能体协同工作模式 Xiaomi OneVL - 小米具身智能团队自研的开源自动驾驶大模型
Xiaomi OneVL - 小米具身智能团队自研的开源自动驾驶大模型 Qwen Image Edit 2511模型官网 - 阿里Qwen团队推出的开源AI图像编辑模型
Qwen Image Edit 2511模型官网 - 阿里Qwen团队推出的开源AI图像编辑模型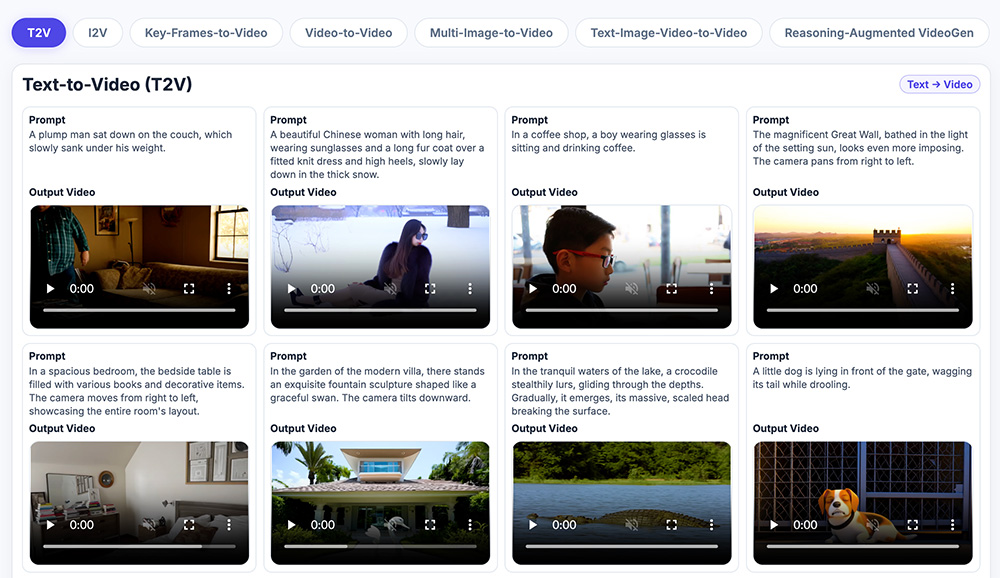 OmniWeaving视频生成框架 - 浙大 × 腾讯混元 × 南洋理工 联合发布统一视频生成框架
OmniWeaving视频生成框架 - 浙大 × 腾讯混元 × 南洋理工 联合发布统一视频生成框架 Gemini 3.1 Flash Live语音模型使用入口,Google推出的高质量实时语音交互模型
Gemini 3.1 Flash Live语音模型使用入口,Google推出的高质量实时语音交互模型 Suno v5.5 AI音乐生成模型,Voices声音定制、Custom Models自定义模型、My Taste个性化
Suno v5.5 AI音乐生成模型,Voices声音定制、Custom Models自定义模型、My Taste个性化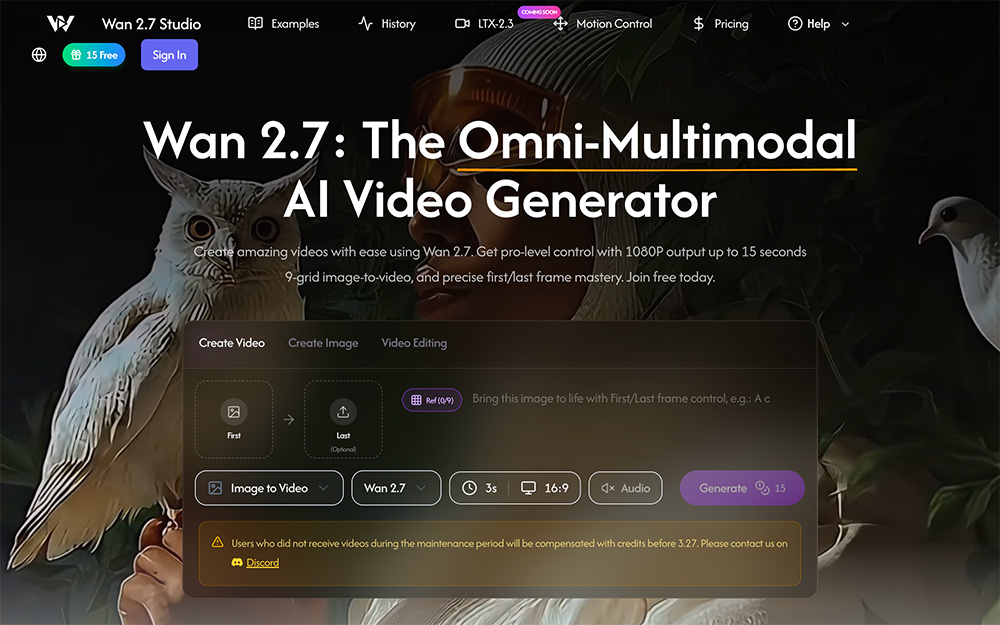 Wan 2.7 AI通用多模态AI视频生成平台,支持上传九宫格图像生成视频
Wan 2.7 AI通用多模态AI视频生成平台,支持上传九宫格图像生成视频
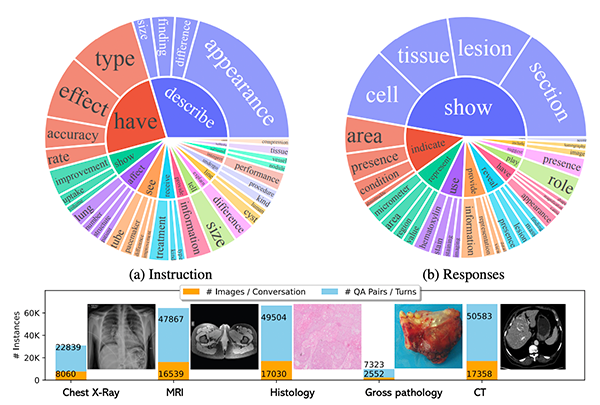 LLaVA-Rad:微软开发的新型小型多模态模型,专注于高级临床放射学报告的生成
LLaVA-Rad:微软开发的新型小型多模态模型,专注于高级临床放射学报告的生成 AIGC零基础入门到实战教程
AIGC零基础入门到实战教程 IC-Portrait:ETH和浙江大学联合推出的一种新型个性化肖像生成框架
IC-Portrait:ETH和浙江大学联合推出的一种新型个性化肖像生成框架 Seed-TTS:字节跳动开发的高质量、多功能的文本到语音(TTS)模型
Seed-TTS:字节跳动开发的高质量、多功能的文本到语音(TTS)模型 鲸喷 DeepRant:一款专为游戏玩家设计的多语言快捷翻译工具
鲸喷 DeepRant:一款专为游戏玩家设计的多语言快捷翻译工具 DiffSplat:北京大学和字节跳动的研究团队共同开发的3D生成框架
DiffSplat:北京大学和字节跳动的研究团队共同开发的3D生成框架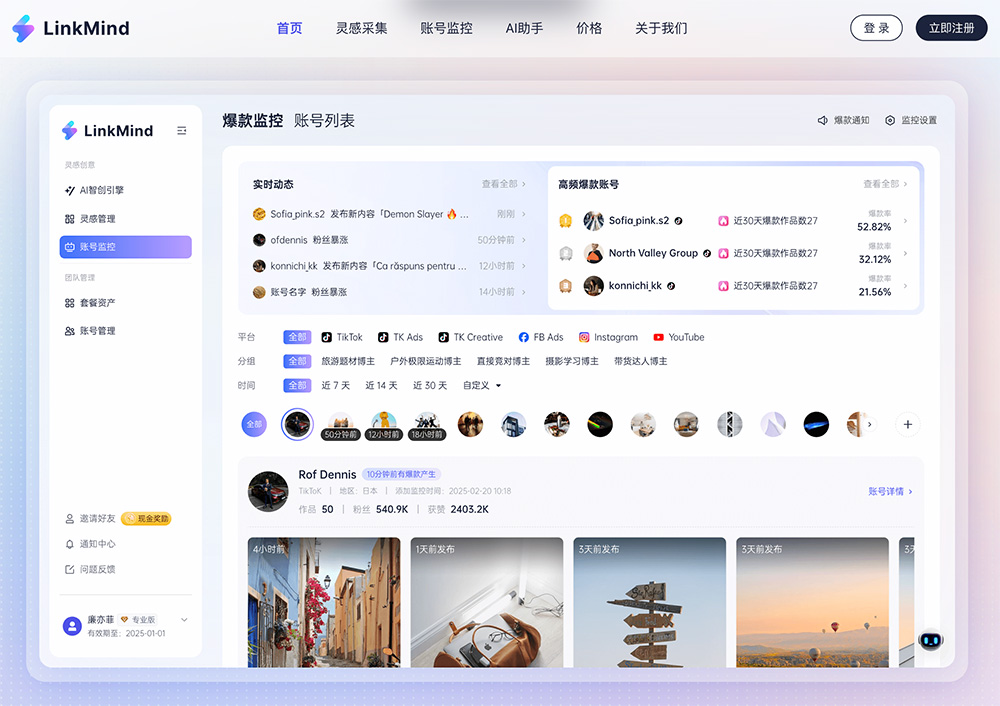 LinkMind:支持从TikTok、Instagram、YouTube等平台一键采集素材
LinkMind:支持从TikTok、Instagram、YouTube等平台一键采集素材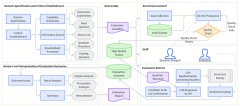 LalaEval:香港中文大学和货拉拉团队共同推出的一个LLMs的人工评估框架
LalaEval:香港中文大学和货拉拉团队共同推出的一个LLMs的人工评估框架热门工具
 google谷歌学术镜像网站
google谷歌学术镜像网站 AnyMusic AI音乐生成平台
AnyMusic AI音乐生成平台 鲜牛加速器
鲜牛加速器 Artimator.Io
Artimator.Io PrompterHub
PrompterHub最新工具
 Kane CLI
Kane CLI YeeroAI
YeeroAI Webotee
Webotee HappyHorse 1.1
HappyHorse 1.1 Boogu-Image-0.1
Boogu-Image-0.1热门标签
搜索引擎AI数字虚拟人生物医学谷歌插件素材资源效率工具生活服务思维导图在线教育平台短剧搜索教育学习AI大模型在线学习平台AI写作工具编程工具教师必备AI开发框架AI三维生成创意设计平台培训