PlanningBench – 腾讯混元 × 人大高瓴AI学院联合开源 大模型规划能力评测 & 训练框架
PlanningBench由腾讯混元团队联合中国人民大学高瓴人工智能学院等单位联合研发开源,聚焦大语言模型规划能力的评测与定向训练。项目立足现实业务场景,搭建覆盖6大品类、30+细分任务的可验证规划数据集生成架构,依托约束驱动闭环生成方案,推动大模型规划输出从“逻辑看似合理”升级为“落地可核验、全约束合规”。

一、核心技术原理:
1、实景抽象+三级约束架构:
多名行业规划专家与算法研究员联合梳理通勤排班、工厂排产、医疗应急等真实业务,提炼标准化任务结构,划分日程排期、资源匹配、人力排班、路线规划、生产运维、应急调度六大任务类目、30余项细分场景。
约束体系划分为三级:基础约束聚焦时间窗口、资源上限等硬性准入规则;中级约束叠加多目标优化、工序依赖、负载均衡;高阶约束面向异常容错、冲突消解、不可行场景甄别,所有任务、约束模块化自由组合,标准化数据生成空间。
2、G-R-C闭环数据生成机制:
框架采用Generator、Responder、Critic三段式闭环生成引擎:
- Generator:抽取任务与约束组合,自动生成完整规划题干+配套校验清单;
- Responder:调用模型生成对应规划方案;
- Critic:依据校验清单逐项核验全约束达标情况。
若模型可完整通关全部约束,系统自动上调后续生成任务的约束复杂度;若无法全量满足,则保留为高难度测试样本,动态探测大模型规划能力边界。
3、精细化难度分层逻辑:
摒弃依靠增加文本长度抬升难度的粗放模式,从任务架构、约束密集度、资源稀缺度、目标冲突、任务依赖、异常扰动六大维度调控难度,依托三级约束池采样比例动态调整样本复杂度,精准控制推理门槛。
二、产品核心功能:
1、全场景任务覆盖:
落地6大类、30+真实规划场景,横跨个人生活、企业生产、公共服务多领域。
2、三级约束可控生成:
基础/中级/高阶约束自由选配,按需定制不同难度数据集。
3、双指标自动化评测:
配套标准化核验清单,支持All-pass(全约束达标率)、Avg-pass(单项约束平均通过率)双维度量化打分。
4、闭环自适应造数:
GRC闭环自动迭代样本难度,持续扩充高挑战性评测数据。
5、原生适配强化学习:
可校验样本直接作为奖励数据,用于GRPO等强化学习微调,优化模型通用规划能力。
三、产品核心优势:
1、结果可量化核验:
配套标准化Checklist,客观判定方案全局可行性,规避主观打分偏差。
2、难度科学化调控:
以约束结构定义难度,贴合现实规划的复杂逻辑,区别于同类靠文本扩容的基准集。
3、精准定位模型短板:
双指标拆解模型问题,精准揪出“局部合规、全局矛盾”的典型规划缺陷(如资源超限、工期冲突)。
4、优异跨域迁移能力:
仅需300条标注样本做强化训练,即可显著提升模型在域外规划基准、通用指令跟随任务的效果。
5、场景落地性强:
全部任务源自真实业务,有效防止模型在固定测试集过拟合,适配产业落地验证。
四、快速使用指南:
1、资源拉取:
GitHub克隆项目代码,或在HuggingFace平台下载官方数据集;
2、模型评测:
导入评测集,接入待测大模型生成规划内容,依托内置清单自动计算双维度得分;
3、自定义数据集生成:
选定任务类目与约束等级,启动GRC闭环,批量生成定制领域、指定难度的训练数据;
4、模型微调训练:
使用框架产出的可验证样本搭建奖励信号,通过强化学习优化模型规划能力,实现下游任务泛化提升。
五、落地应用场景:
1、大模型能力测评:
定位模型在资源分配、时序跟踪、多约束统筹等规划模块的性能短板;
2、智能体专项训练:
为调度类Agent提供高质量训练数据,优化日程、物流、排班类任务落地稳定性;
3、AI学术科研:
标准化开源基准,用于大模型规划方向的对照实验与成果复现;
4、企业落地验证:
按需生成护士排班、工厂排产等行业定制数据集,检验大模型产业落地可行性;
5、资源分配算法验证:
依托分组、物资派发类任务,测评模型在多约束下的资源分配公平性与最优解求解能力。
六、项目资源地址:
1、GitHub开源仓库:https://github.com/Tencent-Hunyuan/PlanningBench
2、HuggingFace数据集:https://huggingface.co/datasets/tencent/PlanningBench
3、学术论文入口:https://arxiv.org/pdf/2605.20873
标签:

 AGenUI模型 - 高德地图联合阿里千问C端开源的原生A2UI框架
AGenUI模型 - 高德地图联合阿里千问C端开源的原生A2UI框架 Mavis官网 - MiniMax Agent推出的多智能体协同工作模式
Mavis官网 - MiniMax Agent推出的多智能体协同工作模式 Xiaomi OneVL - 小米具身智能团队自研的开源自动驾驶大模型
Xiaomi OneVL - 小米具身智能团队自研的开源自动驾驶大模型 CopilotKit – 开源AI原生应用前端操作系统
CopilotKit – 开源AI原生应用前端操作系统 PlanningBench – 腾讯混元 × 人大高瓴AI学院联合开源 大模型规划能力评测 & 训练框架
PlanningBench – 腾讯混元 × 人大高瓴AI学院联合开源 大模型规划能力评测 & 训练框架 BrowserAct Skills – 面向AI Agent的浏览器自动化CLI工具
BrowserAct Skills – 面向AI Agent的浏览器自动化CLI工具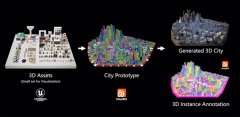 CityDreamer4D:南洋理工大学S-Lab团队开发的一个无边界4D城市建模框架
CityDreamer4D:南洋理工大学S-Lab团队开发的一个无边界4D城市建模框架 Goku:香港大学与字节跳动合作推出的一款AI视频生成模型
Goku:香港大学与字节跳动合作推出的一款AI视频生成模型 Fruugo北美跨境电商平台(盘点Fruugo北美跨境电商登录网址)
Fruugo北美跨境电商平台(盘点Fruugo北美跨境电商登录网址) 5个免费AI漫画生成工具,一键开启漫画创作之旅!
5个免费AI漫画生成工具,一键开启漫画创作之旅! 目前国内最火好用的ai视频软件有哪些 2025流行的AI视频软件排行榜
目前国内最火好用的ai视频软件有哪些 2025流行的AI视频软件排行榜 8款热门AI绘画工具,国内外免费资源,轻松创作艺术佳作!
8款热门AI绘画工具,国内外免费资源,轻松创作艺术佳作!热门工具
 SmallPPT
SmallPPT Promethean
Promethean UPDF
UPDF 阿里云数字人
阿里云数字人 Blender免费开源3D创作套件
Blender免费开源3D创作套件热门标签
UI组件库文字工具软件工具大语言模型在线漫画实用工具自学法律咨询小说文学思维导图在线学习平台AI数字虚拟人ChatGPTAI内容检测办公软件