VideoReward:一种基于人类偏好数据的多维度视频奖励模型
VideoReward是一个多维度的视频奖励模型,旨在通过人类反馈来改进视频生成的质量和一致性。它由香港中文大学、清华大学、快手科技等机构联合创建。该模型通过构建大规模的人类偏好数据集,结合成对标注和多维度分析,优化视频生成模型,解决视频生成中常见的问题,如运动不流畅和视频与提示之间的错位。
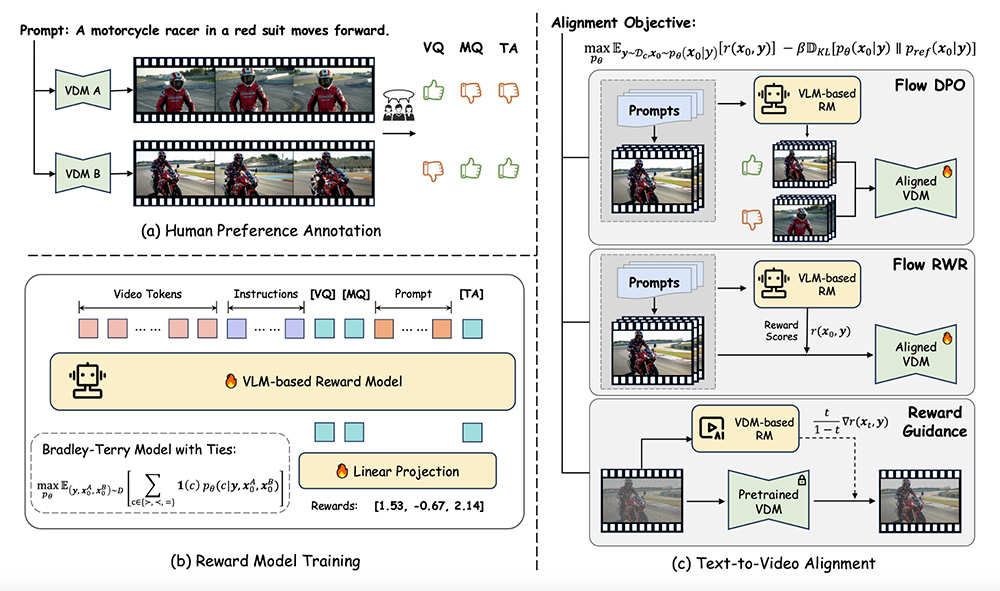
VideoReward功能特点:
1、多维度奖励模型:VideoReward通过多个维度(如视觉质量、运动质量和文本对齐)来评估视频生成的质量,确保生成的视频在多个方面都能满足用户需求。
2、训练策略:
- 流的直接偏好优化(Flow-DPO):通过直接优化流数据的偏好来提升视频质量。
- 奖励加权回归(Flow-WRR):将奖励直接应用于噪声视频,从而改善生成效果。
- 推理阶段技术(Flow-NRG):允许用户在推理阶段为多个目标分配自定义权重,以满足个性化的视频质量需求。
3、性能优势:VideoReward 在多个实验中表现优于现有的奖励模型。例如,Flow-DPO 和 Flow-WRR 在标准微调方法中展现了更高的性能,而 Flow-NRG 则提供了更灵活的控制能力,使用户可以根据具体需求调整生成视频的质量。
4、人类反馈驱动:该模型利用大规模人类偏好数据集,通过成对标注的方式,直接从人类反馈中学习,从而优化视频生成。
5、强化学习优化:从统一的强化学习视角出发,VideoReward通过KL正则化最大化奖励,引入了三种对齐算法(Flow-DPO、Flow-RWR和Flow-NRG),分别用于训练和推理阶段。
VideoReward应用场景:
VideoReward主要用于视频生成模型的优化,能够显著提升视频生成的质量和用户满意度。它适用于需要高质量视频生成的场景,如内容创作、广告制作、教育视频等,能够帮助生成更加流畅、对齐良好的视频内容。
VideoReward项目网址:
1、项目官网:https://gongyeliu.github.io/videoalign/
2、arXiv技术论文:https://arxiv.org/pdf/2501.13918
标签:

基金从业资格考试题库
一站式备考基金从业资格考试,收录2021-2025年模拟题库!
 盘点亚马逊各国销售榜网址汇总
盘点亚马逊各国销售榜网址汇总 Fruugo北美跨境电商平台(盘点Fruugo北美跨境电商登录网址)
Fruugo北美跨境电商平台(盘点Fruugo北美跨境电商登录网址) Qwen3大模型系列合集,覆盖多个领域!
Qwen3大模型系列合集,覆盖多个领域! 亚马逊全球网点布局大盘点(包括所有开店流程)
亚马逊全球网点布局大盘点(包括所有开店流程) eMAG全球3大国际站大盘点
eMAG全球3大国际站大盘点 美客多全球6大国际站大盘点
美客多全球6大国际站大盘点 Seed-TTS:字节跳动开发的高质量、多功能的文本到语音(TTS)模型
Seed-TTS:字节跳动开发的高质量、多功能的文本到语音(TTS)模型 一个由谷歌提出的一种多智能体协作框架—— CoA
一个由谷歌提出的一种多智能体协作框架—— CoA Comfy UI入门教程:AI绘画工作流ComfyUI搭建步骤
Comfy UI入门教程:AI绘画工作流ComfyUI搭建步骤 互联网最火的10个大语言模型及其应用场景全解析
互联网最火的10个大语言模型及其应用场景全解析 免费AI数据分析神器:一键生成可视化图表,轻松搞定复杂数据
免费AI数据分析神器:一键生成可视化图表,轻松搞定复杂数据热门工具
 EndlessVN
EndlessVN AIBox365
AIBox365 roop
roop Job In Corner
Job In Corner 爱改写
爱改写热门标签
AI提示词国产AIAI办公工具生活服务浏览器插件电影下载音频工具AIGCppt模板软件资源实用工具ai换脸短剧资源AI办公效率AI大模型