LalaEval:香港中文大学和货拉拉团队共同推出的一个LLMs的人工评估框架
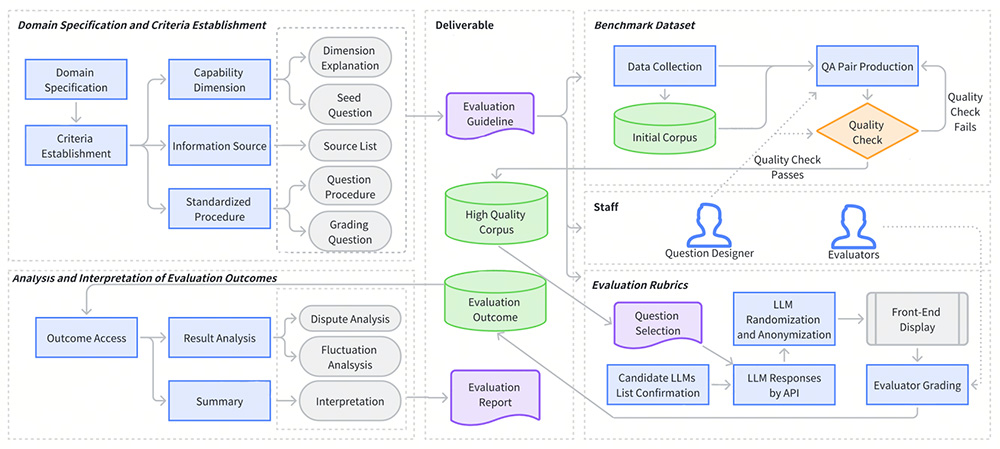
LalaEval 是由香港中文大学和货拉拉数据科学团队共同推出的一个面向特定领域大语言模型(LLMs)的人工评估框架。该框架通过一套完整的端到端协议,涵盖领域规范、标准建立、基准数据集创建、评估规则构建以及评估结果的分析和解释。LalaEval 核心特点是通过争议度和评分波动分析,自动纠正人工主观错误,生成高质量的问答对。
LalaEval功能特点:
1、端到端评估流程:
明确特定领域的范围和边界,与组织的目标或业务需求相关。
定义评估 LLMs 性能的能力维度,包括通用能力和领域能力。
开发标准化测试并从经过审查的信息源中收集数据。
设计详细的评分方案,为人类评估者提供结构化框架。
通过评分争议度、题目争议度、评分波动性等分析框架,自动化实现评分结果质检。
2、单盲测试原理:在评估过程中,模型的响应被匿名化并以随机顺序呈现给至少三名人类评估者,确保评分的客观性和公正性。
3、争议度和评分波动分析:自动检测和纠正人工评分中的主观性错误。
4、动态交互的部署结构:强调模块化和动态交互,能根据不同的业务场景灵活调整评估流程。
LalaEval的优点:
1、标准化评估:提供了一套标准化的评估流程,减少人工主观性。
2、高质量数据生成:能够动态生成高质量的问答对,指导领域大模型的构建和迭代优化。
3、客观公正:采用单盲测试原理,确保评分的客观性和公正性。
4、高可扩展性:设计遵循模块化和动态交互原则,能灵活扩展到其他领域。
5、自动化分析:通过争议度和评分波动分析,自动纠正人工主观错误。
LalaEval的缺点:
1、评估成本较高:人工评估过程需要投入一定的人力和时间。
2、领域依赖性:虽然具有一定的扩展性,但主要针对特定领域(如物流)设计,其他领域可能需要额外的适配。
3、数据需求:需要高质量的基准数据集来支持评估,数据收集和整理可能较为复杂。
LalaEval的项目地址:
arXiv 技术论文:https://arxiv.org/pdf/2408.13338
LalaEval应用场景:
1、物流领域大模型评估:针对同城货运等具体业务场景,评估大语言模型在物流行业的表现。
2、邀约大模型的评测:在司机邀约场景中,评估大模型在自动邀约任务中的表现。
3、企业内部大模型的定制与优化:为企业提供标准化的评估方法,根据企业自身的业务需求动态生成评测集。
4、跨领域应用的扩展性:设计遵循模块化和动态交互原则,能灵活扩展到其他领域。
标签:

基金从业资格考试题库
一站式备考基金从业资格考试,收录2021-2025年模拟题库!
 盘点亚马逊各国销售榜网址汇总
盘点亚马逊各国销售榜网址汇总 Fruugo北美跨境电商平台(盘点Fruugo北美跨境电商登录网址)
Fruugo北美跨境电商平台(盘点Fruugo北美跨境电商登录网址) Qwen3大模型系列合集,覆盖多个领域!
Qwen3大模型系列合集,覆盖多个领域! 亚马逊全球网点布局大盘点(包括所有开店流程)
亚马逊全球网点布局大盘点(包括所有开店流程) eMAG全球3大国际站大盘点
eMAG全球3大国际站大盘点 美客多全球6大国际站大盘点
美客多全球6大国际站大盘点 Seed-TTS:字节跳动开发的高质量、多功能的文本到语音(TTS)模型
Seed-TTS:字节跳动开发的高质量、多功能的文本到语音(TTS)模型 Comfy UI入门教程:AI绘画工作流ComfyUI搭建步骤
Comfy UI入门教程:AI绘画工作流ComfyUI搭建步骤 一个由谷歌提出的一种多智能体协作框架—— CoA
一个由谷歌提出的一种多智能体协作框架—— CoA 免费AI数据分析神器:一键生成可视化图表,轻松搞定复杂数据
免费AI数据分析神器:一键生成可视化图表,轻松搞定复杂数据 互联网最火的10个大语言模型及其应用场景全解析
互联网最火的10个大语言模型及其应用场景全解析热门工具
 AIBox365
AIBox365 Job In Corner
Job In Corner roop
roop EndlessVN
EndlessVN 爱改写
爱改写热门标签
在线学习平台AIGC在线教育平台在线短剧mac软件下载创意设计办公提效电影资源SQL语句电子书生活服务影音娱乐教师必备AI大模型资源服务平台