-

- AI开发助手Unlimited-OCR模型采用3B总参MoE混合专家架构,在OmniDocBench v1.6评测集以93.92%综合分数拿下端到端SOTA最优指标,推理吞吐可达5580 TPS,全套源代码与模型权重完整开源开放。
爱站权重:


Unlimited-OCR是百度自研端到端超长文档OCR大模型,创新引入Reference Sliding Window Attention(R-SWA)机制,将解码器KV缓存由线性增长优化为常量占用,单轮推理即可一次性完成数十页文档全文转录。
一、模型核心功能:
1、超长文档一次性批量识别:
支持2页至40页以上PDF文档单轮前向推理完整转录,摒弃传统分页循环遍历逻辑,省去分页调度、分段拼接的额外开销。
2、九大版式文档全覆盖解析:
兼容PPT幻灯片、学术论文、书籍、彩色教材、试卷、期刊杂志、报纸、手写笔记、行业研究报告各类复杂排版文件。
3、全要素高精度结构化提取:
端到端同步输出纯文本、数学公式、表格内容、图文阅读顺序;公式识别CDM指标95.79%,表格还原TEDS指标93.32%。
4、双模式自适应视觉编码:
Base标准模式:固定1024×1024分辨率,适配多页长文档批量处理;
Gundam精细模式:动态自适应分辨率,针对单页文件实现超高精度细节识别。
5、常量级稳定推理延迟:
依托R-SWA缓存优化,KV缓存占用固定为m+n常量值,输出序列长度不会抬高显存占用与推理耗时,长文档运行状态平稳。
二、模型核心优势:
1、行业顶尖SOTA识别精度:
在OmniDocBench v1.5取得93.23%总分,升级v1.6后提升至93.92%,位列端到端文档识别赛道第一名。
2、显存与延迟不随页数膨胀:
KV缓存不再随文档页数线性上涨,处理20页、40页以上长文档时,显存占用、推理耗时基本持平,大幅降低超长文档处理硬件门槛。
3、长文本场景吞吐优势显著:
文档输出token越长,速度优势越突出;6144 token长序列下,理论TPS上限相比DeepSeek-OCR高出约35%。
4、通用可迁移解码架构:
R-SWA滑动窗口缓存机制并非OCR专用优化方案,可无缝迁移至语音识别ASR、机器翻译、长字幕生成等所有「参考素材+超长文本输出」生成类任务。
5、轻量化开源易部署:
整体参数量3B,激活参数量仅500M,硬件部署门槛低;模型权重、完整训练推理代码全部开源,支持企业二次开发与定制微调。
三、完整使用流程:
1、获取代码与权重:
可前往Hugging Face仓库 baidu/Unlimited-OCR 或GitHub官方仓库 baidu/Unlimited-OCR 下载完整项目与预训练权重。
2、部署运行环境:
兼容Transformers标准库与SGLang高性能推理引擎,按需配置对应GPU运行环境。
3、选择对应输入模式:
输入支持PDF转图像格式;多页长文档选用Base模式,单页精细识别切换Gundam动态分辨率模式。
4、一键执行整档推理:
单次推理请求即可完成整本文档全部页面OCR结构化转录,无需额外开发分页调度逻辑。
5、跨场景机制迁移复用:
项目内置的R-SWA核心优化模块可剥离复用,适配语音识别、长文本翻译、视频字幕生成等各类超长序列生成业务。
数据统计
特别声明&浏览提醒
本站AI工具导航站提供的「Unlimited-OCR」的相关内容都来源于网络,不保证外部链接的准确性和完整性。在2026年06月24日 07时11分27秒收录时,该网站上的内容都属于合规合法,后期网站的内容如出现违规,可以直接联系网站管理员(ai@ipkd.cn)进行删除,AI工具导航站不承担任何责任。在浏览网页时,请注意您的账号和财产安全,切勿轻信网上广告!
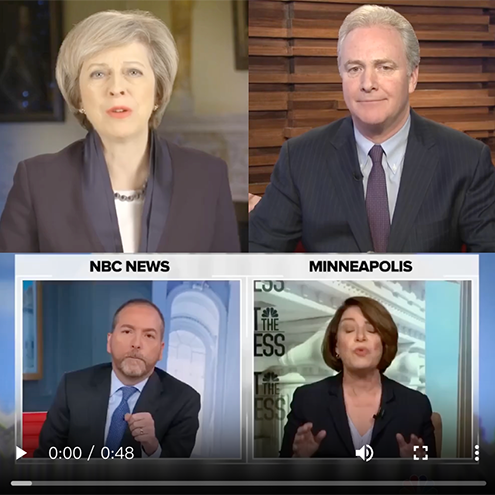 SyncAnimation:南方科技大学等机构推出的端到端音频驱动框架
SyncAnimation:南方科技大学等机构推出的端到端音频驱动框架 IC-Portrait:ETH和浙江大学联合推出的一种新型个性化肖像生成框架
IC-Portrait:ETH和浙江大学联合推出的一种新型个性化肖像生成框架 Hunyuan3D 2.0:腾讯推出的一种先进大规模 3D 合成系统
Hunyuan3D 2.0:腾讯推出的一种先进大规模 3D 合成系统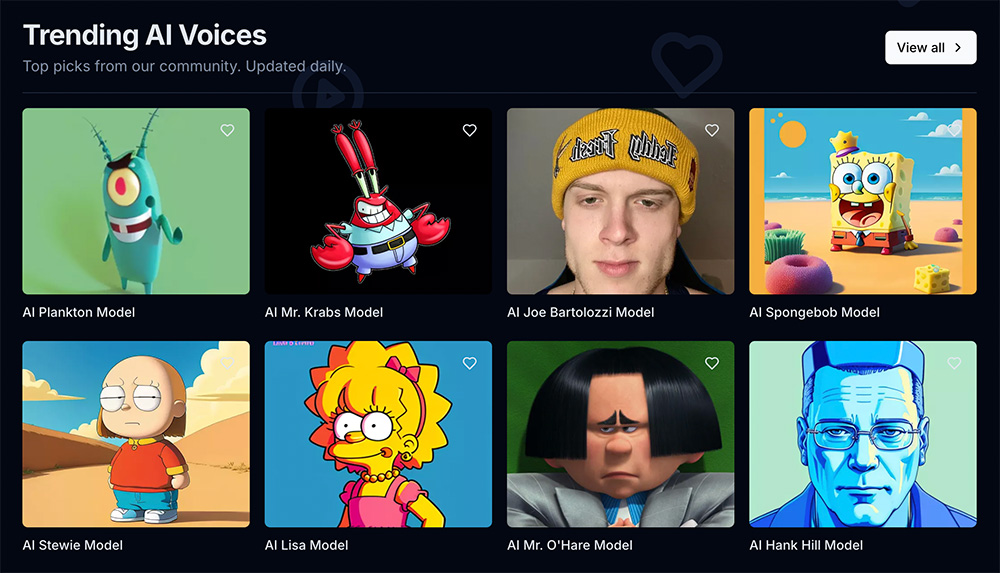 2025年ai声音克隆哪个最好 盘点值得推荐的AI声音克隆工具2025
2025年ai声音克隆哪个最好 盘点值得推荐的AI声音克隆工具2025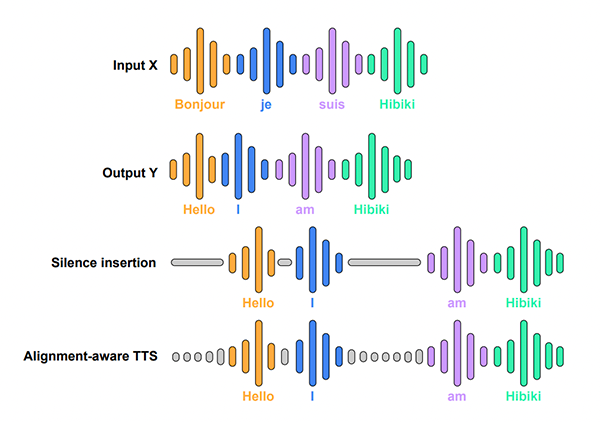 Hibiki:一款由Kyutai开发的实时同声传译语音模型
Hibiki:一款由Kyutai开发的实时同声传译语音模型 Infinity:一款由字节跳动推出的高分辨率图像生成模型
Infinity:一款由字节跳动推出的高分辨率图像生成模型
 即梦AI绘画网页版
即梦AI绘画网页版 阿里·通义千问网页版
阿里·通义千问网页版 藏族日历小程序
藏族日历小程序
 Akkio
Akkio 亚马逊云AWS
亚马逊云AWS ST-Raptor
ST-Raptor 旷视AI平台
旷视AI平台 JuheNext
JuheNext
 彝族日历小程序
彝族日历小程序
 和鲸AI平台
和鲸AI平台 麦芽AI
麦芽AI VDraw
VDraw DMXAPI
DMXAPI Lobe
Lobe