OmniWeaving视频生成框架 - 浙大 × 腾讯混元 × 南洋理工 联合发布统一视频生成框架
OmniWeaving是由浙江大学、腾讯混元、南洋理工大学联合推出的统一视频生成框架,突破传统开源模型单一任务局限,实现多模态自由组合与推理增强生成,可对交错图文视频进行时序绑定,输出连贯内容,更以“智能导演”模式主动理解复杂创作意图。
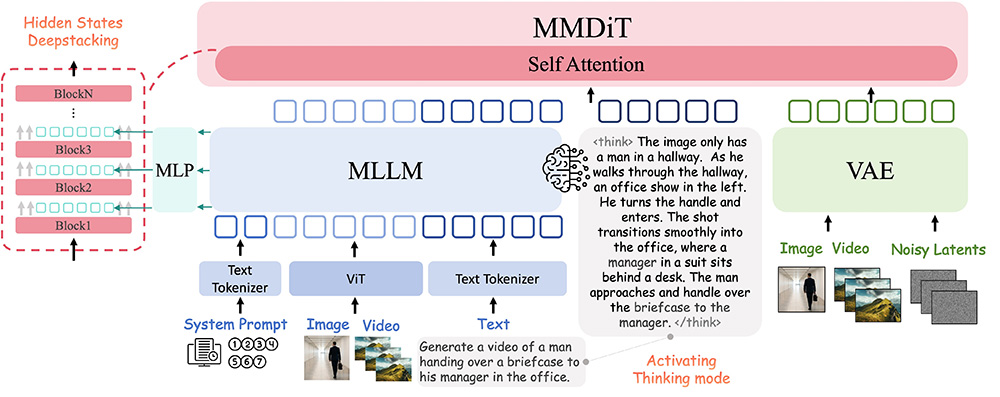
框架采用MLLM语义理解、MMDiT生成、VAE编码三大核心组件架构,同步推出IntelligentVBench评估基准,在开源统一视频模型中实现SoTA性能,为缩小开源与商业视频生成技术差距提供重要开源方案。
OmniWeaving核心功能:
1、统一多模态生成:
单框架无缝融合文本、多图、视频输入,支持交错式自由组合,覆盖多样化视频生成任务,摆脱传统单一任务模型的碎片化问题。
2、时序绑定生成:
对跨模态内容进行时序对齐与绑定,生成逻辑连贯、过渡自然的动态视频。
3、推理增强创作:
依托MLLM“思考模式”主动推断模糊与复杂意图,像专业导演自主规划镜头与叙事,从被动渲染升级为主动创作。
4、高级语义理解:
通过多模态大模型将自由输入映射至高级语义空间,结合扩散Transformer生成精细可控的视频内容。
5、端到端视频生成:
实现从语义理解到视频输出一体化流程,支持角色一致性、风格迁移等复杂需求,在IntelligentVBench上达到开源模型顶尖水平。
OmniWeaving核心优势:
1、统一全能:
单框架支持文生视频、图生视频、多图组合、视频编辑等六大类任务,替代多专用模型组合,实现全流程统一生成。
2、自由组合:
突破固定输入格式限制,支持1–4张图像、视频片段与文本交错输入,通过时序绑定理解时空关系,实现深度融合而非简单拼接。
3、推理增强:
开启MLLM思考模式后,模型从指令执行器升级为“智能导演”,自动补全镜头与叙事,大幅降低提示词工程难度。
4、深度语义注入:
采用DeepStacking机制提取MLLM多粒度语义特征并注入生成网络,兼顾像素级细节与高层语义对齐,缓解多主体生成细节丢失问题。
OmniWeaving使用方式:
1、环境准备:
从GitHub克隆仓库,安装`requirements.txt`依赖,可选安装Flash Attention / SageAttention加速推理。
2、模型下载:
在HuggingFace下载腾讯混元HY-OmniWeaving模型权重至本地指定目录。
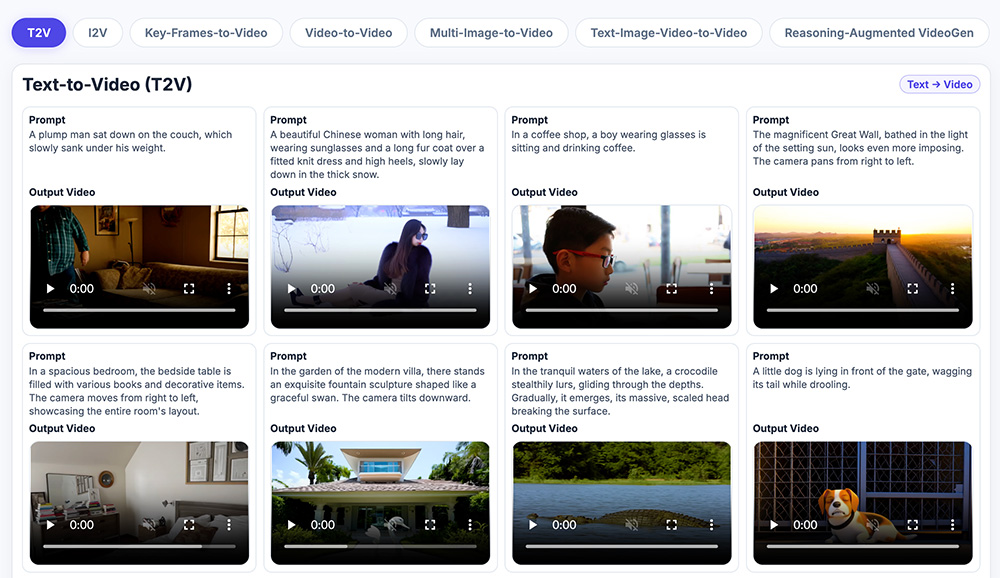
3、文生视频(t2v):
输入文本描述、设置画幅与输出路径,可开启思考模式,让模型先推理意图再生成。
4、图生视频(i2v):
传入首帧图片与动作描述,由静态图像生成动态视频。
5、首尾帧插值(interpolation):
输入起止帧与过渡文本,自动补全中间画面,生成流畅过渡视频。
6、多图组合生成(reference2v):
上传1–4张参考图(人物、场景、道具等),配合文本实现多元素融合视频创作。
7、视频编辑(editing):
上传原视频并输入编辑指令(风格转换、物体替换等),完成智能修改。
8、图文视频联合编辑(tiv2v):
同时输入视频与参考图,将参考视觉元素融合进动态场景。
OmniWeaving项目网址:
1、项目官网:https://omniweaving.github.io/
2、GitHub仓库:https://github.com/Tencent-Hunyuan/OmniWeaving
3、HuggingFace模型库:https://huggingface.co/tencent/HY-OmniWeaving
4、arXiv技术论文:https://arxiv.org/pdf/2603.24458
OmniWeaving应用场景:
1、影视广告创意:
文本快速生成分镜预演视频,自由组合角色、场景、道具参考图生成完整广告片。
2、电商动态展示:
产品白底图+场景图自动生成使用场景视频,结合用户照片实现虚拟试穿等个性化效果。
3、社媒内容创作:
静态照片转为动态视频,让老照片“动起来”;基于首尾帧插值快速制作循环动画与表情包。
4、游戏动画资产:
角色设计图+动作描述直接生成动画片段,关键帧自动补全中间画,加速过场与场景切换制作。
标签:

基金从业资格考试题库
一站式备考基金从业资格考试,收录2021-2025年模拟题库!
 Qwen Image Edit 2511模型官网 - 阿里Qwen团队推出的开源AI图像编辑模型
Qwen Image Edit 2511模型官网 - 阿里Qwen团队推出的开源AI图像编辑模型 OmniWeaving视频生成框架 - 浙大 × 腾讯混元 × 南洋理工 联合发布统一视频生成框架
OmniWeaving视频生成框架 - 浙大 × 腾讯混元 × 南洋理工 联合发布统一视频生成框架 Gemini 3.1 Flash Live语音模型使用入口,Google推出的高质量实时语音交互模型
Gemini 3.1 Flash Live语音模型使用入口,Google推出的高质量实时语音交互模型 Wan2.7-Video视频创作模型官网 - 阿里通义AI视频大模型,像修图一样精准创作专业视频
Wan2.7-Video视频创作模型官网 - 阿里通义AI视频大模型,像修图一样精准创作专业视频 GLM-5V-Turbo基座模型官网 - 智谱AI推出的原生多模态Coding基座模型
GLM-5V-Turbo基座模型官网 - 智谱AI推出的原生多模态Coding基座模型 ClawHub镜像站官网:OpenClaw官方推出的中国区专属镜像站点
ClawHub镜像站官网:OpenClaw官方推出的中国区专属镜像站点 Wan 2.7 AI通用多模态AI视频生成平台,支持上传九宫格图像生成视频
Wan 2.7 AI通用多模态AI视频生成平台,支持上传九宫格图像生成视频 AIGC零基础入门到实战教程
AIGC零基础入门到实战教程 ResumeYay:免费的在线AI简历生成器,无需注册或登录即可使用
ResumeYay:免费的在线AI简历生成器,无需注册或登录即可使用 2025年ai声音克隆哪个最好 盘点值得推荐的AI声音克隆工具2025
2025年ai声音克隆哪个最好 盘点值得推荐的AI声音克隆工具2025 eMAG全球3大国际站大盘点
eMAG全球3大国际站大盘点 8款热门AI绘画工具,国内外免费资源,轻松创作艺术佳作!
8款热门AI绘画工具,国内外免费资源,轻松创作艺术佳作!热门工具
 NocoBase
NocoBase 免费录屏软件
免费录屏软件 可灵(KLING)
可灵(KLING) Wzrd.Ai
Wzrd.Ai MindShow
MindShow热门标签
学习资源AI学习框架媒体运营AI辅助工具AI法律服务AI写作工具AI三维生成浏览器插件AI大模型办公生活二次元漫画在线短剧知识百科pdf转换AI开放平台