一款支持从 1000 万到 4050 亿参数的模型训练——Oumi
Oumi.ai是一个由顶尖高校支持的初创公司开发的开源人工智能平台,旨在通过提供开放访问基础模型、数据集和开发工具,打造一个协作式的 AI 研发生态系统。
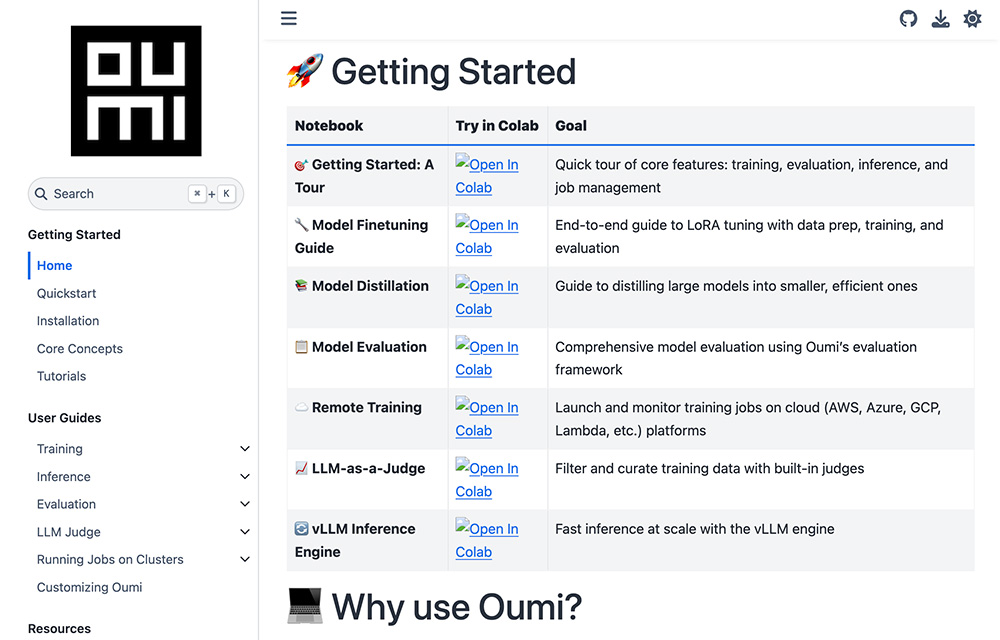
Oumi的功能特点:
1、开放性和协作性:
完全开源:Oumi 平台以 Apache 2.0 许可证形式开源,开发者可以将其用于研究和商业用途。
无条件开放:提供模型代码、权重和训练数据,确保 AI 模型和研究完全可访问、可复制且可由任何人修改。
社区驱动:作为一个开源社区,Oumi 鼓励开发者参与贡献,共同推动 AI 的发展。
2、灵活性和可扩展性:
支持多种模型:支持从 1000 万到 4050 亿参数的模型训练,涵盖文本和多模态模型,如 Llama、Qwen 和 Phi。
多种部署环境:用户可以在从个人笔记本电脑到超大规模云平台(如 AWS、Azure、GCP)的各种环境中运行模型。
灵活的接口:提供一致的 API,便于开发者在不同环境中无缝切换。
3、功能强大:
高级训练技术:支持监督式微调(SFT)、低秩适应(LoRA)、量化低秩适应(QLoRA)和直接性能优化(DPO)等技术。
数据合成与整理:内置工具可使用大语言模型评判器合成和整理训练数据。
模型评估与部署:支持通过流行的推理引擎(如 vLLM 和 SGLang)部署模型,并通过标准 AI 基准评估模型。
4、企业级支持:
企业级可靠性:平台经过大规模模型训练团队的验证,具备企业级的稳定性和可靠性。
定制化解决方案:为企业提供定制化的 AI 解决方案,包括预训练、微调和评估。
5、使命与愿景:
打破创新壁垒:Oumi 致力于打破当前 AI 研究领域的创新壁垒,加速 AI 领域的进展和发现。
推动 AI 的普及化:通过开放和协作的方式,让 AI 技术更加普及,降低 AI 研究和开发的门槛。
Oumi支持哪些模型训练?
1、支持的模型类型:
文本模型:支持从 1000 万到 4050 亿参数的文本模型训练。
多模态模型:支持多模态模型的训练与部署,例如 Llama、Qwen 和 Phi 等。
2、支持的训练技术:
监督式微调(SFT):用于将预训练模型适应特定任务。
低秩适应(LoRA):通过添加低秩适配器进行高效微调。
量化低秩适应(QLoRA):结合量化技术进行微调,支持 4 位精度。
直接性能优化(DPO):基于偏好进行微调。
3、支持的模型参数范围:
Oumi.ai 支持从 1000 万到 4050 亿参数的模型训练。
4、支持的模型架构:
Oumi.ai 支持多种流行的模型架构,包括但不限于 Llama、Qwen、Phi 等。
5、支持的训练环境:
本地环境:支持在个人笔记本电脑或本地机器上进行训练。
多 GPU 环境:支持多 GPU 和多节点分布式训练。
云端环境:支持在 AWS、Azure、GCP 等云平台上运行。
Oumi.ai 提供了强大的灵活性和可扩展性,能够满足从个人开发者到企业级用户的不同需求。
Oumi项目地址:
项目官网:https://oumi.ai/
GitHub仓库:https://github.com/oumi-ai/oumi
Oumi项应用场景:
1、自动驾驶:可以用于自动驾驶领域,通过融合图像、雷达和声纳等传感器数据,实现全方位的环境感知和障碍物检测。这种多模态数据处理能力能够帮助自动驾驶系统更准确地理解复杂的交通场景。
2、人机交互:支持结合语音、图像和文本信息,实现更自然、智能的人机交互方式。例如,在智能语音助手、智能客服等领域,Oumi.ai 可以提供强大的语言理解和生成能力。
3、学术研究:为研究人员提供了快速进行实验和模型开发的工具,确保实验的可复现性。研究人员可以利用其零样板代码(Zero Boilerplate)的开发体验,快速搭建和训练模型。
4、虚拟现实与增强现实:可以提升虚拟现实(VR)和增强现实(AR)应用的用户体验。例如,生成更真实的虚拟场景、动态交互等内容。
5、智能客服:在可以提供智能客服服务,通过自然语言处理技术理解用户问题并提供准确的回答,从而提升用户满意度。
6、企业级应用:提供企业级的定制化模型开发和安全可靠的 AI 解决方案。企业可以利用其强大的训练和部署能力,开发适合自身业务需求的 AI 模型。
7、数据合成与管理:支持通过大语言模型评判器合成和整理训练数据,这在数据稀缺或需要高质量数据的场景中非常有用。
8、模型评估与部署:支持通过流行的推理引擎(如 vLLM、SGLang)高效部署模型,并通过标准 AI 基准全面评估模型性能。
标签:

基金从业资格考试题库
一站式备考基金从业资格考试,收录2021-2025年模拟题库!
 盘点亚马逊各国销售榜网址汇总
盘点亚马逊各国销售榜网址汇总 Fruugo北美跨境电商平台(盘点Fruugo北美跨境电商登录网址)
Fruugo北美跨境电商平台(盘点Fruugo北美跨境电商登录网址) Qwen3大模型系列合集,覆盖多个领域!
Qwen3大模型系列合集,覆盖多个领域! 亚马逊全球网点布局大盘点(包括所有开店流程)
亚马逊全球网点布局大盘点(包括所有开店流程) eMAG全球3大国际站大盘点
eMAG全球3大国际站大盘点 美客多全球6大国际站大盘点
美客多全球6大国际站大盘点 一个由谷歌提出的一种多智能体协作框架—— CoA
一个由谷歌提出的一种多智能体协作框架—— CoA Comfy UI入门教程:AI绘画工作流ComfyUI搭建步骤
Comfy UI入门教程:AI绘画工作流ComfyUI搭建步骤 Seed-TTS:字节跳动开发的高质量、多功能的文本到语音(TTS)模型
Seed-TTS:字节跳动开发的高质量、多功能的文本到语音(TTS)模型 互联网最火的10个大语言模型及其应用场景全解析
互联网最火的10个大语言模型及其应用场景全解析 免费AI数据分析神器:一键生成可视化图表,轻松搞定复杂数据
免费AI数据分析神器:一键生成可视化图表,轻松搞定复杂数据热门工具
 AIBox365
AIBox365 Job In Corner
Job In Corner EndlessVN
EndlessVN roop
roop 爱改写
爱改写热门标签
查询检测AI效率提升AI办公工具AI头像绘制文字工具实用工具游戏平台3D模型学术论文AI语言翻译影音娱乐mac软件下载音频工具平台培训AI三维生成