Mega-ASR – 面向全场景的高鲁棒语音识别基座模型
Mega-ASR由南洋理工大学、新加坡国立大学联合上海人工智能实验室共同开源,是面向全场景的高鲁棒语音识别基座模型。模型基于Qwen3-ASR 1.7B架构研发,针对噪声干扰、远场收音、回声遮挡、传输丢包等复杂真实声学场景,搭建可扩展复合数据体系与声学到语义渐进优化框架,有效攻克恶劣环境下的语音识别难题。

Mega-ASR项目地址:
1、项目主页入口:https://xzf-thu.github.io/Mega-ASR/
2、GitHub仓库:https://github.com/xzf-thu/Mega-ASR
3、模型库入口:https://huggingface.co/zhifeixie/Mega-ASR
4、技术论文:https://arxiv.org/pdf/2605.19833
Mega-ASR核心功能:
1、全场景鲁棒识别:
覆盖7类基础声学干扰效应,适配54种复合型实际收音场景,单模型即可适配各类复杂环境识别需求。
2、声语义渐进优化A2S-SFT:
分三阶段迭代训练,逐级适配不同语音退化程度,兼顾声学特征感知与文本语义还原,破解双重技术瓶颈。
3、双粒度动态奖励DG-WGPO:
依据词级、句级双层奖励机制,结合错误率阈值动态调控优化方向,大幅降低极端场景语句丢失、语义幻觉问题。
4、环境感知智能路由:
搭载轻量化音频分类模块,精准判别语音质量,干净音频沿用原生模型推理,受损语音启用鲁棒分支增强识别,无侵入提升效果。
5、大规模开源数据集:
推出240万条合成音频搭配5000条实测音频的开源数据集,囊括多难度梯度场景,数据样本经过严谨校准筛选。
Mega-ASR技术原理:
1、场景化数据构建:
频谱仿真模拟基础声学干扰,遵循物理逻辑组合生成复合场景,统一参数调控难度,剔除无效异常样本。
2、三段式课程训练:
循序渐进适配语音退化场景,分步打磨声学编码、语义理解能力,最终全局联动微调,对齐声学特征与语义逻辑。
3、动态奖惩优化机制:
区分字词细节错误与整句语义偏差,依据识别错误程度自适应调整优化权重,兼顾精准度与完整性。
4、轻量化音频分类:
精简网络结构实现语音品质高速判定,分类准确率超99.5%,推理资源损耗极低。
Mega-ASR使用流程:
1、部署运行环境:
依托Qwen3-ASR生态搭建环境,安装音频处理、模型推理相关依赖库,满足特征提取与权重加载运行条件。
2、载入模型组件:
分别加载基础模型、鲁棒LoRA权重以及环境路由判定模型,配齐全套推理组件。
3、音频预处理分流:
提取语音特征后送入分类模块,自动区分纯净语音与受损语音。
4、分支自适应推理:
纯净语音采用原生模型保障基础精度,受损语音切换增强分支,抵御各类声学干扰。
5、输出识别结果:
恶劣收音条件下依旧规避空白识别、语义错乱问题,输出完整精准的文本转写内容。
Mega-ASR核心优势:
1、场景性能拔尖:
混合退化场景识别错误率大幅优于Whisper、Gemini主流模型,极端低信噪比环境识别能力显著提升。
2、语义还原能力强劲:
面对极限收音损耗场景,可精准复原完整语句,规避空白输出与虚假文本生成问题。
3、基础性能无损:
智能分流架构保障标准场景识别精度,原有各类实用功能均可正常使用。
4、训练运行稳定:
筛选劣质样本搭配梯度式训练策略,杜绝模型训练失效崩溃。
5、开源易用性高:
全套代码、权重、数据集与评测标准公开,依托成熟生态,快速落地部署。
Mega-ASR应用场景:
车载语音指令识别、远程会议课堂实时转写、户外采访直播字幕生成、智能家居语音操控、网络通话与客服语音内容解析,适配各类存在声学干扰的语音识别场景。
标签:


 AGenUI模型 - 高德地图联合阿里千问C端开源的原生A2UI框架
AGenUI模型 - 高德地图联合阿里千问C端开源的原生A2UI框架 Mavis官网 - MiniMax Agent推出的多智能体协同工作模式
Mavis官网 - MiniMax Agent推出的多智能体协同工作模式 Xiaomi OneVL - 小米具身智能团队自研的开源自动驾驶大模型
Xiaomi OneVL - 小米具身智能团队自研的开源自动驾驶大模型 SenseNova-Skills – 商汤OpenSenseNova团队开源模块化AI办公技能库
SenseNova-Skills – 商汤OpenSenseNova团队开源模块化AI办公技能库 Mega-ASR – 面向全场景的高鲁棒语音识别基座模型
Mega-ASR – 面向全场景的高鲁棒语音识别基座模型 CodeGraph – 面向AI编码代理的预索引代码知识图谱工具
CodeGraph – 面向AI编码代理的预索引代码知识图谱工具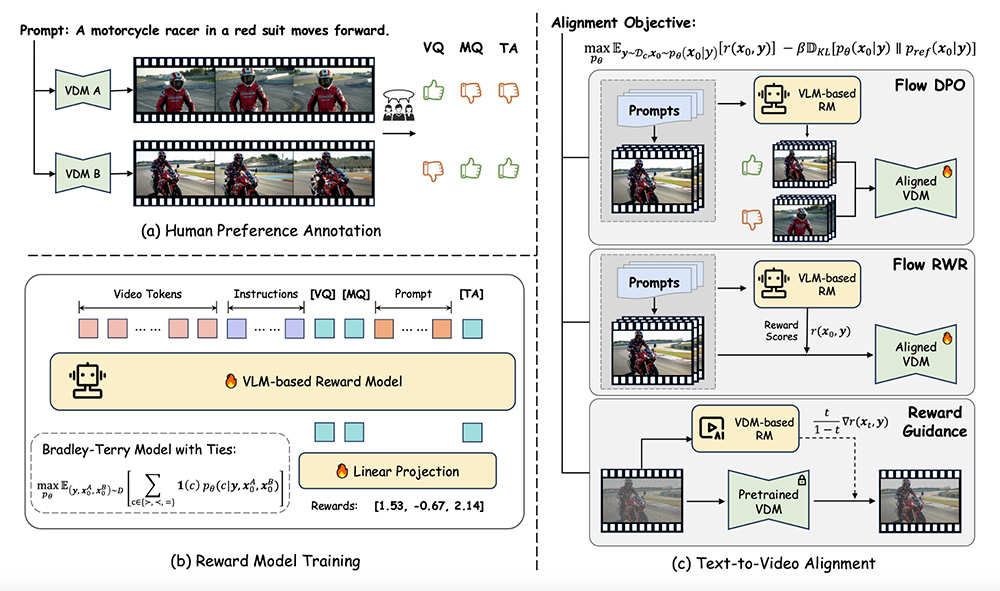 VideoReward:一种基于人类偏好数据的多维度视频奖励模型
VideoReward:一种基于人类偏好数据的多维度视频奖励模型 Goku:香港大学与字节跳动合作推出的一款AI视频生成模型
Goku:香港大学与字节跳动合作推出的一款AI视频生成模型 FastbuildAI:没有编程基础的用户也能零代码搭建原生AI应用
FastbuildAI:没有编程基础的用户也能零代码搭建原生AI应用 12款网盘工具,谁才是你的存储神器?
12款网盘工具,谁才是你的存储神器? 9款免费AI模特生成工具:个性化定制专属模特
9款免费AI模特生成工具:个性化定制专属模特 7款免费AI英语口语软件,一对一模拟对话,轻松开口说英语!
7款免费AI英语口语软件,一对一模拟对话,轻松开口说英语!热门工具
 Viable
Viable 讯飞虚拟人
讯飞虚拟人 腾讯应用宝
腾讯应用宝 象寄AI
象寄AI热门标签
AI写真知识百科mac软件下载AI企业服务二手交易批量处理谷歌插件前端UI组件库AI金融事务AI大模型ppt模板PDF分析AI抠图效率工具AI营销工具