Aligner:一款由北京大学团队推出的残差修正模型对齐技术
Aligner是由北京大学团队提出的一种大语言模型对齐技术,旨在通过学习对齐答案与未对齐答案之间的修正残差来提升模型性能。它采用自回归的seq2seq模型,在问题-答案-修正后的答案(Query-Answer-Correction, Q-A-C)数据集上训练,无需依赖复杂的强化学习从人类反馈(RLHF)流程。
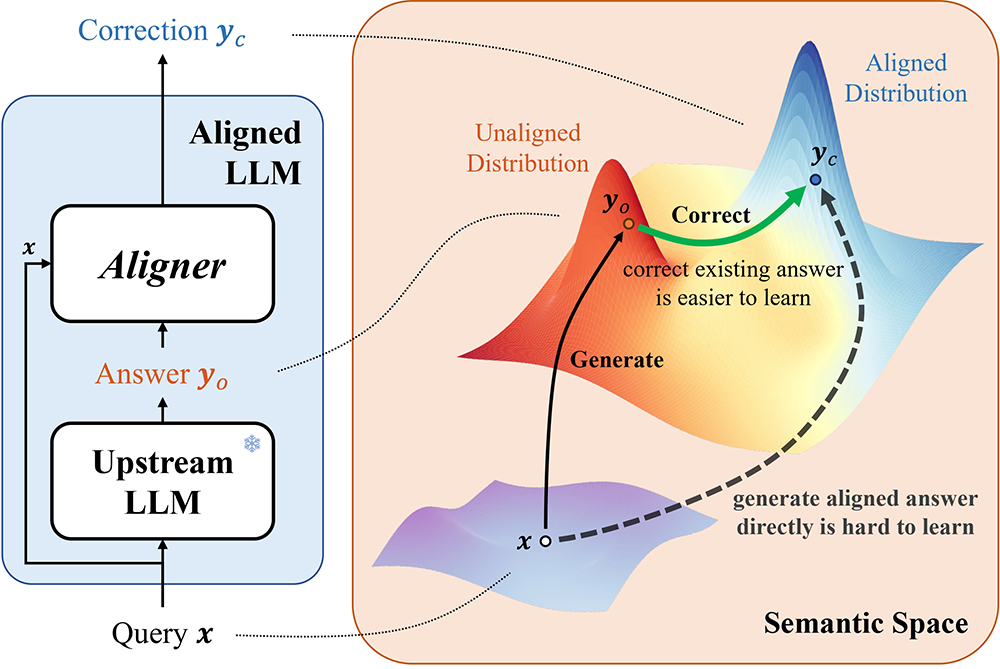
Aligner功能特点:
1、修正残差学习:Aligner通过学习对齐与未对齐答案之间的差异,实现更精准的模型对齐。
2、弱到强泛化:使用小参数量的Aligner模型对大参数量的LLMs进行微调,可以显著提升强模型的性能。
3、即插即用:Aligner可以直接应用于各种开源和基于API的模型,无需访问模型参数。
4、高效训练:Aligner的训练过程简洁高效,计算资源需求主要受对齐目标影响,而不受原始模型规模的制约。
5、多模型兼容性:Aligner-7B对齐提升了包括闭源、开源及安全/未安全对齐模型在内的11种模型的帮助性和安全性。
6、定向修正:通过引入外部指令反馈,Aligner可以在对齐器推理时,针对特定维度进行优化,提升在帮助性、无害性和同理心等多个维度上的修正效果。
Aligner的优点:
1、高效性:Aligner的实现简洁高效,无需复杂的RLHF流程,计算资源需求低。
2、灵活性:作为即插即用的模块,Aligner可以应用于各种模型,无需访问模型参数。
3、显著性能提升:实验表明,Aligner能显著提升模型的帮助性和安全性,例如在GPT-4模型中,帮助性提高了17.5%,安全性提升了26.9%。
4、多模型兼容:Aligner能够对齐多种类型的模型,包括闭源、开源及安全/未安全对齐模型。
5、定向优化:支持通过外部指令反馈进行定向修正,提升特定维度的性能。
Aligner的缺点:
1、依赖高质量数据:Aligner的性能依赖于高质量的Q-A-C数据集,数据质量直接影响对齐效果。
2、适用范围有限:虽然Aligner在提升模型帮助性和安全性方面表现出色,但在某些特定任务或领域中,可能需要进一步优化。
3、训练成本:尽管计算资源需求较低,但训练Aligner仍需要一定的数据收集和处理成本。
Aligner的项目地址:
项目官网:https://pku-aligner.github.io/
GitHub仓库:https://github.com/PKU-Alignment/aligner
HuggingFace模型库:https://huggingface.co/aligner/aligner-7b-v1.0
arXiv技术论文:https://arxiv.org/pdf/2402.02416
Aligner的应用场景:
1、多轮对话场景:
在多轮对话中,Aligner可以显著改善对话的对齐效果,尤其是在稀疏奖励的挑战下。例如,在问答式对话(QA)中,通常只有在对话结束时才能获得标量形式的监督信号,这种稀疏性在多轮对话中会进一步放大,导致基于强化学习的人类反馈(RLHF)难以发挥效果。Aligner通过学习修正残差,能够有效改善这一问题。
2、人类价值向奖励模型的对齐:
Aligner可以通过特定语料训练,修正前置模型的输出以反映特定的价值观。例如,在构建基于人类偏好的奖励模型和大型语言模型(LLMs)微调的多阶段过程中,Aligner能够确保LLMs与特定的人类价值(如公平性、共情等)对齐。
3、混合专家(MoE)Aligner的流式化和并行处理:
通过将Aligner专门化处理并集成,可以创建更强大且全面的混合专家(MoE)Aligner,这种Aligner能够满足多重混合安全及价值对齐需求。同时,进一步提高Aligner的并行处理能力,以减少推理时间的损耗,是一个可行的发展方向。
4、弱到强泛化:
Aligner可以利用小参数量的模型对大参数量的LLMs进行微调,从而显著提升强模型的性能。例如,使用Aligner-13B监督微调Llama2-70B,帮助性和安全性分别提升了8.2%和61.6%。
5、提升模型的安全性和帮助性:
实验表明,使用Aligner-7B能够显著提高GPT-4的帮助性和安全性,分别增加了17.5%和26.9%。
6、机器翻译研究:
虽然Aligner的主要应用场景集中在语言模型对齐,但其技术原理也可以应用于机器翻译领域。例如,通过学习修正残差,Aligner可以优化翻译模型的输出,提升翻译质量。
标签:

基金从业资格考试题库
一站式备考基金从业资格考试,收录2021-2025年模拟题库!
 盘点亚马逊各国销售榜网址汇总
盘点亚马逊各国销售榜网址汇总 Fruugo北美跨境电商平台(盘点Fruugo北美跨境电商登录网址)
Fruugo北美跨境电商平台(盘点Fruugo北美跨境电商登录网址) Qwen3大模型系列合集,覆盖多个领域!
Qwen3大模型系列合集,覆盖多个领域! 亚马逊全球网点布局大盘点(包括所有开店流程)
亚马逊全球网点布局大盘点(包括所有开店流程) eMAG全球3大国际站大盘点
eMAG全球3大国际站大盘点 美客多全球6大国际站大盘点
美客多全球6大国际站大盘点 Seed-TTS:字节跳动开发的高质量、多功能的文本到语音(TTS)模型
Seed-TTS:字节跳动开发的高质量、多功能的文本到语音(TTS)模型 Comfy UI入门教程:AI绘画工作流ComfyUI搭建步骤
Comfy UI入门教程:AI绘画工作流ComfyUI搭建步骤 一个由谷歌提出的一种多智能体协作框架—— CoA
一个由谷歌提出的一种多智能体协作框架—— CoA 免费AI数据分析神器:一键生成可视化图表,轻松搞定复杂数据
免费AI数据分析神器:一键生成可视化图表,轻松搞定复杂数据 互联网最火的10个大语言模型及其应用场景全解析
互联网最火的10个大语言模型及其应用场景全解析热门工具
 EndlessVN
EndlessVN 爱改写
爱改写 AIBox365
AIBox365 roop
roop Job In Corner
Job In Corner热门标签
短剧搜索自学OCR识别媒体运营mac软件下载AI头像绘制在线学习平台二手交易教师必备ChatGPTAI数字虚拟人影视资源投诉举报查询检测谷歌插件