-
 Loopy
Loopy
- AI视频创作Loopy通过音频输入生成虚拟人物的多种动作,包括头部、眼睛、眉毛等部位的微表情。
爱站权重:


Loopy是由字节跳动和浙江大学的研究团队共同开发的端到端音频驱动的肖像视频生成模型。它通过音频信号生成动态的肖像视频,能够实现音频与视觉内容的同步。
![]()
Loopy功能特点包括:
1、音频驱动的动态生成:
通过音频输入生成虚拟人物的多种动作,包括头部、眼睛、眉毛等部位的微表情。能够完美适应不同的音频风格,如欢快音乐下人物的活跃动作或舒缓音频中的柔和动作。
2、多样化动作效果:
针对同一参考图像,根据不同的音频输入生成多样化的动作效果,从快速动态到柔和表现不一而足。
3、面部情感同步:
不仅能处理语言表达的情感,还能生成包括叹息等非语言的情感动作。
4、适应各种视觉风格:
可以处理不同角度的图像,即使是侧面图像也能很好地进行处理。
5、无需额外条件:
不需要使用额外的空间信号或其他辅助信息,仅依靠音频输入即可生成高质量的视频。
6、长期运动信息捕捉:
具备处理长期运动信息的能力,生成更加自然和流畅的动作。
7、高自然度和高质量:
生成的视频动作自然,与音频同步性好,看起来就像真人在说话。
Loopy的技术原理:
1、音频驱动模型:
Loopy的核心是音频驱动的视频生成模型,根据输入的音频信号生成与音频同步的动态视频。
2、扩散模型:
Loopy使用扩散模型技术,通过逐步引入噪声并学习逆向过程来生成数据。
3、时间模块:
Loopy设计了跨片段和片段内部的时间模块,模型能理解和利用长期运动信息,生成更加自然和连贯的动作。
4、音频到潜空间的转换:
Loopy通过音频到潜空间的模块将音频信号转换成能够驱动面部动作的潜在表示。
5、运动生成:
从音频中提取的特征和长期运动信息,Loopy生成相应的面部动作,如嘴型、眉毛、眼睛等部位的动态变化。
Loopy应用场景:
1、虚拟主播和虚拟偶像:
根据主播的声音生成与其匹配的动画,使虚拟角色更加生动逼真。
2、电影和动画制作:
减少手动动画制作的工作量,通过音频输入生成自然的面部表情和动作
3、内容创作与短视频制作:
创作者可以利用 Loopy 为短视频或其他内容生成个性化的虚拟人物动画
4、游戏角色动画:
提升角色互动的自然感和玩家的沉浸感
5、虚拟会议和社交场景:
为用户提供真实感更强的虚拟形象,自动根据音频生成动作
6、教育和在线培训:
为在线教育平台提供虚拟教师形象,使教师的音频讲解与虚拟形象的动作自然同步

数据统计
特别声明&浏览提醒
本站AI工具导航站提供的「Loopy」的相关内容都来源于网络,不保证外部链接的准确性和完整性。在2025年02月01日 19时46分20秒收录时,该网站上的内容都属于合规合法,后期网站的内容如出现违规,可以直接联系网站管理员(ai@ipkd.cn)进行删除,AI工具导航站不承担任何责任。在浏览网页时,请注意您的账号和财产安全,切勿轻信网上广告!
 9款免费AI模特生成工具:个性化定制专属模特
9款免费AI模特生成工具:个性化定制专属模特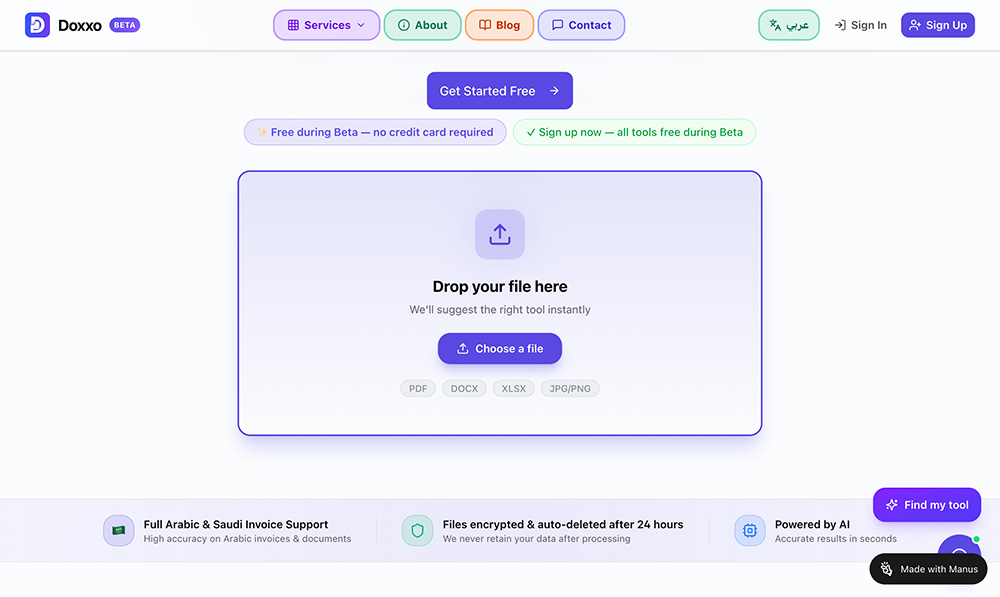 Doxxo — 云端智能专业文档处理平台,内置32款专业办公AI工具
Doxxo — 云端智能专业文档处理平台,内置32款专业办公AI工具 几款免费AI图片放大工具,高清无损放大图像
几款免费AI图片放大工具,高清无损放大图像 7款免费AI英语口语软件,一对一模拟对话,轻松开口说英语!
7款免费AI英语口语软件,一对一模拟对话,轻松开口说英语! 10款免费AI数据分析神器,一键生成,轻松搞定数据难题!
10款免费AI数据分析神器,一键生成,轻松搞定数据难题!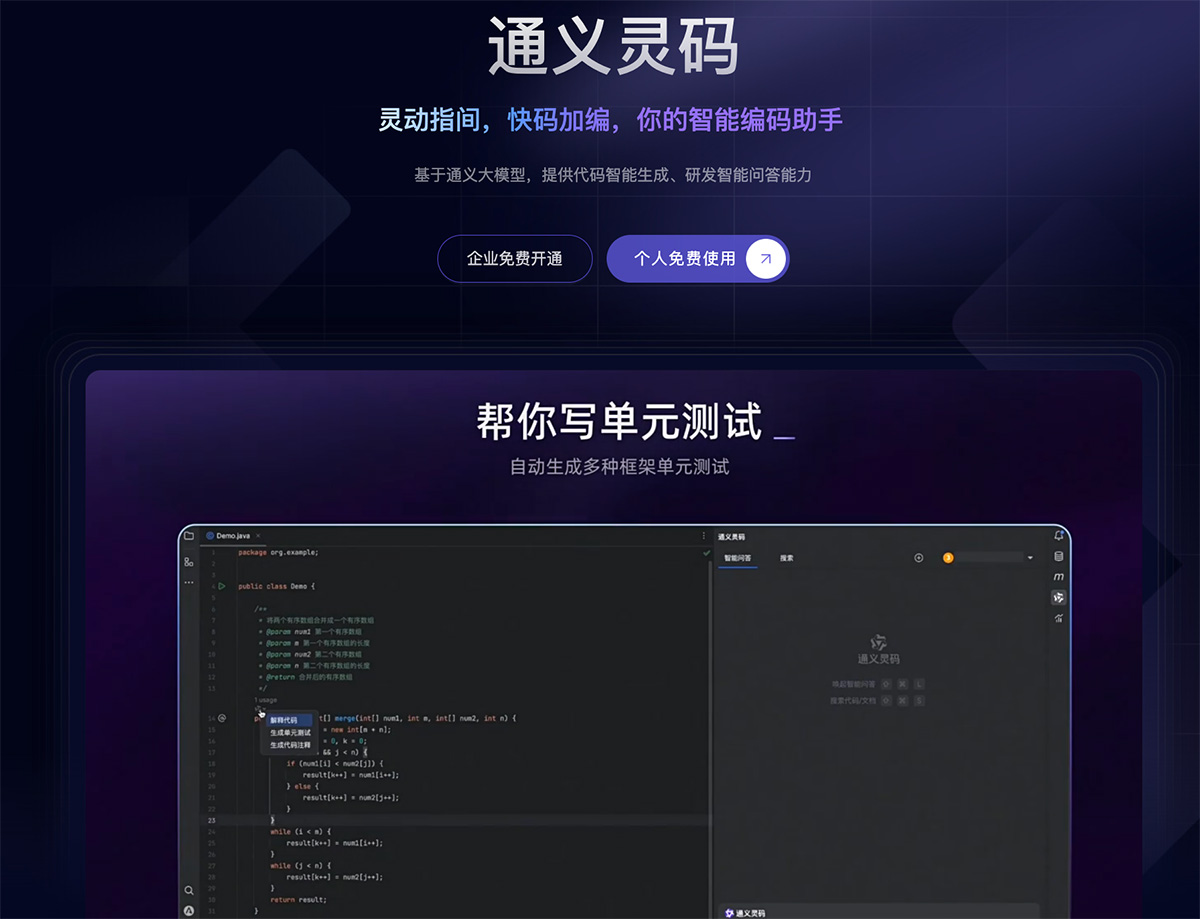 12款免费AI编程工具,智能生成代码,提升开发效率
12款免费AI编程工具,智能生成代码,提升开发效率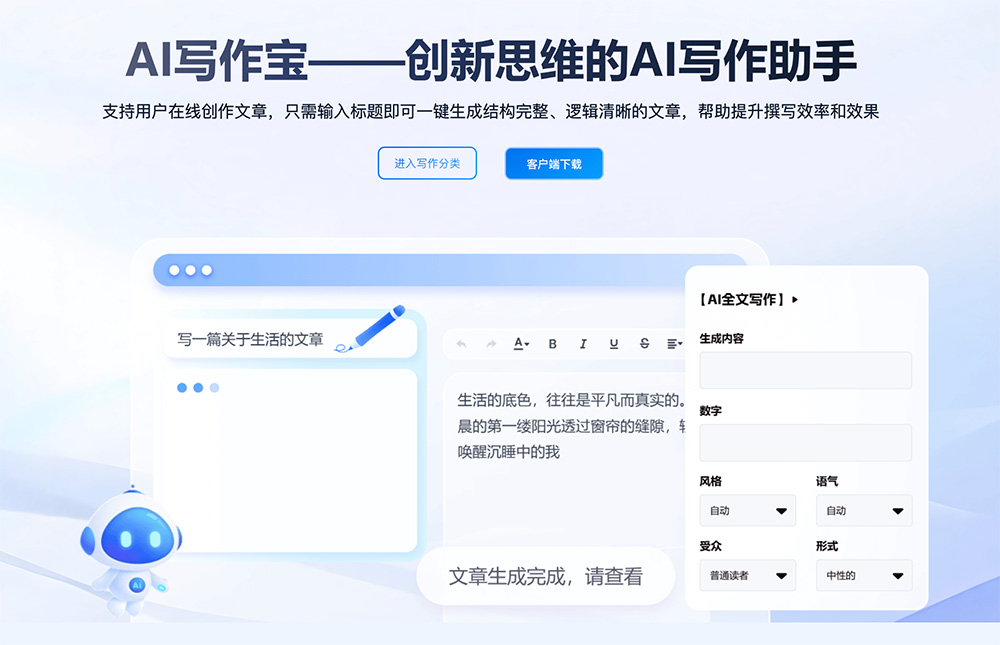 6款免费AI写作神器,一键生成文章、报告、公文、论文,高效又省心!
6款免费AI写作神器,一键生成文章、报告、公文、论文,高效又省心!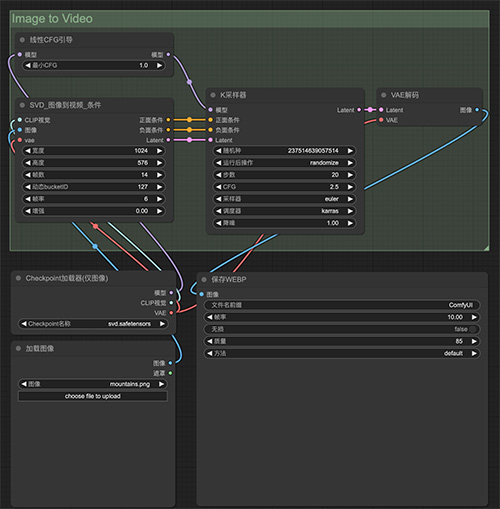 图片转视频ComfyUI工作流
图片转视频ComfyUI工作流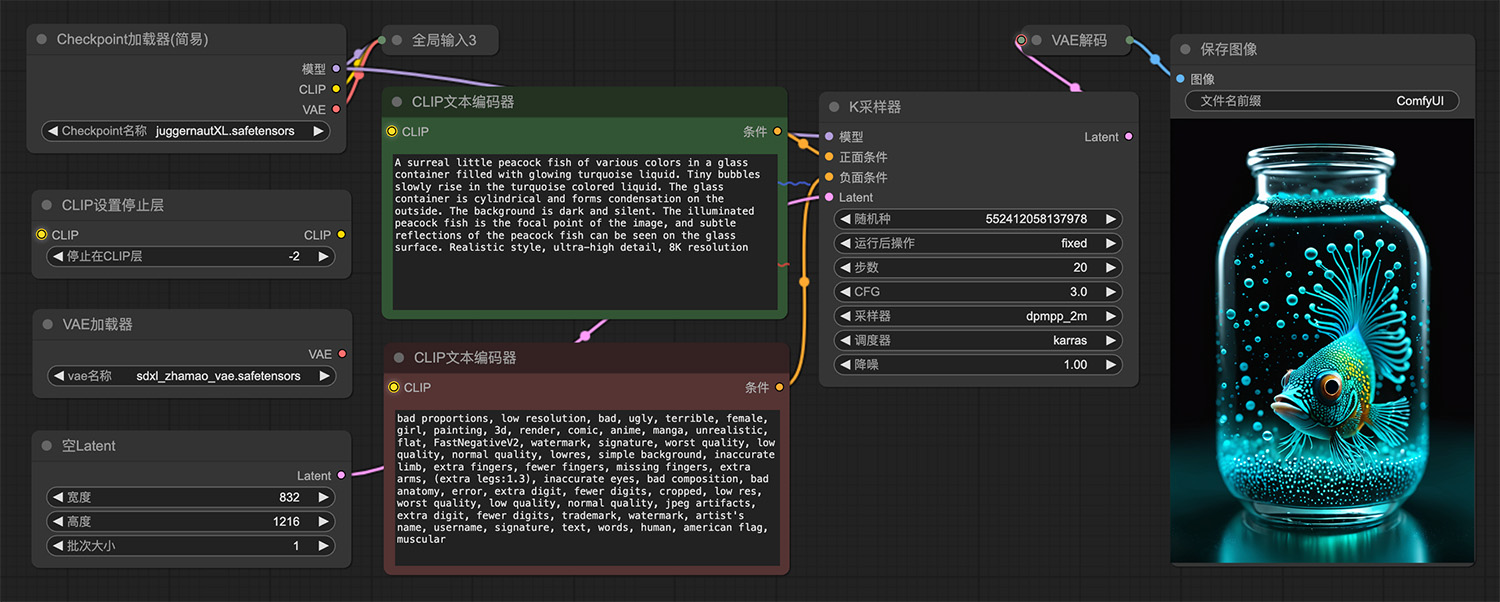 一条色彩斑斓的超现实小孔雀鱼ComfyUI工作流
一条色彩斑斓的超现实小孔雀鱼ComfyUI工作流 基础扩图comfyui工作流
基础扩图comfyui工作流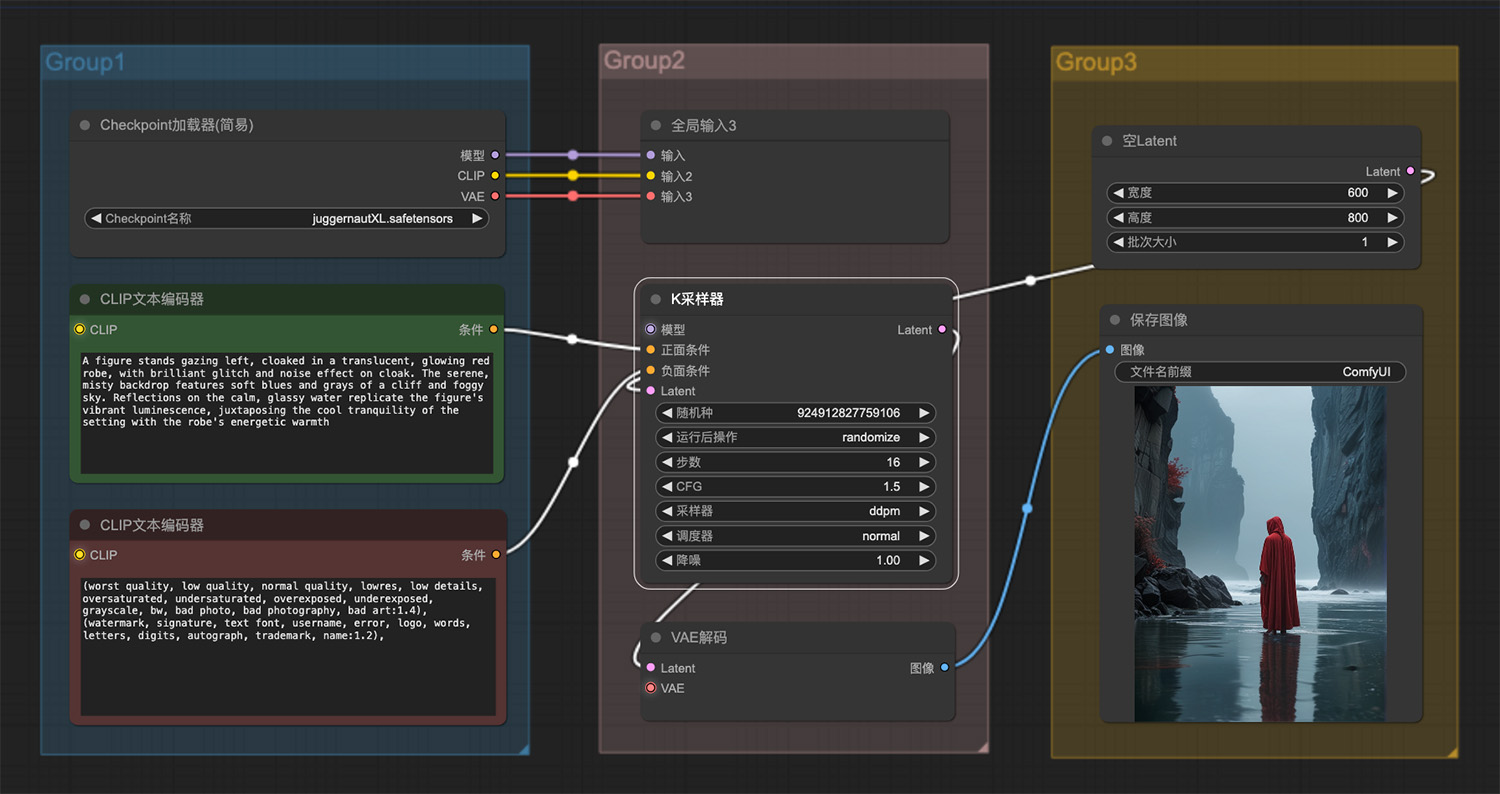 一个穿着发光红色长袍的人
一个穿着发光红色长袍的人 庭院,彩色玫瑰,云雾笼罩comfyui工作流
庭院,彩色玫瑰,云雾笼罩comfyui工作流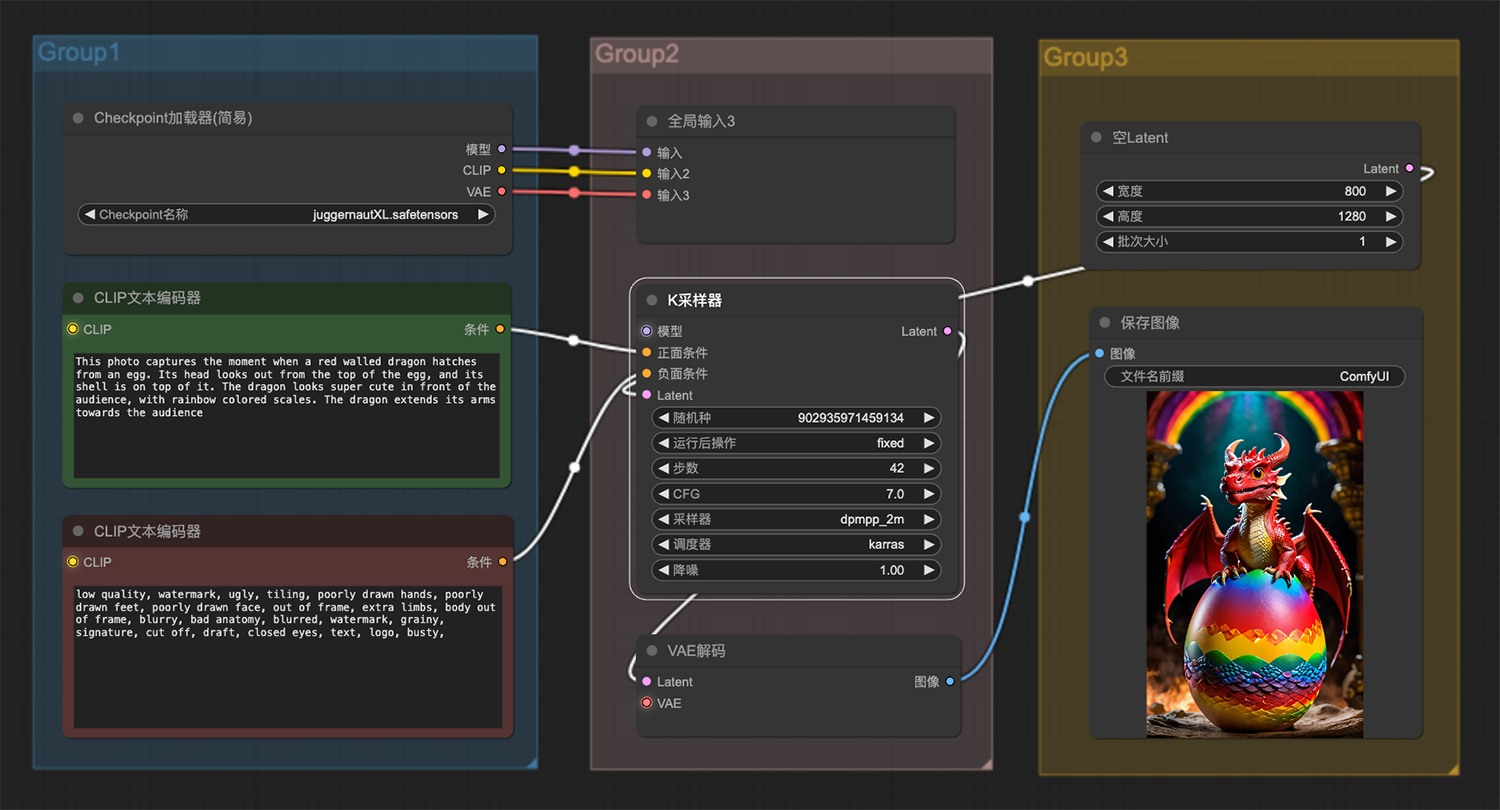 一条赤壁龙从蛋中孵化出来ComfyUI工作流
一条赤壁龙从蛋中孵化出来ComfyUI工作流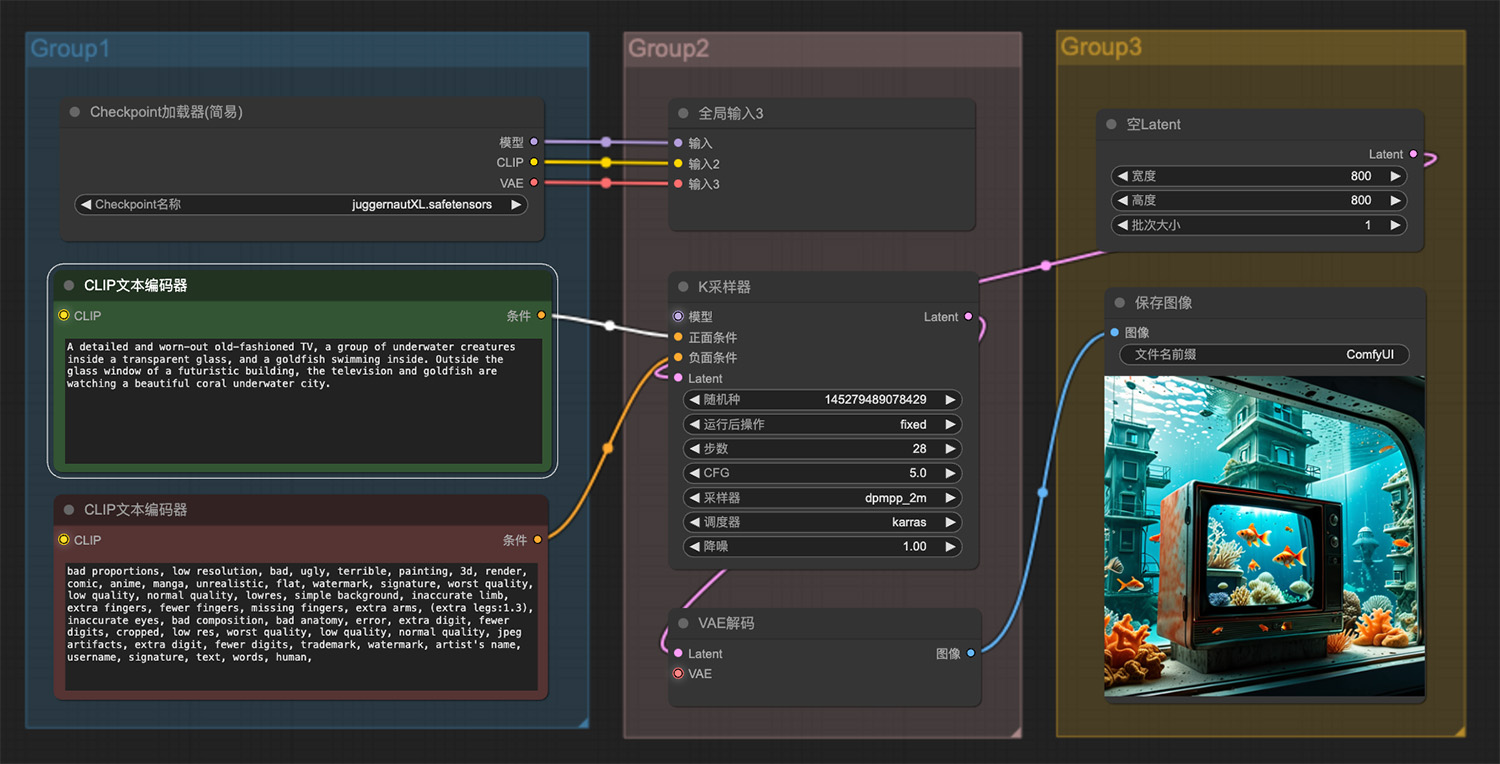 水中一台精致而破旧的老式电视鱼缸ComfyUI工作流
水中一台精致而破旧的老式电视鱼缸ComfyUI工作流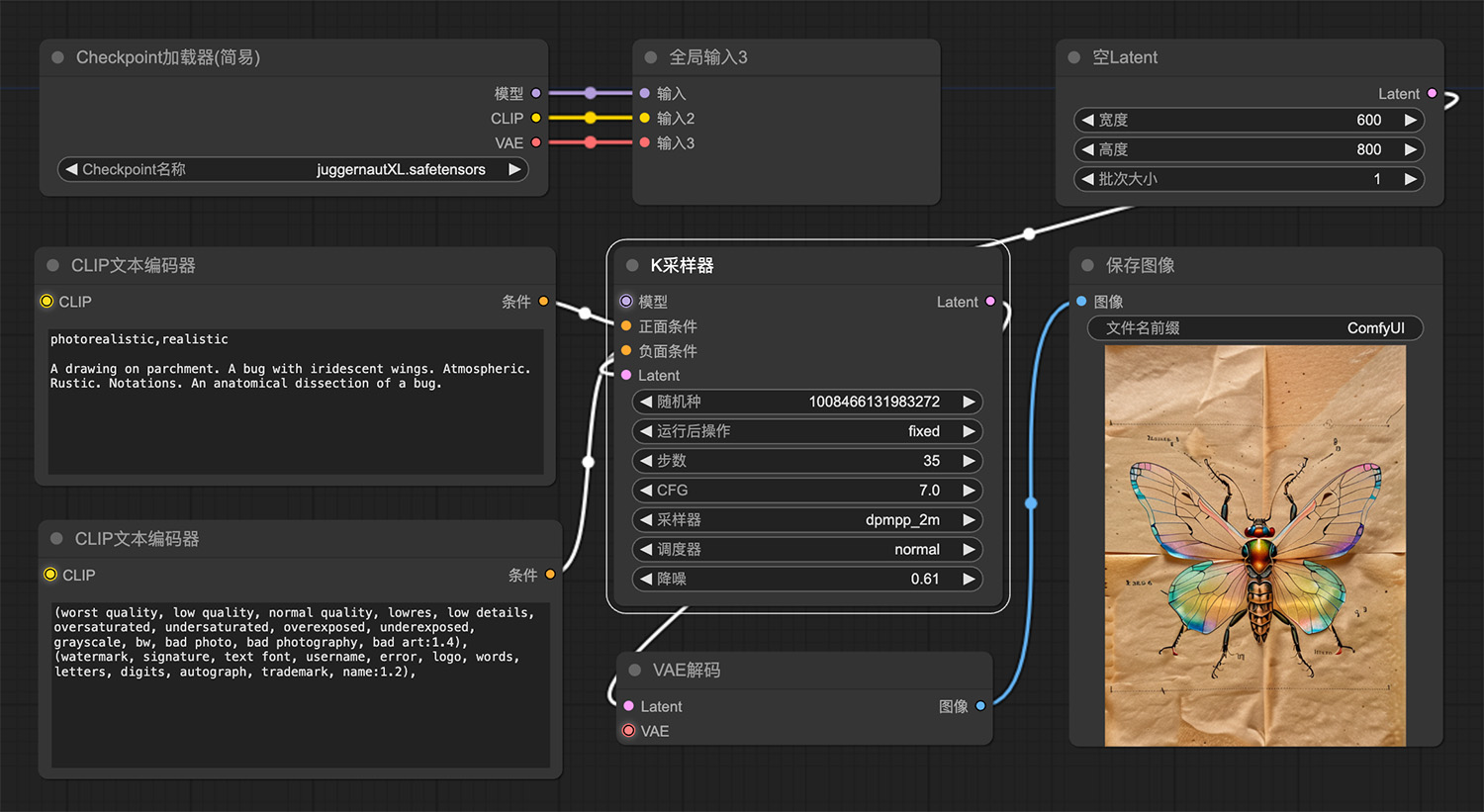 一种长着彩虹翅膀的虫子comfyui工作流
一种长着彩虹翅膀的虫子comfyui工作流 即梦AI绘画网页版
即梦AI绘画网页版 阿里·通义千问网页版
阿里·通义千问网页版 藏族日历小程序
藏族日历小程序
 UGCfy AI
UGCfy AI Assistive Video
Assistive Video 剧火AI
剧火AI Noodle Tomato
Noodle Tomato RHTV
RHTV
 彝族日历小程序
彝族日历小程序
 绘影字幕
绘影字幕 WOXO
WOXO ProdShort
ProdShort ArtarchStudio
ArtarchStudio 融光
融光